 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCore: Robust Factual Precision Scoring with Informative Sub-Claim Identification
Paper and Code


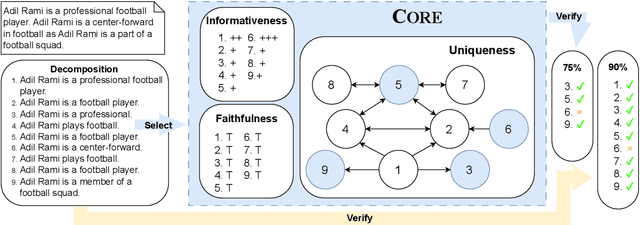

Hallucinations -- the generation of untrue claims -- pose a challenge to the application of large language models (LLMs) [1] thereby motivating the development of metrics to evaluate factual precision. We observe that popular metrics using the Decompose-Then-Verify framework, such as FActScore [2], can be manipulated by adding obvious or repetitive claims to artificially inflate scores. We expand the FActScore dataset to design and analyze factual precision metrics, demonstrating that models can be trained to achieve high scores under existing metrics through exploiting the issues we identify. This motivates our new customizable plug-and-play subclaim selection component called Core, which filters down individual subclaims according to their uniqueness and informativeness. Metrics augmented by Core are substantially more robust as shown in head-to-head comparisons. We release an evaluation framework supporting the modular use of Core (https://github.com/zipJiang/Core) and various decomposition strategies, and we suggest its adoption by the LLM community. [1] Hong et al., "The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models", arXiv:2404.05904v2 [cs.CL]. [2] Min et al., "FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation", arXiv:2305.14251v2 [cs.CL].