 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorize Early, Integrate Late: Divergent Processing Strategies in Automatic Speech Recognition
Jan 11, 2026In speech language modeling, two architectures dominate the frontier: the Transformer and the Conformer. However, it remains unknown whether their comparable performance stems from convergent processing strategies or distinct architectural inductive biases. We introduce Architectural Fingerprinting, a probing framework that isolates the effect of architecture on representation, and apply it to a controlled suite of 24 pre-trained encoders (39M-3.3B parameters). Our analysis reveals divergent hierarchies: Conformers implement a "Categorize Early" strategy, resolving phoneme categories 29% earlier in depth and speaker gender by 16% depth. In contrast, Transformers "Integrate Late," deferring phoneme, accent, and duration encoding to deep layers (49-57%). These fingerprints suggest design heuristics: Conformers' front-loaded categorization may benefit low-latency streaming, while Transformers' deep integration may favor tasks requiring rich context and cross-utterance normalization.
Multi-Stage Speaker Diarization for Noisy Classrooms
May 16, 2025Speaker diarization, the process of identifying "who spoke when" in audio recordings, is essential for understanding classroom dynamics. However, classroom settings present distinct challenges, including poor recording quality, high levels of background noise, overlapping speech, and the difficulty of accurately capturing children's voices. This study investigates the effectiveness of multi-stage diarization models using Nvidia's NeMo diarization pipeline. We assess the impact of denoising on diarization accuracy and compare various voice activity detection (VAD) models, including self-supervised transformer-based frame-wise VAD models. We also explore a hybrid VAD approach that integrates Automatic Speech Recognition (ASR) word-level timestamps with frame-level VAD predictions. We conduct experiments using two datasets from English speaking classrooms to separate teacher vs. student speech and to separate all speakers. Our results show that denoising significantly improves the Diarization Error Rate (DER) by reducing the rate of missed speech. Additionally, training on both denoised and noisy datasets leads to substantial performance gains in noisy conditions. The hybrid VAD model leads to further improvements in speech detection, achieving a DER as low as 17% in teacher-student experiments and 45% in all-speaker experiments. However, we also identified trade-offs between voice activity detection and speaker confusion. Overall, our study highlights the effectiveness of multi-stage diarization models and integrating ASR-based information for enhancing speaker diarization in noisy classroom environments.
Continued Pretraining for Domain Adaptation of Wav2vec2.0 in Automatic Speech Recognition for Elementary Math Classroom Settings
May 15, 2024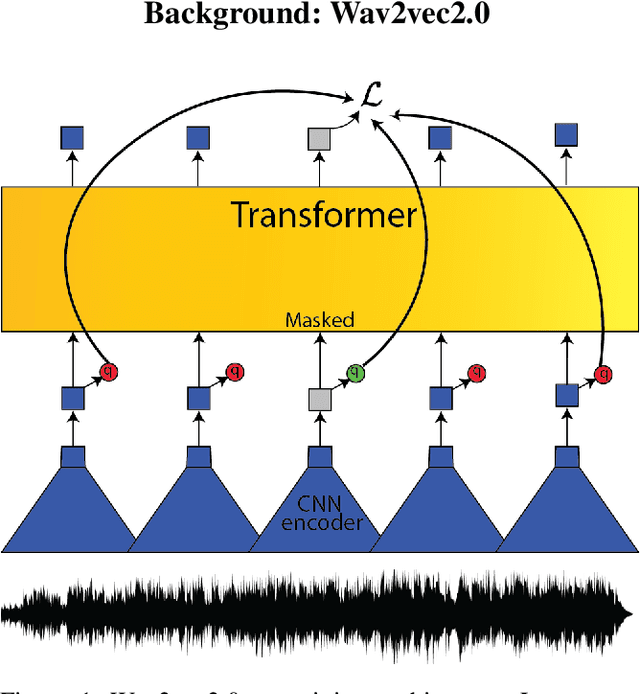
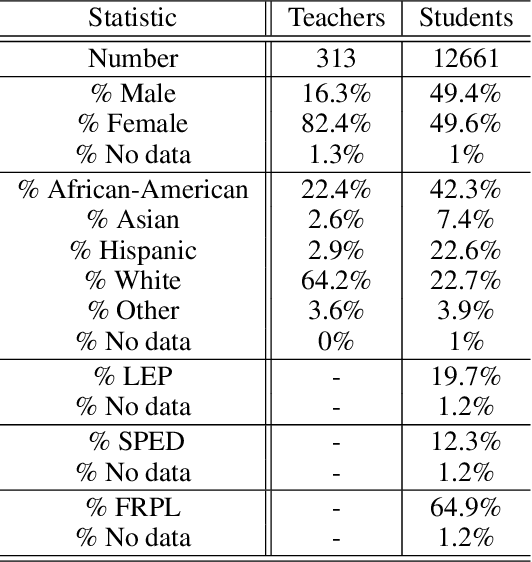
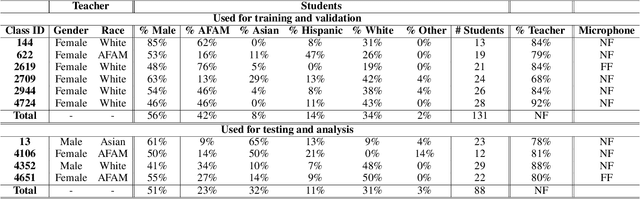
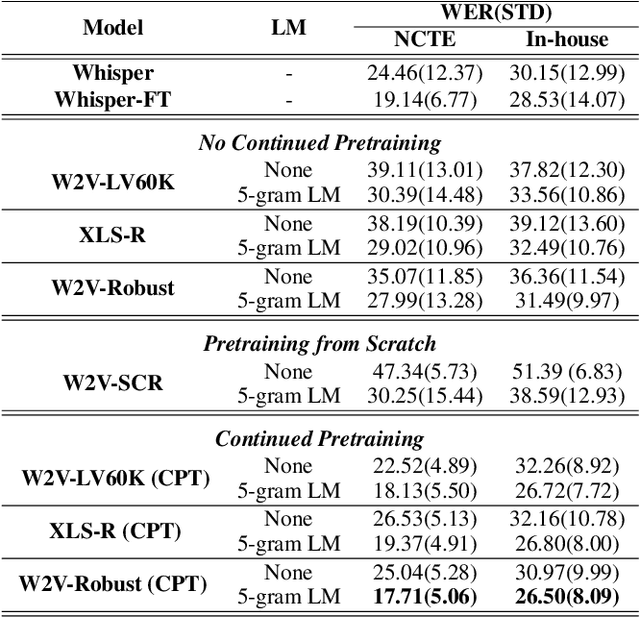
Creating Automatic Speech Recognition (ASR) systems that are robust and resilient to classroom conditions is paramount to the development of AI tools to aid teachers and students. In this work, we study the efficacy of continued pretraining (CPT) in adapting Wav2vec2.0 to the classroom domain. We show that CPT is a powerful tool in that regard and reduces the Word Error Rate (WER) of Wav2vec2.0-based models by upwards of 10%. More specifically, CPT improves the model's robustness to different noises, microphones, classroom conditions as well as classroom demographics. Our CPT models show improved ability to generalize to different demographics unseen in the labeled finetuning data.
ÌròyìnSpeech: A multi-purpose Yorùbá Speech Corpus
Jul 29, 2023
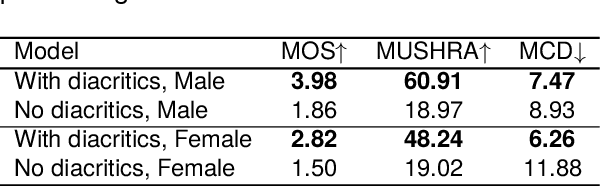
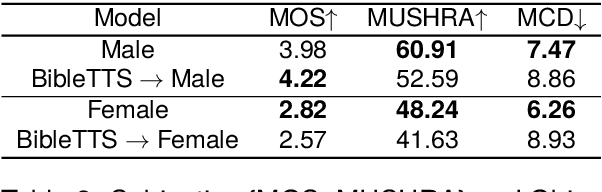
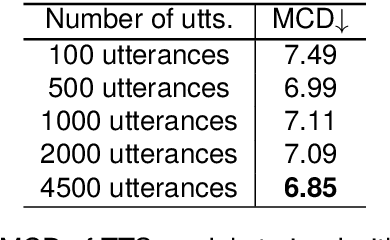
We introduce the \`{I}r\`{o}y\`{i}nSpeech corpus -- a new dataset influenced by a desire to increase the amount of high quality, freely available, contemporary Yor\`{u}b\'{a} speech. We release a multi-purpose dataset that can be used for both TTS and ASR tasks. We curated text sentences from the news and creative writing domains under an open license i.e., CC-BY-4.0 and had multiple speakers record each sentence. We provide 5000 of our utterances to the Common Voice platform to crowdsource transcriptions online. The dataset has 38.5 hours of data in total, recorded by 80 volunteers.
Ìtàkúròso: Exploiting Cross-Lingual Transferability for Natural Language Generation of Dialogues in Low-Resource, African Languages
Apr 17, 2022
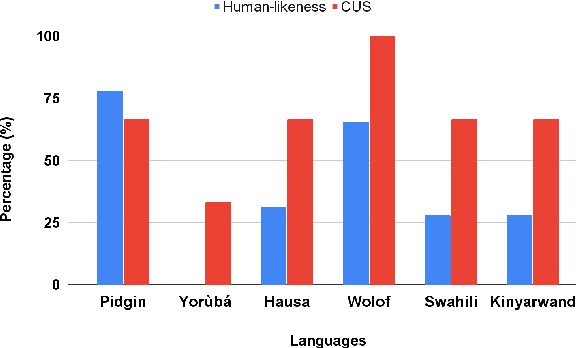
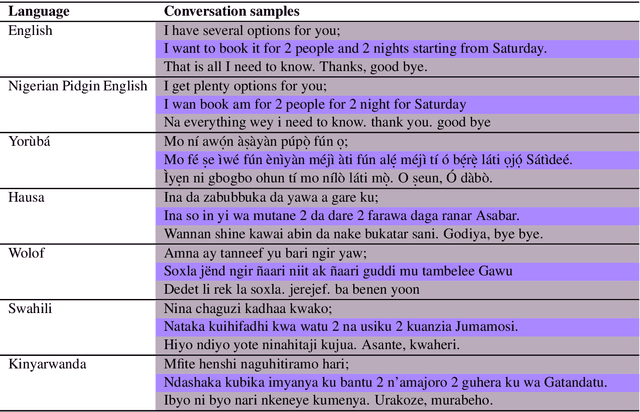
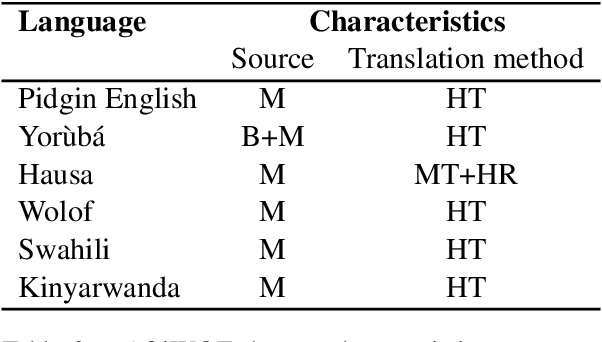
We investigate the possibility of cross-lingual transfer from a state-of-the-art (SoTA) deep monolingual model (DialoGPT) to 6 African languages and compare with 2 baselines (BlenderBot 90M, another SoTA, and a simple Seq2Seq). The languages are Swahili, Wolof, Hausa, Nigerian Pidgin English, Kinyarwanda & Yor\`ub\'a. Generation of dialogues is known to be a challenging task for many reasons. It becomes more challenging for African languages which are low-resource in terms of data. Therefore, we translate a small portion of the English multi-domain MultiWOZ dataset for each target language. Besides intrinsic evaluation (i.e. perplexity), we conduct human evaluation of single-turn conversations by using majority votes and measure inter-annotator agreement (IAA). The results show that the hypothesis that deep monolingual models learn some abstractions that generalise across languages holds. We observe human-like conversations in 5 out of the 6 languages. It, however, applies to different degrees in different languages, which is expected. The language with the most transferable properties is the Nigerian Pidgin English, with a human-likeness score of 78.1%, of which 34.4% are unanimous. The main contributions of this paper include the representation (through the provision of high-quality dialogue data) of under-represented African languages and demonstrating the cross-lingual transferability hypothesis for dialogue systems. We also provide the datasets and host the model checkpoints/demos on the HuggingFace hub for public access.