 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating LLM biases toward spurious social contexts using direct preference optimization
Apr 02, 2026LLMs are increasingly used for high-stakes decision-making, yet their sensitivity to spurious contextual information can introduce harmful biases. This is a critical concern when models are deployed for tasks like evaluating teachers' instructional quality, where biased assessment can affect teachers' professional development and career trajectories. We investigate model robustness to spurious social contexts using the largest publicly available dataset of U.S. classroom transcripts (NCTE) paired with expert rubric scores. Evaluating seven frontier and open-weight models across seven categories of spurious contexts -- including teacher experience, education level, demographic identity, and sycophancy-inducing framings -- we find that irrelevant contextual information can shift model predictions by up to 1.48 points on a 7-point scale, with larger models sometimes exhibiting greater sensitivity despite higher predictive accuracy. Mitigations using prompts and standard direct preference optimization (DPO) prove largely insufficient. We propose **Debiasing-DPO**,, a self-supervised training method that pairs neutral reasoning generated from the query alone, with the model's biased reasoning generated with both the query and additional spurious context. We further combine this objective with supervised fine-tuning on ground-truth labels to prevent losses in predictive accuracy. Applied to Llama 3B \& 8B and Qwen 3B \& 7B Instruct models, Debiasing-DPO reduces bias by 84\% and improves predictive accuracy by 52\% on average. Our findings from the educational case study highlight that robustness to spurious context is not a natural byproduct of model scaling and that our proposed method can yield substantial gains in both accuracy and robustness for prompt-based prediction tasks.
Marked Pedagogies: Examining Linguistic Biases in Personalized Automated Writing Feedback
Mar 12, 2026Effective personalized feedback is critical to students' literacy development. Though LLM-powered tools now promise to automate such feedback at scale, LLMs are not language-neutral: they privilege standard academic English and reproduce social stereotypes, raising concerns about how "personalization" shapes the feedback students receive. We examine how four widely used LLMs (GPT-4o, GPT-3.5-turbo, Llama-3.3 70B, Llama-3.1 8B) adapt written feedback in response to student attributes. Using 600 eighth-grade persuasive essays from the PERSUADE dataset, we generated feedback under prompt conditions embedding gender, race/ethnicity, learning needs, achievement, and motivation. We analyze lexical shifts across model outputs by adapting the Marked Words framework. Our results reveal systematic, stereotype-aligned shifts in feedback conditioned on presumed student attributes--even when essay content was identical. Feedback for students marked by race, language, or disability often exhibited positive feedback bias and feedback withholding bias--overuse of praise, less substantive critique, and assumptions of limited ability. Across attributes, models tailored not only what content was emphasized but also how writing was judged and how students were addressed. We term these instructional orientations Marked Pedagogies and highlight the need for transparency and accountability in automated feedback tools.
DiagramIR: An Automatic Pipeline for Educational Math Diagram Evaluation
Nov 11, 2025Large Language Models (LLMs) are increasingly being adopted as tools for learning; however, most tools remain text-only, limiting their usefulness for domains where visualizations are essential, such as mathematics. Recent work shows that LLMs are capable of generating code that compiles to educational figures, but a major bottleneck remains: scalable evaluation of these diagrams. We address this by proposing DiagramIR: an automatic and scalable evaluation pipeline for geometric figures. Our method relies on intermediate representations (IRs) of LaTeX TikZ code. We compare our pipeline to other evaluation baselines such as LLM-as-a-Judge, showing that our approach has higher agreement with human raters. This evaluation approach also enables smaller models like GPT-4.1-Mini to perform comparably to larger models such as GPT-5 at a 10x lower inference cost, which is important for deploying accessible and scalable education technologies.
TeachLM: Post-Training LLMs for Education Using Authentic Learning Data
Oct 06, 2025The promise of generative AI to revolutionize education is constrained by the pedagogical limits of large language models (LLMs). A major issue is the lack of access to high-quality training data that reflect the learning of actual students. Prompt engineering has emerged as a stopgap, but the ability of prompts to encode complex pedagogical strategies in rule-based natural language is inherently limited. To address this gap we introduce TeachLM - an LLM optimized for teaching through parameter-efficient fine-tuning of state-of-the-art models. TeachLM is trained on a dataset comprised of 100,000 hours of one-on-one, longitudinal student-tutor interactions maintained by Polygence, which underwent a rigorous anonymization process to protect privacy. We use parameter-efficient fine-tuning to develop an authentic student model that enables the generation of high-fidelity synthetic student-tutor dialogues. Building on this capability, we propose a novel multi-turn evaluation protocol that leverages synthetic dialogue generation to provide fast, scalable, and reproducible assessments of the dialogical capabilities of LLMs. Our evaluations demonstrate that fine-tuning on authentic learning data significantly improves conversational and pedagogical performance - doubling student talk time, improving questioning style, increasing dialogue turns by 50%, and greater personalization of instruction.
Tell, Don't Show: Leveraging Language Models' Abstractive Retellings to Model Literary Themes
May 29, 2025Conventional bag-of-words approaches for topic modeling, like latent Dirichlet allocation (LDA), struggle with literary text. Literature challenges lexical methods because narrative language focuses on immersive sensory details instead of abstractive description or exposition: writers are advised to "show, don't tell." We propose Retell, a simple, accessible topic modeling approach for literature. Here, we prompt resource-efficient, generative language models (LMs) to tell what passages show, thereby translating narratives' surface forms into higher-level concepts and themes. By running LDA on LMs' retellings of passages, we can obtain more precise and informative topics than by running LDA alone or by directly asking LMs to list topics. To investigate the potential of our method for cultural analytics, we compare our method's outputs to expert-guided annotations in a case study on racial/cultural identity in high school English language arts books.
From Weak Labels to Strong Results: Utilizing 5,000 Hours of Noisy Classroom Transcripts with Minimal Accurate Data
May 20, 2025Recent progress in speech recognition has relied on models trained on vast amounts of labeled data. However, classroom Automatic Speech Recognition (ASR) faces the real-world challenge of abundant weak transcripts paired with only a small amount of accurate, gold-standard data. In such low-resource settings, high transcription costs make re-transcription impractical. To address this, we ask: what is the best approach when abundant inexpensive weak transcripts coexist with limited gold-standard data, as is the case for classroom speech data? We propose Weakly Supervised Pretraining (WSP), a two-step process where models are first pretrained on weak transcripts in a supervised manner, and then fine-tuned on accurate data. Our results, based on both synthetic and real weak transcripts, show that WSP outperforms alternative methods, establishing it as an effective training methodology for low-resource ASR in real-world scenarios.
Multi-Stage Speaker Diarization for Noisy Classrooms
May 16, 2025Speaker diarization, the process of identifying "who spoke when" in audio recordings, is essential for understanding classroom dynamics. However, classroom settings present distinct challenges, including poor recording quality, high levels of background noise, overlapping speech, and the difficulty of accurately capturing children's voices. This study investigates the effectiveness of multi-stage diarization models using Nvidia's NeMo diarization pipeline. We assess the impact of denoising on diarization accuracy and compare various voice activity detection (VAD) models, including self-supervised transformer-based frame-wise VAD models. We also explore a hybrid VAD approach that integrates Automatic Speech Recognition (ASR) word-level timestamps with frame-level VAD predictions. We conduct experiments using two datasets from English speaking classrooms to separate teacher vs. student speech and to separate all speakers. Our results show that denoising significantly improves the Diarization Error Rate (DER) by reducing the rate of missed speech. Additionally, training on both denoised and noisy datasets leads to substantial performance gains in noisy conditions. The hybrid VAD model leads to further improvements in speech detection, achieving a DER as low as 17% in teacher-student experiments and 45% in all-speaker experiments. However, we also identified trade-offs between voice activity detection and speaker confusion. Overall, our study highlights the effectiveness of multi-stage diarization models and integrating ASR-based information for enhancing speaker diarization in noisy classroom environments.
Problem-Oriented Segmentation and Retrieval: Case Study on Tutoring Conversations
Nov 12, 2024



Many open-ended conversations (e.g., tutoring lessons or business meetings) revolve around pre-defined reference materials, like worksheets or meeting bullets. To provide a framework for studying such conversation structure, we introduce Problem-Oriented Segmentation & Retrieval (POSR), the task of jointly breaking down conversations into segments and linking each segment to the relevant reference item. As a case study, we apply POSR to education where effectively structuring lessons around problems is critical yet difficult. We present LessonLink, the first dataset of real-world tutoring lessons, featuring 3,500 segments, spanning 24,300 minutes of instruction and linked to 116 SAT math problems. We define and evaluate several joint and independent approaches for POSR, including segmentation (e.g., TextTiling), retrieval (e.g., ColBERT), and large language models (LLMs) methods. Our results highlight that modeling POSR as one joint task is essential: POSR methods outperform independent segmentation and retrieval pipelines by up to +76% on joint metrics and surpass traditional segmentation methods by up to +78% on segmentation metrics. We demonstrate POSR's practical impact on downstream education applications, deriving new insights on the language and time use in real-world lesson structures.
Continued Pretraining for Domain Adaptation of Wav2vec2.0 in Automatic Speech Recognition for Elementary Math Classroom Settings
May 15, 2024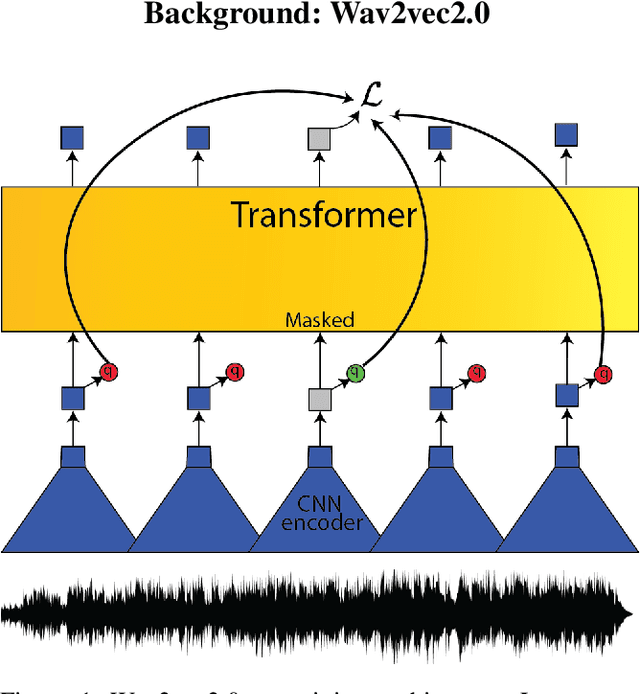
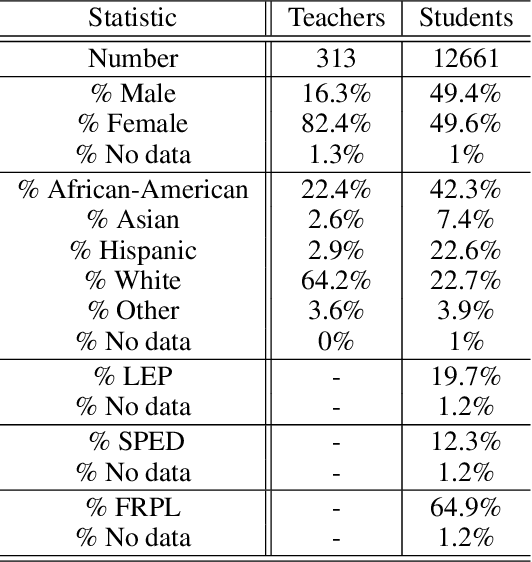
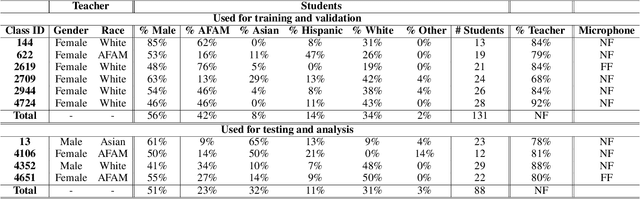
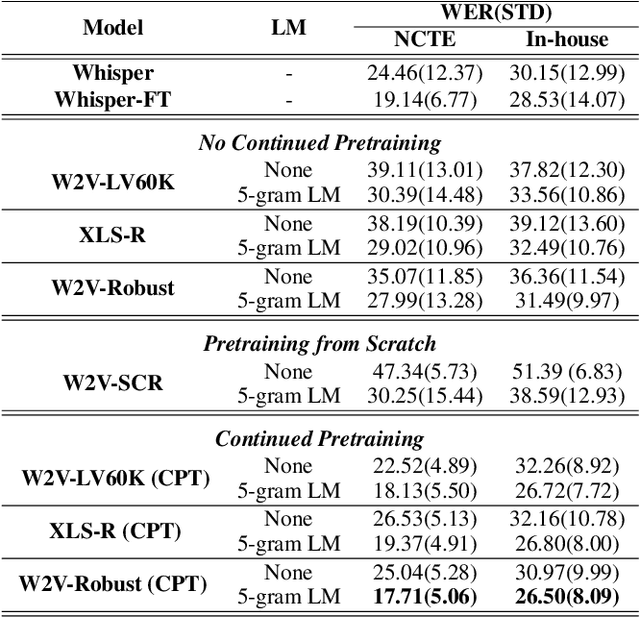
Creating Automatic Speech Recognition (ASR) systems that are robust and resilient to classroom conditions is paramount to the development of AI tools to aid teachers and students. In this work, we study the efficacy of continued pretraining (CPT) in adapting Wav2vec2.0 to the classroom domain. We show that CPT is a powerful tool in that regard and reduces the Word Error Rate (WER) of Wav2vec2.0-based models by upwards of 10%. More specifically, CPT improves the model's robustness to different noises, microphones, classroom conditions as well as classroom demographics. Our CPT models show improved ability to generalize to different demographics unseen in the labeled finetuning data.
Backtracing: Retrieving the Cause of the Query
Mar 06, 2024



Many online content portals allow users to ask questions to supplement their understanding (e.g., of lectures). While information retrieval (IR) systems may provide answers for such user queries, they do not directly assist content creators -- such as lecturers who want to improve their content -- identify segments that _caused_ a user to ask those questions. We introduce the task of backtracing, in which systems retrieve the text segment that most likely caused a user query. We formalize three real-world domains for which backtracing is important in improving content delivery and communication: understanding the cause of (a) student confusion in the Lecture domain, (b) reader curiosity in the News Article domain, and (c) user emotion in the Conversation domain. We evaluate the zero-shot performance of popular information retrieval methods and language modeling methods, including bi-encoder, re-ranking and likelihood-based methods and ChatGPT. While traditional IR systems retrieve semantically relevant information (e.g., details on "projection matrices" for a query "does projecting multiple times still lead to the same point?"), they often miss the causally relevant context (e.g., the lecturer states "projecting twice gets me the same answer as one projection"). Our results show that there is room for improvement on backtracing and it requires new retrieval approaches. We hope our benchmark serves to improve future retrieval systems for backtracing, spawning systems that refine content generation and identify linguistic triggers influencing user queries. Our code and data are open-sourced: https://github.com/rosewang2008/backtracing.