 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Data-Driven Reasoning Rubrics for Domain-Adaptive Reward Modeling
Feb 06, 2026An impediment to using Large Language Models (LLMs) for reasoning output verification is that LLMs struggle to reliably identify errors in thinking traces, particularly in long outputs, domains requiring expert knowledge, and problems without verifiable rewards. We propose a data-driven approach to automatically construct highly granular reasoning error taxonomies to enhance LLM-driven error detection on unseen reasoning traces. Our findings indicate that classification approaches that leverage these error taxonomies, or "rubrics", demonstrate strong error identification compared to baseline methods in technical domains like coding, math, and chemical engineering. These rubrics can be used to build stronger LLM-as-judge reward functions for reasoning model training via reinforcement learning. Experimental results show that these rewards have the potential to improve models' task accuracy on difficult domains over models trained by general LLMs-as-judges by +45%, and approach performance of models trained by verifiable rewards while using as little as 20% as many gold labels. Through our approach, we extend the usage of reward rubrics from assessing qualitative model behavior to assessing quantitative model correctness on tasks typically learned via RLVR rewards. This extension opens the door for teaching models to solve complex technical problems without a full dataset of gold labels, which are often highly costly to procure.
Bonsai: Interpretable Tree-Adaptive Grounded Reasoning
Apr 04, 2025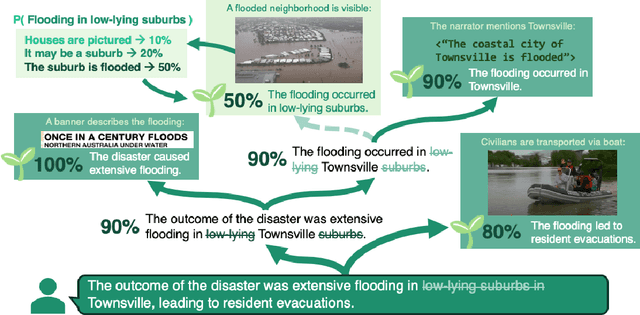


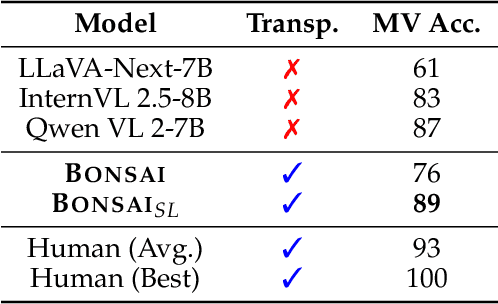
To develop general-purpose collaborative agents, humans need reliable AI systems that can (1) adapt to new domains and (2) transparently reason with uncertainty to allow for verification and correction. Black-box models demonstrate powerful data processing abilities but do not satisfy these criteria due to their opaqueness, domain specificity, and lack of uncertainty awareness. We introduce Bonsai, a compositional and probabilistic reasoning system that generates adaptable inference trees by retrieving relevant grounding evidence and using it to compute likelihoods of sub-claims derived from broader natural language inferences. Bonsai's reasoning power is tunable at test-time via evidence scaling and it demonstrates reliable handling of varied domains including transcripts, photographs, videos, audio, and databases. Question-answering and human alignment experiments demonstrate that Bonsai matches the performance of domain-specific black-box methods while generating interpretable, grounded, and uncertainty-aware reasoning traces.
WikiVideo: Article Generation from Multiple Videos
Apr 01, 2025We present the challenging task of automatically creating a high-level Wikipedia-style article that aggregates information from multiple diverse videos about real-world events, such as natural disasters or political elections. Videos are intuitive sources for retrieval-augmented generation (RAG), but most contemporary RAG workflows focus heavily on text and existing methods for video-based summarization focus on low-level scene understanding rather than high-level event semantics. To close this gap, we introduce WikiVideo, a benchmark consisting of expert-written articles and densely annotated videos that provide evidence for articles' claims, facilitating the integration of video into RAG pipelines and enabling the creation of in-depth content that is grounded in multimodal sources. We further propose Collaborative Article Generation (CAG), a novel interactive method for article creation from multiple videos. CAG leverages an iterative interaction between an r1-style reasoning model and a VideoLLM to draw higher level inferences about the target event than is possible with VideoLLMs alone, which fixate on low-level visual features. We benchmark state-of-the-art VideoLLMs and CAG in both oracle retrieval and RAG settings and find that CAG consistently outperforms alternative methods, while suggesting intriguing avenues for future work.
CLAIMCHECK: How Grounded are LLM Critiques of Scientific Papers?
Mar 27, 2025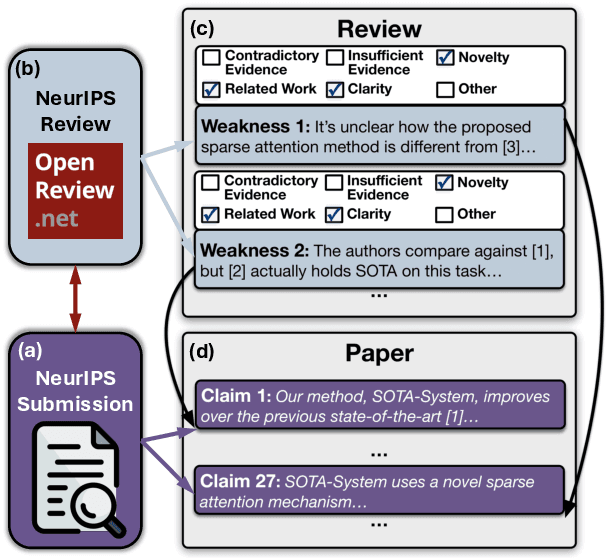
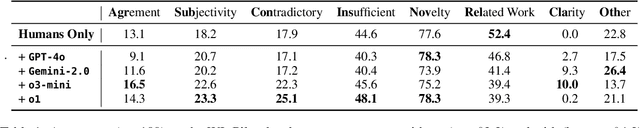
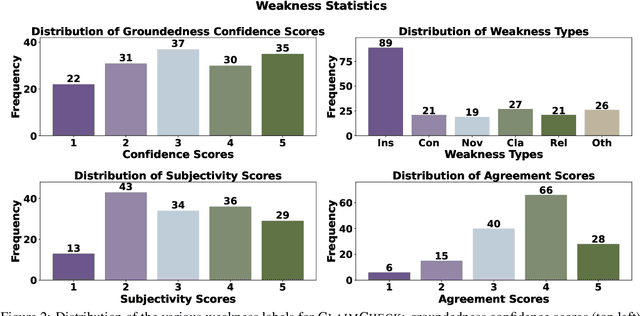
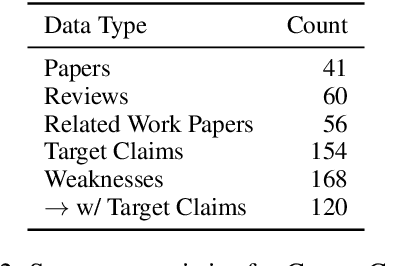
A core part of scientific peer review involves providing expert critiques that directly assess the scientific claims a paper makes. While it is now possible to automatically generate plausible (if generic) reviews, ensuring that these reviews are sound and grounded in the papers' claims remains challenging. To facilitate LLM benchmarking on these challenges, we introduce CLAIMCHECK, an annotated dataset of NeurIPS 2023 and 2024 submissions and reviews mined from OpenReview. CLAIMCHECK is richly annotated by ML experts for weakness statements in the reviews and the paper claims that they dispute, as well as fine-grained labels of the validity, objectivity, and type of the identified weaknesses. We benchmark several LLMs on three claim-centric tasks supported by CLAIMCHECK, requiring models to (1) associate weaknesses with the claims they dispute, (2) predict fine-grained labels for weaknesses and rewrite the weaknesses to enhance their specificity, and (3) verify a paper's claims with grounded reasoning. Our experiments reveal that cutting-edge LLMs, while capable of predicting weakness labels in (2), continue to underperform relative to human experts on all other tasks.
MMMORRF: Multimodal Multilingual Modularized Reciprocal Rank Fusion
Mar 26, 2025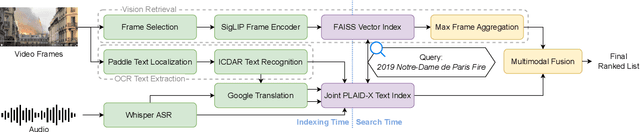


Videos inherently contain multiple modalities, including visual events, text overlays, sounds, and speech, all of which are important for retrieval. However, state-of-the-art multimodal language models like VAST and LanguageBind are built on vision-language models (VLMs), and thus overly prioritize visual signals. Retrieval benchmarks further reinforce this bias by focusing on visual queries and neglecting other modalities. We create a search system MMMORRF that extracts text and features from both visual and audio modalities and integrates them with a novel modality-aware weighted reciprocal rank fusion. MMMORRF is both effective and efficient, demonstrating practicality in searching videos based on users' information needs instead of visual descriptive queries. We evaluate MMMORRF on MultiVENT 2.0 and TVR, two multimodal benchmarks designed for more targeted information needs, and find that it improves nDCG@20 by 81% over leading multimodal encoders and 37% over single-modality retrieval, demonstrating the value of integrating diverse modalities.
Video-ColBERT: Contextualized Late Interaction for Text-to-Video Retrieval
Mar 24, 2025In this work, we tackle the problem of text-to-video retrieval (T2VR). Inspired by the success of late interaction techniques in text-document, text-image, and text-video retrieval, our approach, Video-ColBERT, introduces a simple and efficient mechanism for fine-grained similarity assessment between queries and videos. Video-ColBERT is built upon 3 main components: a fine-grained spatial and temporal token-wise interaction, query and visual expansions, and a dual sigmoid loss during training. We find that this interaction and training paradigm leads to strong individual, yet compatible, representations for encoding video content. These representations lead to increases in performance on common text-to-video retrieval benchmarks compared to other bi-encoder methods.
Randomly Sampled Language Reasoning Problems Reveal Limits of LLMs
Jan 07, 2025



Can LLMs pick up language structure from examples? Evidence in prior work seems to indicate yes, as pretrained models repeatedly demonstrate the ability to adapt to new language structures and vocabularies. However, this line of research typically considers languages that are present within common pretraining datasets, or otherwise share notable similarities with these seen languages. In contrast, in this work we attempt to measure models' language understanding capacity while circumventing the risk of dataset recall. We parameterize large families of language tasks recognized by deterministic finite automata (DFAs), and can thus sample novel language reasoning problems to fairly evaulate LLMs regardless of training data. We find that, even in the strikingly simple setting of 3-state DFAs, LLMs underperform unparameterized ngram models on both language recognition and synthesis tasks. These results suggest that LLMs struggle to match the ability of basic language models in recognizing and reasoning over languages that are sufficiently distinct from the ones they see at training time, underscoring the distinction between learning individual languages and possessing a general theory of language.
MultiVENT 2.0: A Massive Multilingual Benchmark for Event-Centric Video Retrieval
Oct 15, 2024Efficiently retrieving and synthesizing information from large-scale multimodal collections has become a critical challenge. However, existing video retrieval datasets suffer from scope limitations, primarily focusing on matching descriptive but vague queries with small collections of professionally edited, English-centric videos. To address this gap, we introduce $\textbf{MultiVENT 2.0}$, a large-scale, multilingual event-centric video retrieval benchmark featuring a collection of more than 218,000 news videos and 3,906 queries targeting specific world events. These queries specifically target information found in the visual content, audio, embedded text, and text metadata of the videos, requiring systems leverage all these sources to succeed at the task. Preliminary results show that state-of-the-art vision-language models struggle significantly with this task, and while alternative approaches show promise, they are still insufficient to adequately address this problem. These findings underscore the need for more robust multimodal retrieval systems, as effective video retrieval is a crucial step towards multimodal content understanding and generation tasks.
Grounding Partially-Defined Events in Multimodal Data
Oct 07, 2024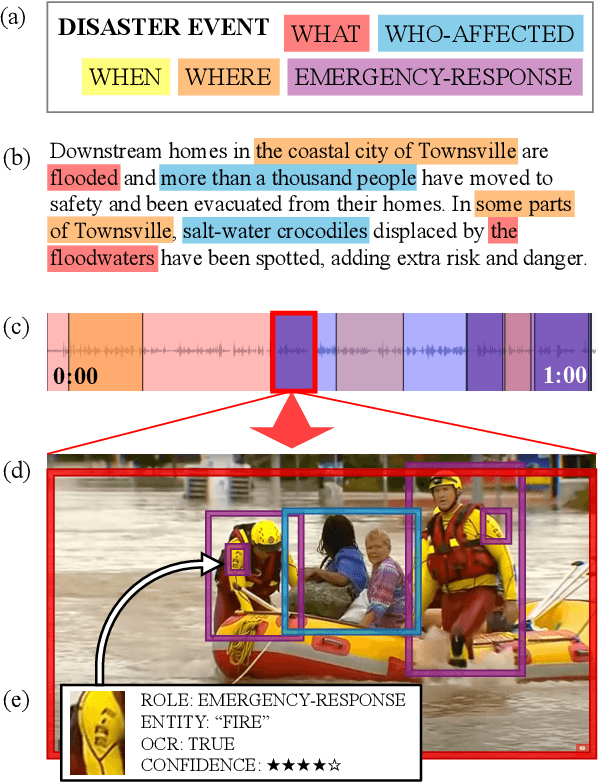

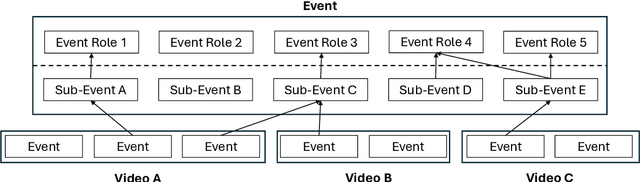
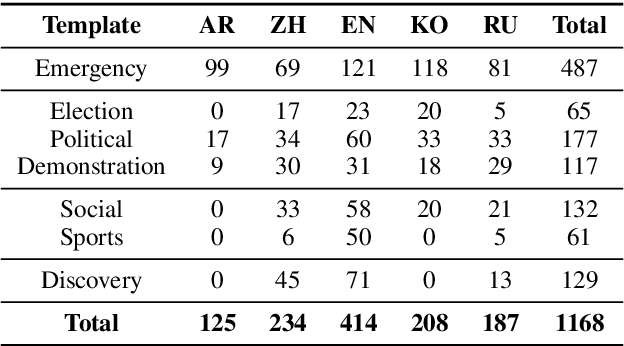
How are we able to learn about complex current events just from short snippets of video? While natural language enables straightforward ways to represent under-specified, partially observable events, visual data does not facilitate analogous methods and, consequently, introduces unique challenges in event understanding. With the growing prevalence of vision-capable AI agents, these systems must be able to model events from collections of unstructured video data. To tackle robust event modeling in multimodal settings, we introduce a multimodal formulation for partially-defined events and cast the extraction of these events as a three-stage span retrieval task. We propose a corresponding benchmark for this task, MultiVENT-G, that consists of 14.5 hours of densely annotated current event videos and 1,168 text documents, containing 22.8K labeled event-centric entities. We propose a collection of LLM-driven approaches to the task of multimodal event analysis, and evaluate them on MultiVENT-G. Results illustrate the challenges that abstract event understanding poses and demonstrates promise in event-centric video-language systems.
Core: Robust Factual Precision Scoring with Informative Sub-Claim Identification
Jul 04, 2024

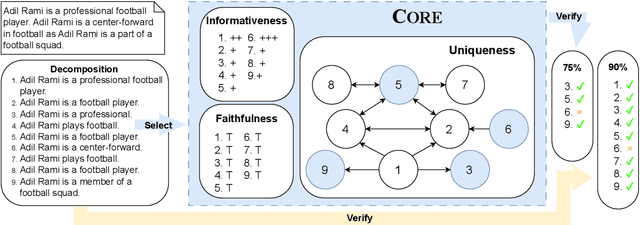

Hallucinations -- the generation of untrue claims -- pose a challenge to the application of large language models (LLMs) [1] thereby motivating the development of metrics to evaluate factual precision. We observe that popular metrics using the Decompose-Then-Verify framework, such as FActScore [2], can be manipulated by adding obvious or repetitive claims to artificially inflate scores. We expand the FActScore dataset to design and analyze factual precision metrics, demonstrating that models can be trained to achieve high scores under existing metrics through exploiting the issues we identify. This motivates our new customizable plug-and-play subclaim selection component called Core, which filters down individual subclaims according to their uniqueness and informativeness. Metrics augmented by Core are substantially more robust as shown in head-to-head comparisons. We release an evaluation framework supporting the modular use of Core (https://github.com/zipJiang/Core) and various decomposition strategies, and we suggest its adoption by the LLM community. [1] Hong et al., "The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models", arXiv:2404.05904v2 [cs.CL]. [2] Min et al., "FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation", arXiv:2305.14251v2 [cs.CL].