 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Data Augmentation for Acoustic-to-articulatory Speech Inversion using Bidirectional Gated RNNs
Paper and Code

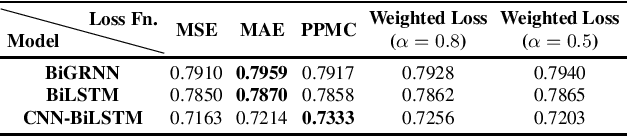
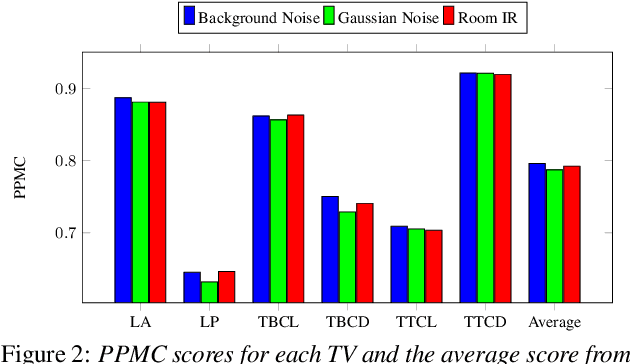
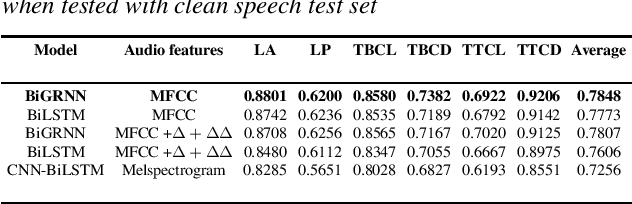
Data augmentation has proven to be a promising prospect in improving the performance of deep learning models by adding variability to training data. In previous work with developing a noise robust acoustic-to-articulatory speech inversion system, we have shown the importance of noise augmentation to improve the performance of speech inversion in noisy speech. In this work, we compare and contrast different ways of doing data augmentation and show how this technique improves the performance of articulatory speech inversion not only on noisy speech, but also on clean speech data. We also propose a Bidirectional Gated Recurrent Neural Network as the speech inversion system instead of the previously used feed forward neural network. The inversion system uses mel-frequency cepstral coefficients (MFCCs) as the input acoustic features and six vocal tract-variables (TVs) as the output articulatory features. The Performance of the system was measured by computing the correlation between estimated and actual TVs on the U. Wisc. X-ray Microbeam database. The proposed speech inversion system shows a 5% relative improvement in correlation over the baseline noise robust system for clean speech data. The pre-trained model, when adapted to each unseen speaker in the test set, improves the average correlation by another 6%.