 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Local News Stay Local?: Online Content Shifts in Sinclair-Acquired Stations
Oct 08, 2025Local news stations are often considered to be reliable sources of non-politicized information, particularly local concerns that residents care about. Because these stations are trusted news sources, viewers are particularly susceptible to the information they report. The Sinclair Broadcast group is a broadcasting company that has acquired many local news stations in the last decade. We investigate the effects of local news stations being acquired by Sinclair: how does coverage change? We use computational methods to investigate changes in internet content put out by local news stations before and after being acquired by Sinclair and in comparison to national news outlets. We find that there is clear evidence that local news stations report more frequently on national news at the expense of local topics, and that their coverage of polarizing national topics increases.
All Claims Are Equal, but Some Claims Are More Equal Than Others: Importance-Sensitive Factuality Evaluation of LLM Generations
Oct 08, 2025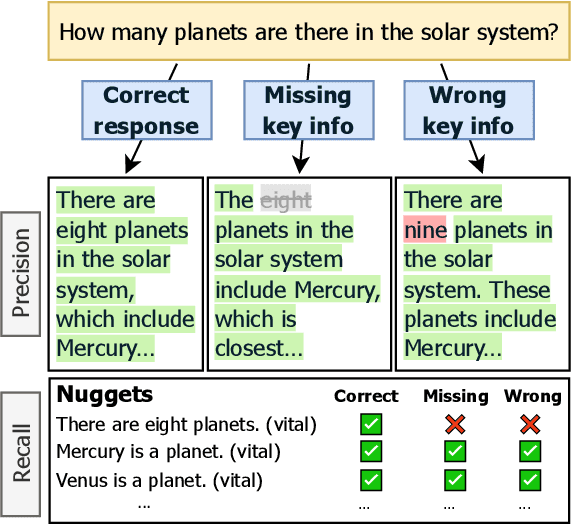
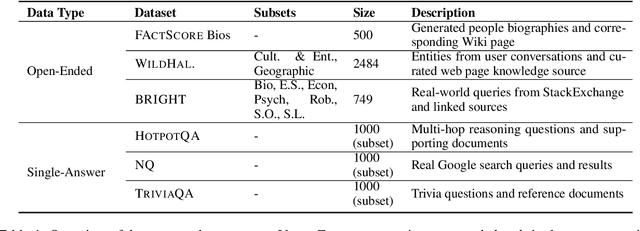
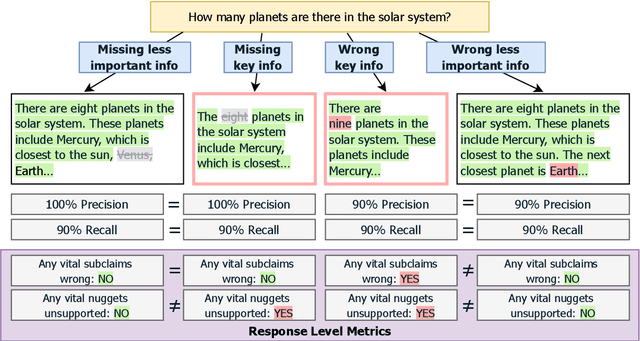

Existing methods for evaluating the factuality of large language model (LLM) responses treat all claims as equally important. This results in misleading evaluations when vital information is missing or incorrect as it receives the same weight as peripheral details, raising the question: how can we reliably detect such differences when there are errors in key information? Current approaches that measure factuality tend to be insensitive to omitted or false key information. To investigate this lack of sensitivity, we construct VITALERRORS, a benchmark of 6,733 queries with minimally altered LLM responses designed to omit or falsify key information. Using this dataset, we demonstrate the insensitivities of existing evaluation metrics to key information errors. To address this gap, we introduce VITAL, a set of metrics that provide greater sensitivity in measuring the factuality of responses by incorporating the relevance and importance of claims with respect to the query. Our analysis demonstrates that VITAL metrics more reliably detect errors in key information than previous methods. Our dataset, metrics, and analysis provide a foundation for more accurate and robust assessment of LLM factuality.
How Grounded is Wikipedia? A Study on Structured Evidential Support
Jun 14, 2025Wikipedia is a critical resource for modern NLP, serving as a rich repository of up-to-date and citation-backed information on a wide variety of subjects. The reliability of Wikipedia -- its groundedness in its cited sources -- is vital to this purpose. This work provides a quantitative analysis of the extent to which Wikipedia *is* so grounded and of how readily grounding evidence may be retrieved. To this end, we introduce PeopleProfiles -- a large-scale, multi-level dataset of claim support annotations on Wikipedia articles of notable people. We show that roughly 20% of claims in Wikipedia *lead* sections are unsupported by the article body; roughly 27% of annotated claims in the article *body* are unsupported by their (publicly accessible) cited sources; and >80% of lead claims cannot be traced to these sources via annotated body evidence. Further, we show that recovery of complex grounding evidence for claims that *are* supported remains a challenge for standard retrieval methods.
CLAIMCHECK: How Grounded are LLM Critiques of Scientific Papers?
Mar 27, 2025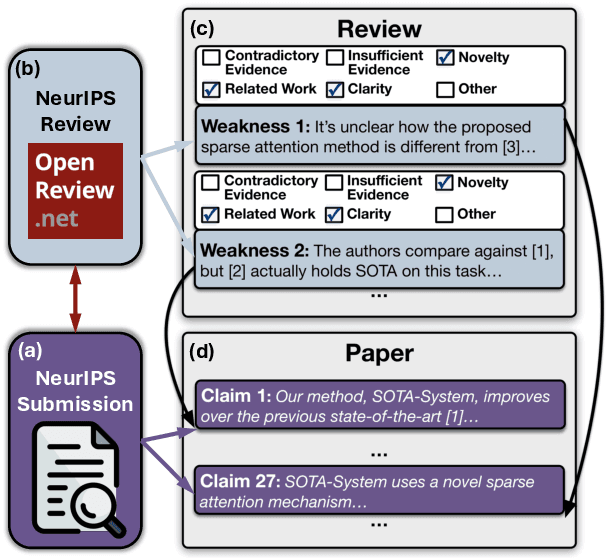
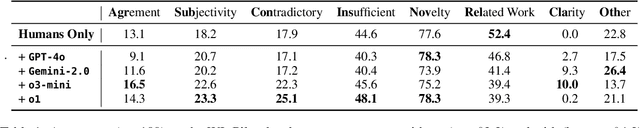
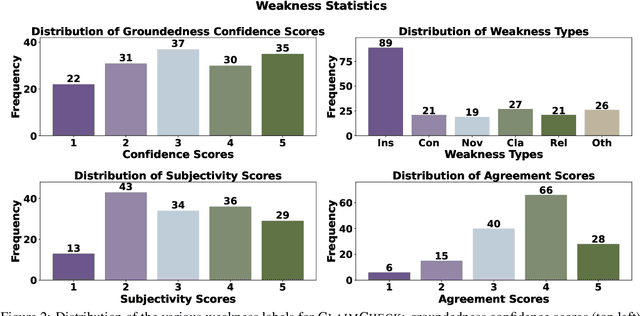
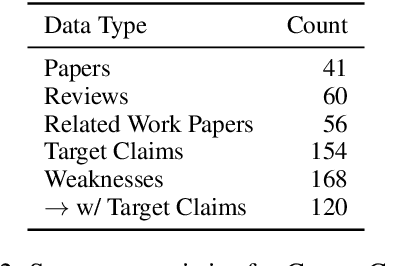
A core part of scientific peer review involves providing expert critiques that directly assess the scientific claims a paper makes. While it is now possible to automatically generate plausible (if generic) reviews, ensuring that these reviews are sound and grounded in the papers' claims remains challenging. To facilitate LLM benchmarking on these challenges, we introduce CLAIMCHECK, an annotated dataset of NeurIPS 2023 and 2024 submissions and reviews mined from OpenReview. CLAIMCHECK is richly annotated by ML experts for weakness statements in the reviews and the paper claims that they dispute, as well as fine-grained labels of the validity, objectivity, and type of the identified weaknesses. We benchmark several LLMs on three claim-centric tasks supported by CLAIMCHECK, requiring models to (1) associate weaknesses with the claims they dispute, (2) predict fine-grained labels for weaknesses and rewrite the weaknesses to enhance their specificity, and (3) verify a paper's claims with grounded reasoning. Our experiments reveal that cutting-edge LLMs, while capable of predicting weakness labels in (2), continue to underperform relative to human experts on all other tasks.
DnDScore: Decontextualization and Decomposition for Factuality Verification in Long-Form Text Generation
Dec 17, 2024



The decompose-then-verify strategy for verification of Large Language Model (LLM) generations decomposes claims that are then independently verified. Decontextualization augments text (claims) to ensure it can be verified outside of the original context, enabling reliable verification. While decomposition and decontextualization have been explored independently, their interactions in a complete system have not been investigated. Their conflicting purposes can create tensions: decomposition isolates atomic facts while decontextualization inserts relevant information. Furthermore, a decontextualized subclaim presents a challenge to the verification step: what part of the augmented text should be verified as it now contains multiple atomic facts? We conduct an evaluation of different decomposition, decontextualization, and verification strategies and find that the choice of strategy matters in the resulting factuality scores. Additionally, we introduce DnDScore, a decontextualization aware verification method which validates subclaims in the context of contextual information.
Core: Robust Factual Precision Scoring with Informative Sub-Claim Identification
Jul 04, 2024

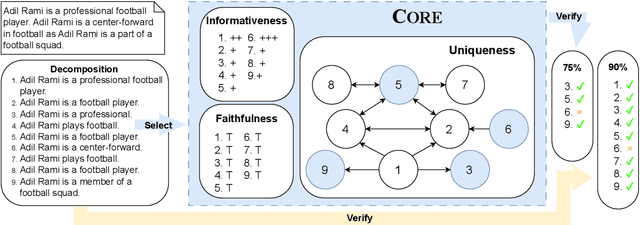

Hallucinations -- the generation of untrue claims -- pose a challenge to the application of large language models (LLMs) [1] thereby motivating the development of metrics to evaluate factual precision. We observe that popular metrics using the Decompose-Then-Verify framework, such as FActScore [2], can be manipulated by adding obvious or repetitive claims to artificially inflate scores. We expand the FActScore dataset to design and analyze factual precision metrics, demonstrating that models can be trained to achieve high scores under existing metrics through exploiting the issues we identify. This motivates our new customizable plug-and-play subclaim selection component called Core, which filters down individual subclaims according to their uniqueness and informativeness. Metrics augmented by Core are substantially more robust as shown in head-to-head comparisons. We release an evaluation framework supporting the modular use of Core (https://github.com/zipJiang/Core) and various decomposition strategies, and we suggest its adoption by the LLM community. [1] Hong et al., "The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models", arXiv:2404.05904v2 [cs.CL]. [2] Min et al., "FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation", arXiv:2305.14251v2 [cs.CL].
A Closer Look at Claim Decomposition
Mar 18, 2024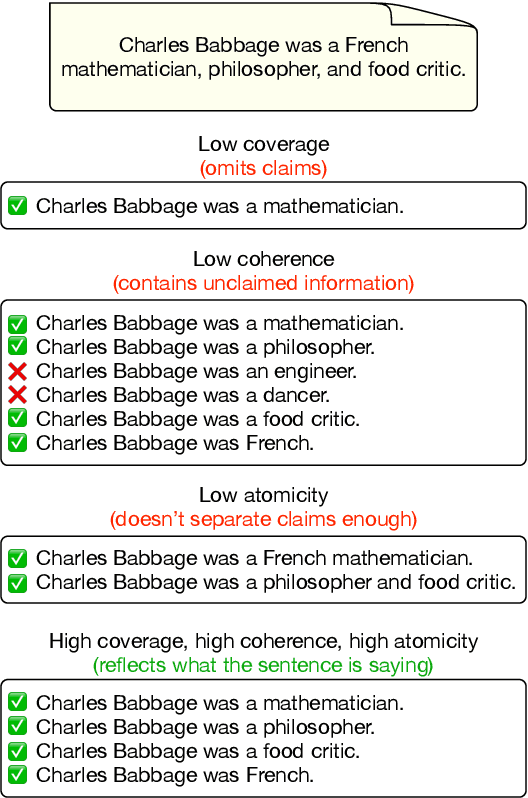

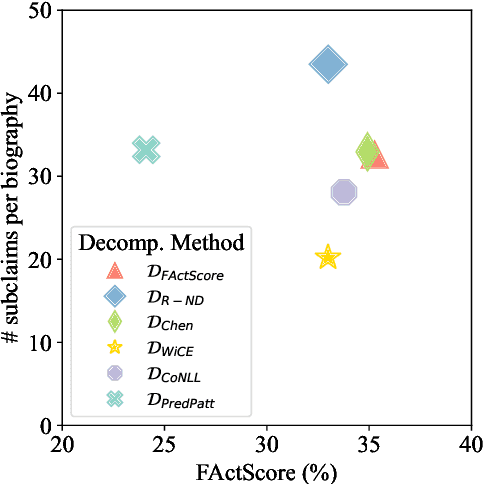
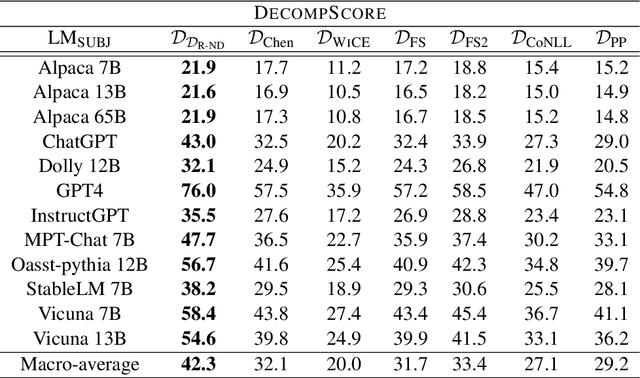
As generated text becomes more commonplace, it is increasingly important to evaluate how well-supported such text is by external knowledge sources. Many approaches for evaluating textual support rely on some method for decomposing text into its individual subclaims which are scored against a trusted reference. We investigate how various methods of claim decomposition -- especially LLM-based methods -- affect the result of an evaluation approach such as the recently proposed FActScore, finding that it is sensitive to the decomposition method used. This sensitivity arises because such metrics attribute overall textual support to the model that generated the text even though error can also come from the metric's decomposition step. To measure decomposition quality, we introduce an adaptation of FActScore, which we call DecompScore. We then propose an LLM-based approach to generating decompositions inspired by Bertrand Russell's theory of logical atomism and neo-Davidsonian semantics and demonstrate its improved decomposition quality over previous methods.
Revisiting the Effects of Leakage on Dependency Parsing
Mar 24, 2022
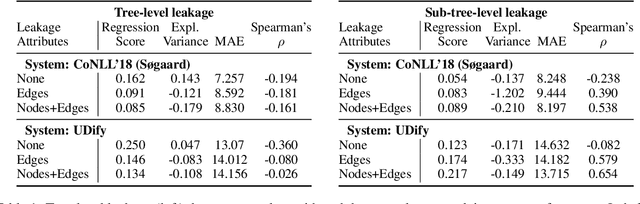

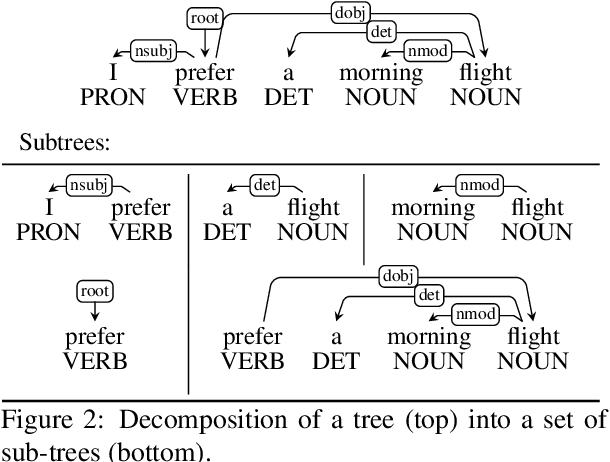
Recent work by S{\o}gaard (2020) showed that, treebank size aside, overlap between training and test graphs (termed leakage) explains more of the observed variation in dependency parsing performance than other explanations. In this work we revisit this claim, testing it on more models and languages. We find that it only holds for zero-shot cross-lingual settings. We then propose a more fine-grained measure of such leakage which, unlike the original measure, not only explains but also correlates with observed performance variation. Code and data are available here: https://github.com/miriamwanner/reu-nlp-project