 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAIMCHECK: How Grounded are LLM Critiques of Scientific Papers?
Mar 27, 2025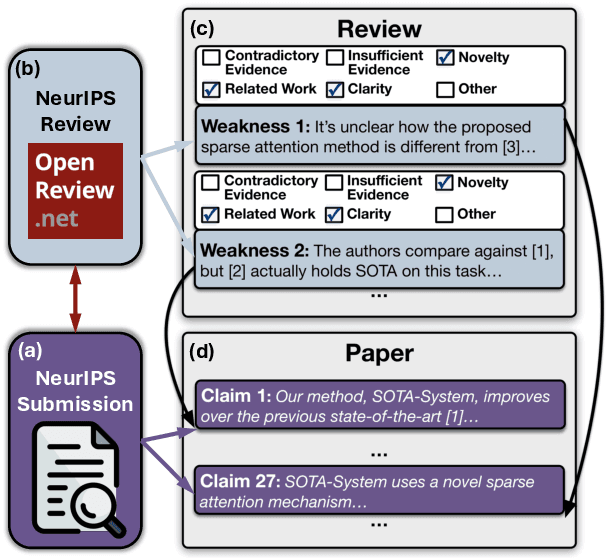
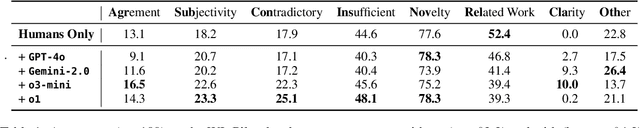
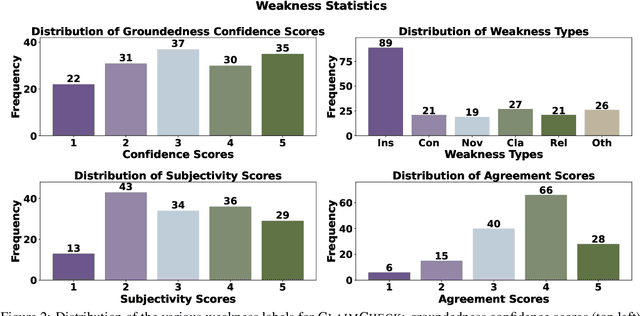
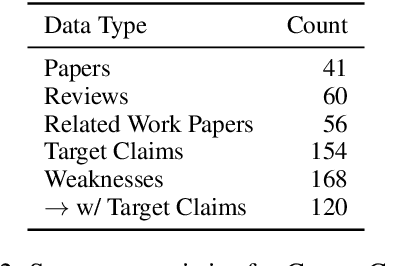
A core part of scientific peer review involves providing expert critiques that directly assess the scientific claims a paper makes. While it is now possible to automatically generate plausible (if generic) reviews, ensuring that these reviews are sound and grounded in the papers' claims remains challenging. To facilitate LLM benchmarking on these challenges, we introduce CLAIMCHECK, an annotated dataset of NeurIPS 2023 and 2024 submissions and reviews mined from OpenReview. CLAIMCHECK is richly annotated by ML experts for weakness statements in the reviews and the paper claims that they dispute, as well as fine-grained labels of the validity, objectivity, and type of the identified weaknesses. We benchmark several LLMs on three claim-centric tasks supported by CLAIMCHECK, requiring models to (1) associate weaknesses with the claims they dispute, (2) predict fine-grained labels for weaknesses and rewrite the weaknesses to enhance their specificity, and (3) verify a paper's claims with grounded reasoning. Our experiments reveal that cutting-edge LLMs, while capable of predicting weakness labels in (2), continue to underperform relative to human experts on all other tasks.
Measuring Five Accountable Talk Moves to Improve Instruction at Scale
Nov 02, 2023
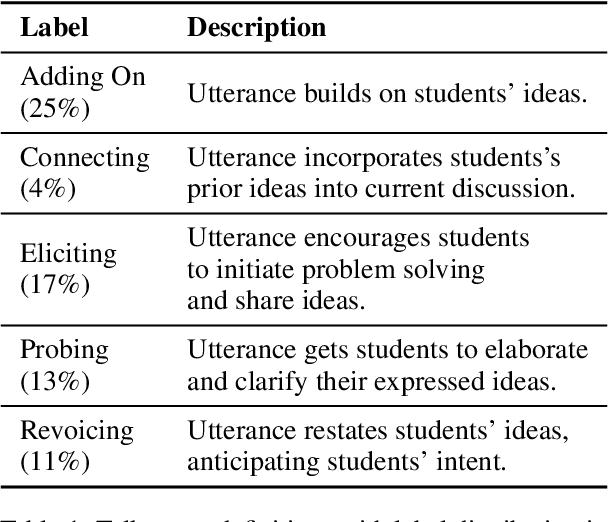
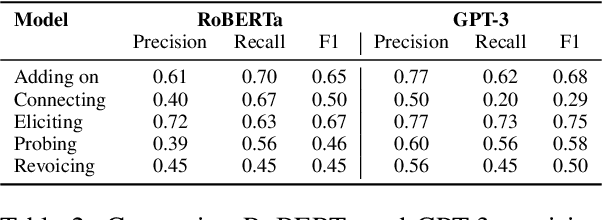
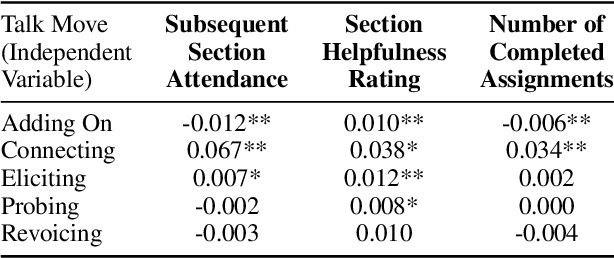
Providing consistent, individualized feedback to teachers on their instruction can improve student learning outcomes. Such feedback can especially benefit novice instructors who teach on online platforms and have limited access to instructional training. To build scalable measures of instruction, we fine-tune RoBERTa and GPT models to identify five instructional talk moves inspired by accountable talk theory: adding on, connecting, eliciting, probing and revoicing students' ideas. We fine-tune these models on a newly annotated dataset of 2500 instructor utterances derived from transcripts of small group instruction in an online computer science course, Code in Place. Although we find that GPT-3 consistently outperforms RoBERTa in terms of precision, its recall varies significantly. We correlate the instructors' use of each talk move with indicators of student engagement and satisfaction, including students' section attendance, section ratings, and assignment completion rates. We find that using talk moves generally correlates positively with student outcomes, and connecting student ideas has the largest positive impact. These results corroborate previous research on the effectiveness of accountable talk moves and provide exciting avenues for using these models to provide instructors with useful, scalable feedback.