Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinued Pretraining for Domain Adaptation of Wav2vec2.0 in Automatic Speech Recognition for Elementary Math Classroom Settings
Paper and Code
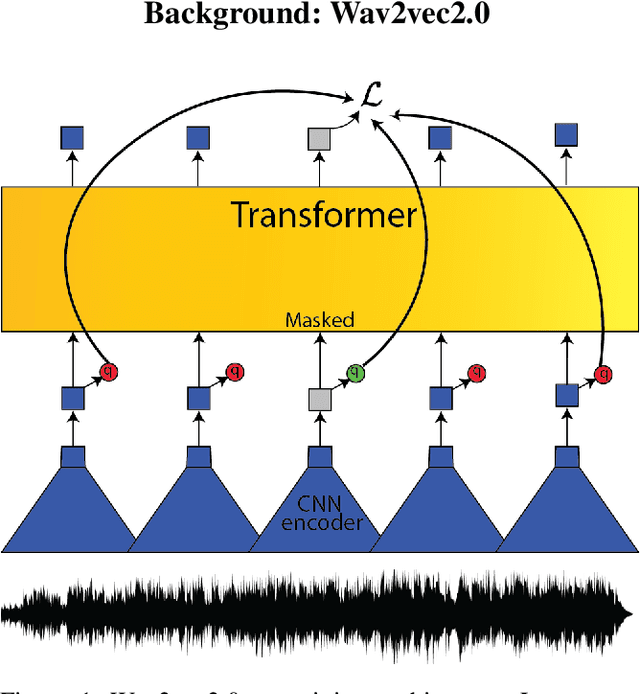
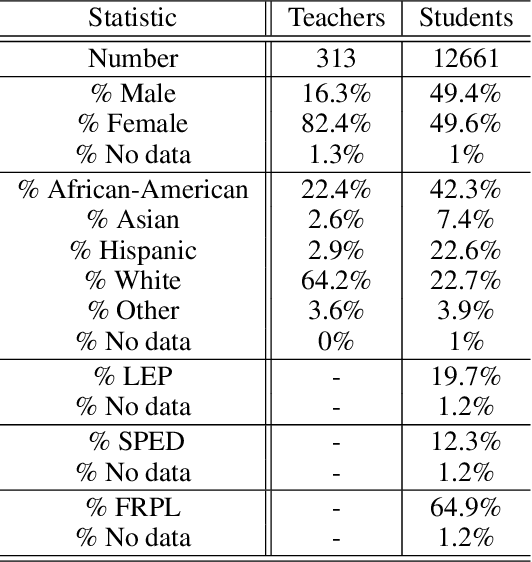
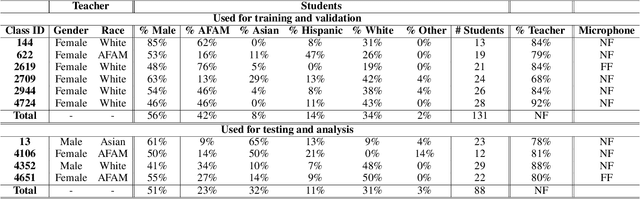
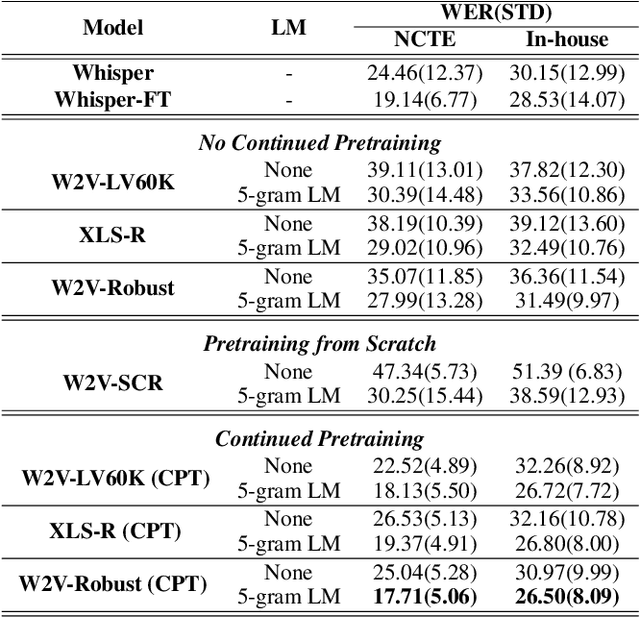
Creating Automatic Speech Recognition (ASR) systems that are robust and resilient to classroom conditions is paramount to the development of AI tools to aid teachers and students. In this work, we study the efficacy of continued pretraining (CPT) in adapting Wav2vec2.0 to the classroom domain. We show that CPT is a powerful tool in that regard and reduces the Word Error Rate (WER) of Wav2vec2.0-based models by upwards of 10%. More specifically, CPT improves the model's robustness to different noises, microphones, classroom conditions as well as classroom demographics. Our CPT models show improved ability to generalize to different demographics unseen in the labeled finetuning data.
View paper on