 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Generate Tabular Summaries of Science Papers? Rethinking the Evaluation Protocol
Apr 14, 2025
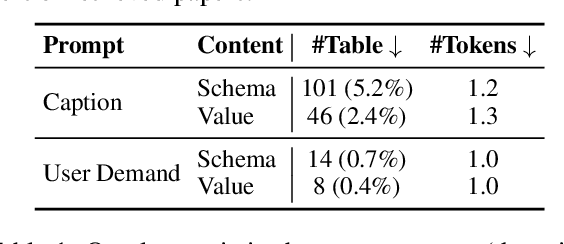
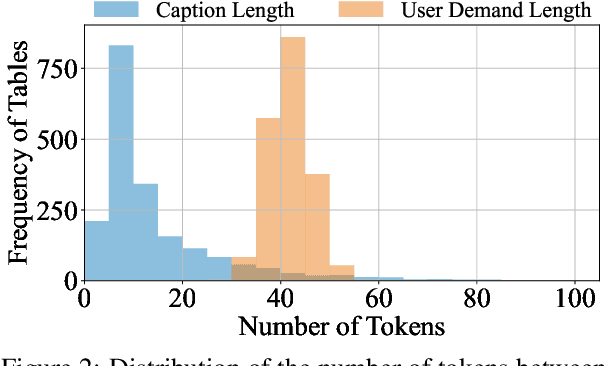
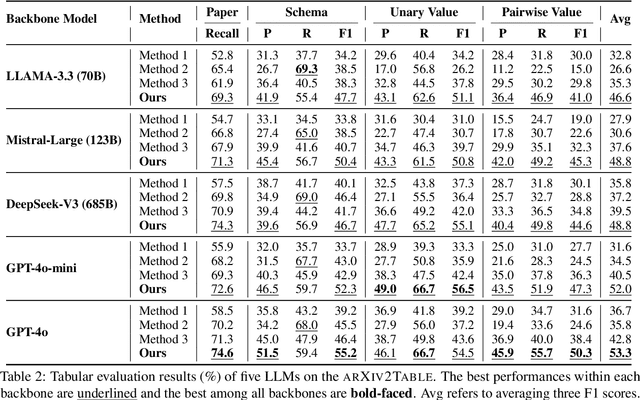
Literature review tables are essential for summarizing and comparing collections of scientific papers. We explore the task of generating tables that best fulfill a user's informational needs given a collection of scientific papers. Building on recent work (Newman et al., 2024), we extend prior approaches to address real-world complexities through a combination of LLM-based methods and human annotations. Our contributions focus on three key challenges encountered in real-world use: (i) User prompts are often under-specified; (ii) Retrieved candidate papers frequently contain irrelevant content; and (iii) Task evaluation should move beyond shallow text similarity techniques and instead assess the utility of inferred tables for information-seeking tasks (e.g., comparing papers). To support reproducible evaluation, we introduce ARXIV2TABLE, a more realistic and challenging benchmark for this task, along with a novel approach to improve literature review table generation in real-world scenarios. Our extensive experiments on this benchmark show that both open-weight and proprietary LLMs struggle with the task, highlighting its difficulty and the need for further advancements. Our dataset and code are available at https://github.com/JHU-CLSP/arXiv2Table.
CLAIMCHECK: How Grounded are LLM Critiques of Scientific Papers?
Mar 27, 2025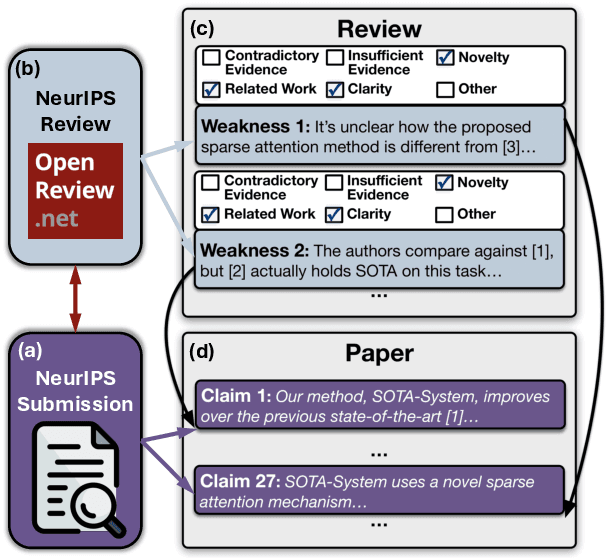
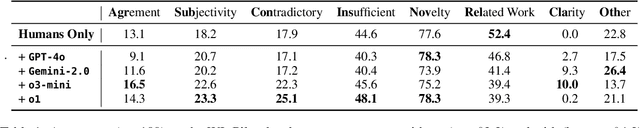
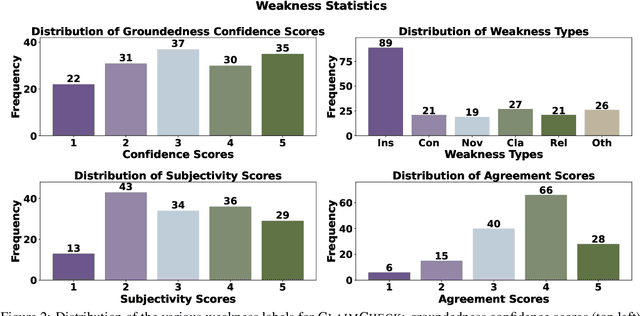
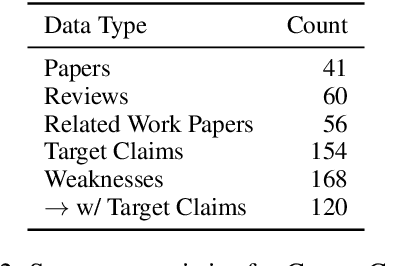
A core part of scientific peer review involves providing expert critiques that directly assess the scientific claims a paper makes. While it is now possible to automatically generate plausible (if generic) reviews, ensuring that these reviews are sound and grounded in the papers' claims remains challenging. To facilitate LLM benchmarking on these challenges, we introduce CLAIMCHECK, an annotated dataset of NeurIPS 2023 and 2024 submissions and reviews mined from OpenReview. CLAIMCHECK is richly annotated by ML experts for weakness statements in the reviews and the paper claims that they dispute, as well as fine-grained labels of the validity, objectivity, and type of the identified weaknesses. We benchmark several LLMs on three claim-centric tasks supported by CLAIMCHECK, requiring models to (1) associate weaknesses with the claims they dispute, (2) predict fine-grained labels for weaknesses and rewrite the weaknesses to enhance their specificity, and (3) verify a paper's claims with grounded reasoning. Our experiments reveal that cutting-edge LLMs, while capable of predicting weakness labels in (2), continue to underperform relative to human experts on all other tasks.
WorldAPIs: The World Is Worth How Many APIs? A Thought Experiment
Jul 10, 2024AI systems make decisions in physical environments through primitive actions or affordances that are accessed via API calls. While deploying AI agents in the real world involves numerous high-level actions, existing embodied simulators offer a limited set of domain-salient APIs. This naturally brings up the questions: how many primitive actions (APIs) are needed for a versatile embodied agent, and what should they look like? We explore this via a thought experiment: assuming that wikiHow tutorials cover a wide variety of human-written tasks, what is the space of APIs needed to cover these instructions? We propose a framework to iteratively induce new APIs by grounding wikiHow instruction to situated agent policies. Inspired by recent successes in large language models (LLMs) for embodied planning, we propose a few-shot prompting to steer GPT-4 to generate Pythonic programs as agent policies and bootstrap a universe of APIs by 1) reusing a seed set of APIs; and then 2) fabricate new API calls when necessary. The focus of this thought experiment is on defining these APIs rather than their executability. We apply the proposed pipeline on instructions from wikiHow tutorials. On a small fraction (0.5%) of tutorials, we induce an action space of 300+ APIs necessary for capturing the rich variety of tasks in the physical world. A detailed automatic and human analysis of the induction output reveals that the proposed pipeline enables effective reuse and creation of APIs. Moreover, a manual review revealed that existing simulators support only a small subset of the induced APIs (9 of the top 50 frequent APIs), motivating the development of action-rich embodied environments.
Pragmatic Inference with a CLIP Listener for Contrastive Captioning
Jun 15, 2023
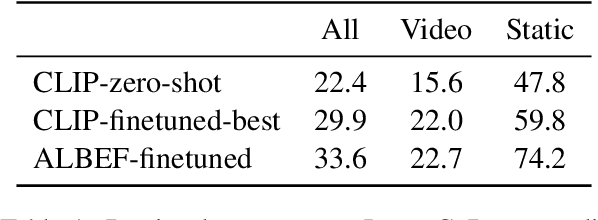
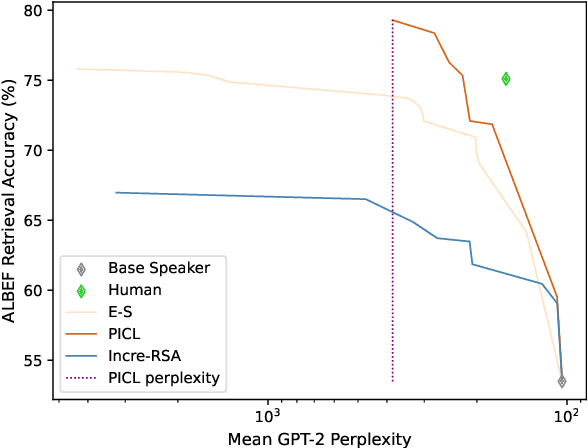
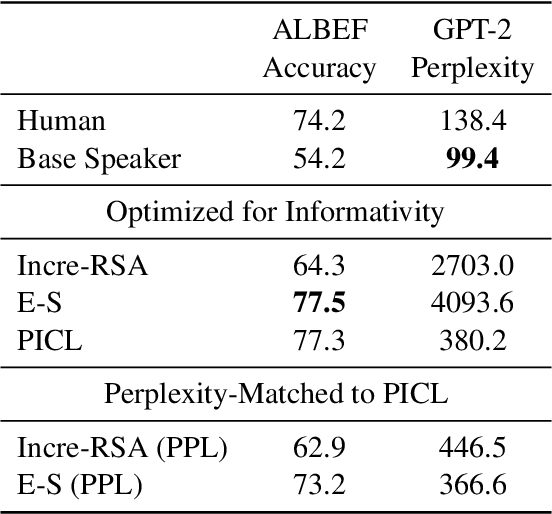
We propose a simple yet effective and robust method for contrastive captioning: generating discriminative captions that distinguish target images from very similar alternative distractor images. Our approach is built on a pragmatic inference procedure that formulates captioning as a reference game between a speaker, which produces possible captions describing the target, and a listener, which selects the target given the caption. Unlike previous methods that derive both speaker and listener distributions from a single captioning model, we leverage an off-the-shelf CLIP model to parameterize the listener. Compared with captioner-only pragmatic models, our method benefits from rich vision language alignment representations from CLIP when reasoning over distractors. Like previous methods for discriminative captioning, our method uses a hyperparameter to control the tradeoff between the informativity (how likely captions are to allow a human listener to discriminate the target image) and the fluency of the captions. However, we find that our method is substantially more robust to the value of this hyperparameter than past methods, which allows us to automatically optimize the captions for informativity - outperforming past methods for discriminative captioning by 11% to 15% accuracy in human evaluations
Hierarchical Event Grounding
Feb 08, 2023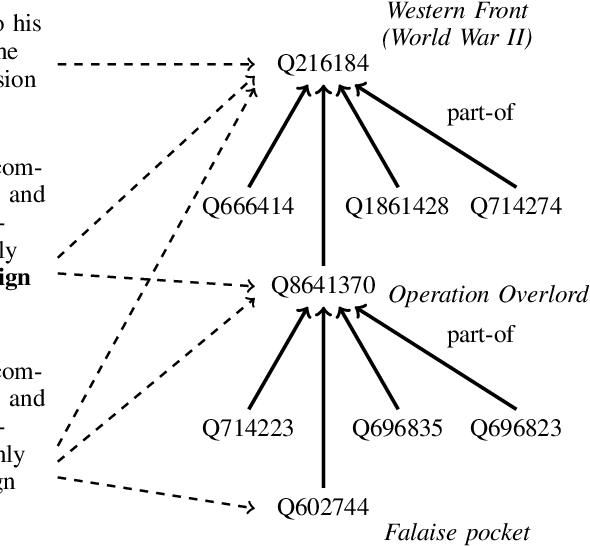
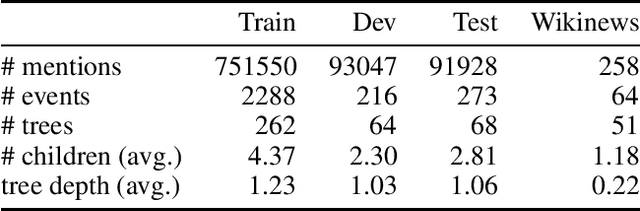
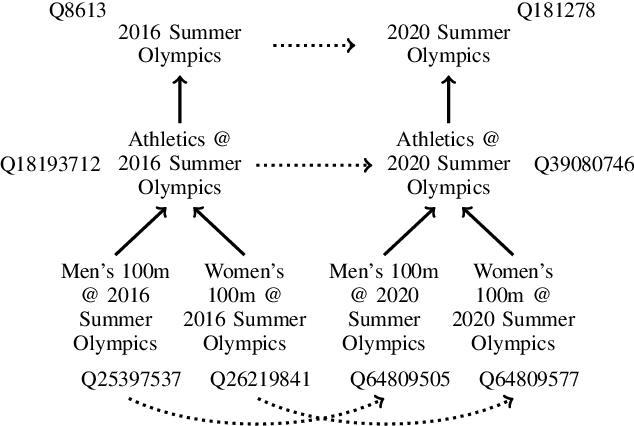
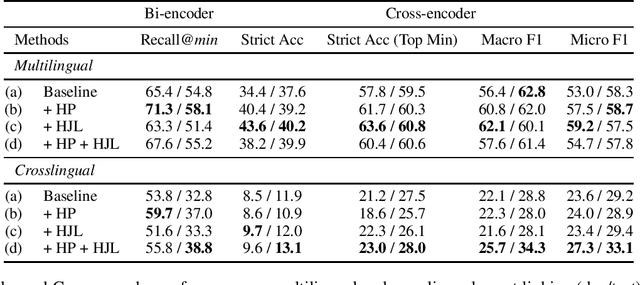
Event grounding aims at linking mention references in text corpora to events from a knowledge base (KB). Previous work on this task focused primarily on linking to a single KB event, thereby overlooking the hierarchical aspects of events. Events in documents are typically described at various levels of spatio-temporal granularity (Glavas et al. 2014). These hierarchical relations are utilized in downstream tasks of narrative understanding and schema construction. In this work, we present an extension to the event grounding task that requires tackling hierarchical event structures from the KB. Our proposed task involves linking a mention reference to a set of event labels from a subevent hierarchy in the KB. We propose a retrieval methodology that leverages event hierarchy through an auxiliary hierarchical loss (Murty et al. 2018). On an automatically created multilingual dataset from Wikipedia and Wikidata, our experiments demonstrate the effectiveness of the hierarchical loss against retrieve and re-rank baselines (Wu et al. 2020; Pratapa, Gupta, and Mitamura 2022). Furthermore, we demonstrate the systems' ability to aid hierarchical discovery among unseen events.
Exploring Discourse Structures for Argument Impact Classification
Jun 02, 2021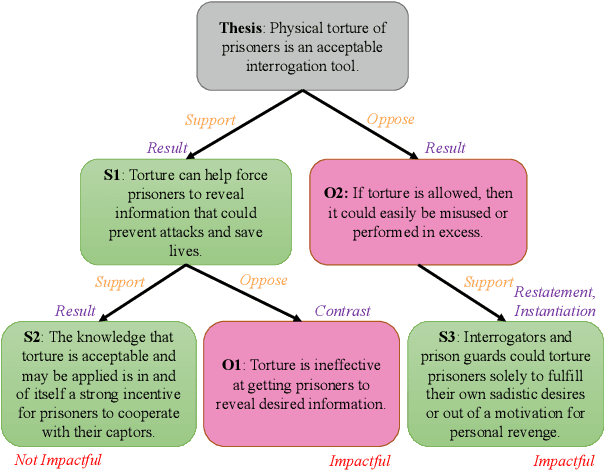
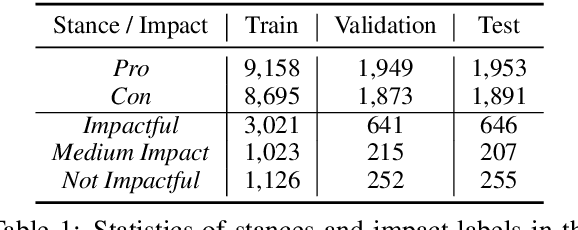
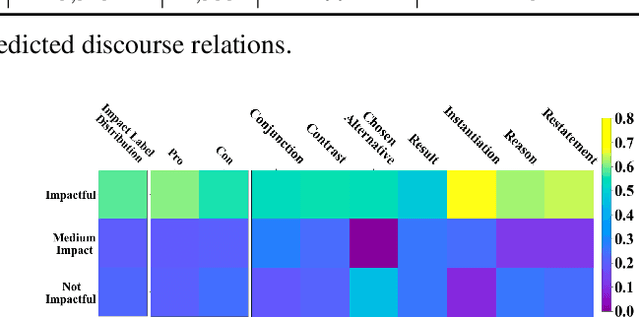

Discourse relations among arguments reveal logical structures of a debate conversation. However, no prior work has explicitly studied how the sequence of discourse relations influence a claim's impact. This paper empirically shows that the discourse relations between two arguments along the context path are essential factors for identifying the persuasive power of an argument. We further propose DisCOC to inject and fuse the sentence-level structural discourse information with contextualized features derived from large-scale language models. Experimental results and extensive analysis show that the attention and gate mechanisms that explicitly model contexts and texts can indeed help the argument impact classification task defined by Durmus et al. (2019), and discourse structures among the context path of the claim to be classified can further boost the performance.
ASER: Towards Large-scale Commonsense Knowledge Acquisition via Higher-order Selectional Preference over Eventualities
Apr 05, 2021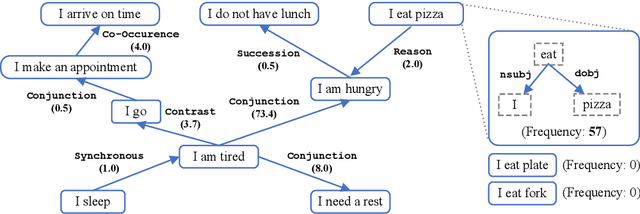
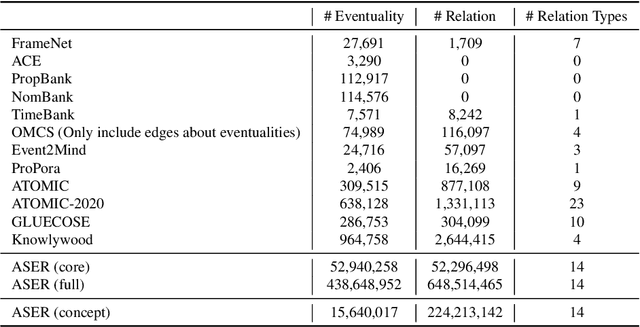
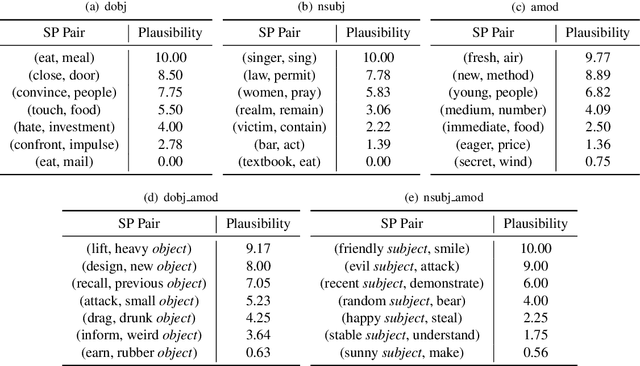
Commonsense knowledge acquisition and reasoning have long been a core artificial intelligence problem. However, in the past, there has been a lack of scalable methods to collect commonsense knowledge. In this paper, we propose to develop principles for collecting commonsense knowledge based on selectional preference. We generalize the definition of selectional preference from one-hop linguistic syntactic relations to higher-order relations over linguistic graphs. Unlike previous commonsense knowledge definition (e.g., ConceptNet), the selectional preference (SP) knowledge only relies on statistical distribution over linguistic graphs, which can be efficiently and accurately acquired from the unlabeled corpus with modern tools. Following this principle, we develop a large-scale eventuality (a linguistic term covering activity, state, and event)-based knowledge graph ASER, where each eventuality is represented as a dependency graph, and the relation between them is a discourse relation defined in shallow discourse parsing. The higher-order selectional preference over collected linguistic graphs reflects various kinds of commonsense knowledge. Moreover, motivated by the observation that humans understand events by abstracting the observed events to a higher level and can thus transferring their knowledge to new events, we propose a conceptualization module to significantly boost the coverage of ASER. In total, ASER contains 438 million eventualities and 648 million edges between eventualities. After conceptualization with Probase, a selectional preference based concept-instance relational knowledge base, our concept graph contains 15 million conceptualized eventualities and 224 million edges between them. Detailed analysis is provided to demonstrate its quality. All the collected data, APIs, and tools are available at https://github.com/HKUST-KnowComp/ASER.
InFillmore: Neural Frame Lexicalization for Narrative Text Infilling
Mar 08, 2021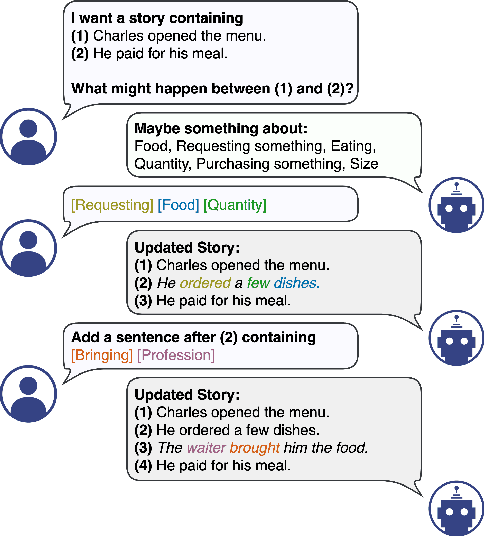
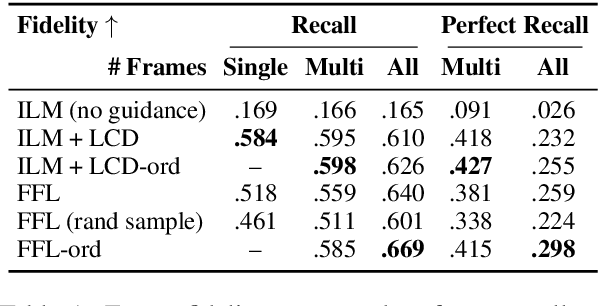

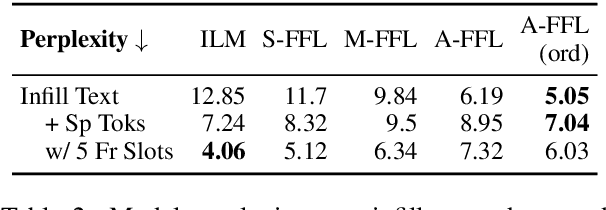
We propose a structured extension to bidirectional-context conditional language generation, or "infilling," inspired by Frame Semantic theory (Fillmore, 1976). Guidance is provided through two approaches: (1) model fine-tuning, conditioning directly on observed symbolic frames, and (2) a novel extension to disjunctive lexically constrained decoding that leverages frame semantic lexical units. Automatic and human evaluations confirm that frame-guided generation allows for explicit manipulation of intended infill semantics, with minimal loss of indistinguishability from the human-generated text. Our methods flexibly apply to a variety of use scenarios, and we provide an interactive web demo available at https://nlp.jhu.edu/demos.
On the Importance of Word and Sentence Representation Learning in Implicit Discourse Relation Classification
Apr 28, 2020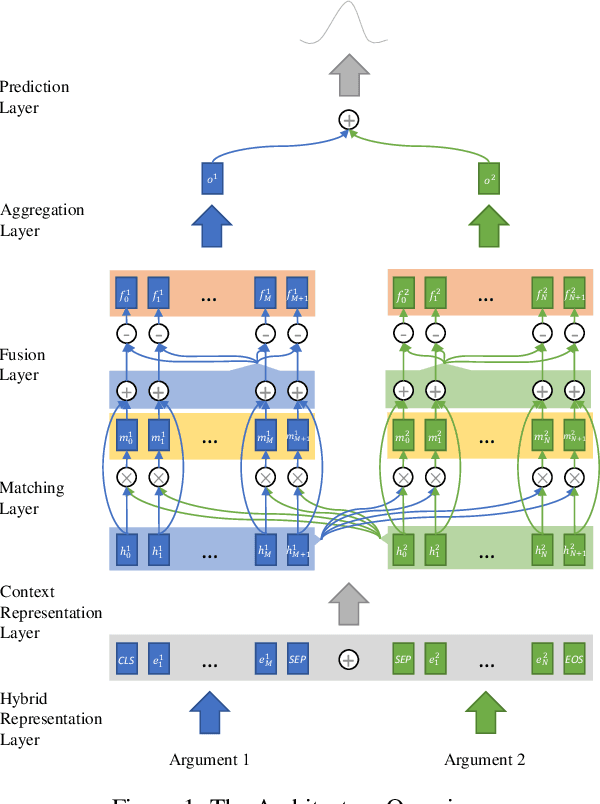
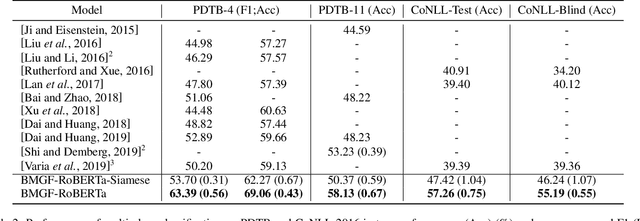
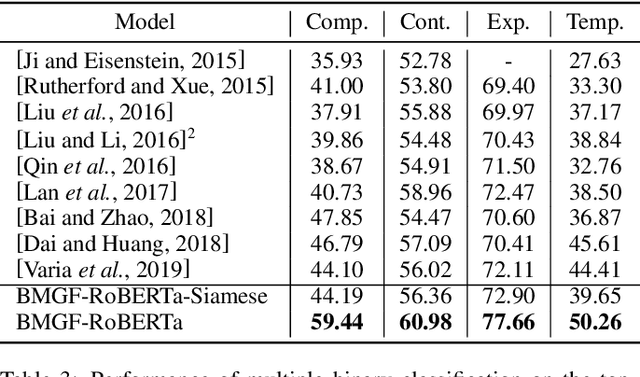
Implicit discourse relation classification is one of the most difficult parts in shallow discourse parsing as the relation prediction without explicit connectives requires the language understanding at both the text span level and the sentence level. Previous studies mainly focus on the interactions between two arguments. We argue that a powerful contextualized representation module, a bilateral multi-perspective matching module, and a global information fusion module are all important to implicit discourse analysis. We propose a novel model to combine these modules together. Extensive experiments show that our proposed model outperforms BERT and other state-of-the-art systems on the PDTB dataset by around 8% and CoNLL 2016 datasets around 16%. We also analyze the effectiveness of different modules in the implicit discourse relation classification task and demonstrate how different levels of representation learning can affect the results.