 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Scripts and Formats on LLM Numeracy
Jan 21, 2026Large language models (LLMs) have achieved impressive proficiency in basic arithmetic, rivaling human-level performance on standard numerical tasks. However, little attention has been given to how these models perform when numerical expressions deviate from the prevailing conventions present in their training corpora. In this work, we investigate numerical reasoning across a wide range of numeral scripts and formats. We show that LLM accuracy drops substantially when numerical inputs are rendered in underrepresented scripts or formats, despite the underlying mathematical reasoning being identical. We further demonstrate that targeted prompting strategies, such as few-shot prompting and explicit numeral mapping, can greatly narrow this gap. Our findings highlight an overlooked challenge in multilingual numerical reasoning and provide actionable insights for working with LLMs to reliably interpret, manipulate, and generate numbers across diverse numeral scripts and formatting styles.
On Finding Inconsistencies in Documents
Dec 21, 2025Professionals in academia, law, and finance audit their documents because inconsistencies can result in monetary, reputational, and scientific costs. Language models (LMs) have the potential to dramatically speed up this auditing process. To understand their abilities, we introduce a benchmark, FIND (Finding INconsistencies in Documents), where each example is a document with an inconsistency inserted manually by a domain expert. Despite the documents being long, technical, and complex, the best-performing model (gpt-5) recovered 64% of the inserted inconsistencies. Surprisingly, gpt-5 also found undiscovered inconsistencies present in the original documents. For example, on 50 arXiv papers, we judged 136 out of 196 of the model's suggestions to be legitimate inconsistencies missed by the original authors. However, despite these findings, even the best models miss almost half of the inconsistencies in FIND, demonstrating that inconsistency detection is still a challenging task.
No Free Labels: Limitations of LLM-as-a-Judge Without Human Grounding
Mar 07, 2025LLM-as-a-Judge is a framework that uses an LLM (large language model) to evaluate the quality of natural language text - typically text that is also generated by an LLM. This framework holds great promise due to its relative low-cost, ease of use, and strong correlations with human stylistic preferences. However, LLM Judges have been shown to exhibit biases that can distort their judgments. We evaluate how well LLM Judges can grade whether a given response to a conversational question is correct, an ability crucial to soundly estimating the overall response quality. To do so, we create and publicly release a human-annotated dataset with labels of correctness for 1,200 LLM responses. We source questions from a combination of existing datasets and a novel, challenging benchmark (BFF-Bench) created for this analysis. We demonstrate a strong connection between an LLM's ability to correctly answer a question and grade responses to that question. Although aggregate level statistics might imply a judge has high agreement with human annotators, it will struggle on the subset of questions it could not answer. To address this issue, we recommend a simple solution: provide the judge with a correct, human-written reference answer. We perform an in-depth analysis on how reference quality can affect the performance of an LLM Judge. We show that providing a weaker judge (e.g. Qwen 2.5 7B) with higher quality references reaches better agreement with human annotators than a stronger judge (e.g. GPT-4o) with synthetic references.
Core: Robust Factual Precision Scoring with Informative Sub-Claim Identification
Jul 04, 2024

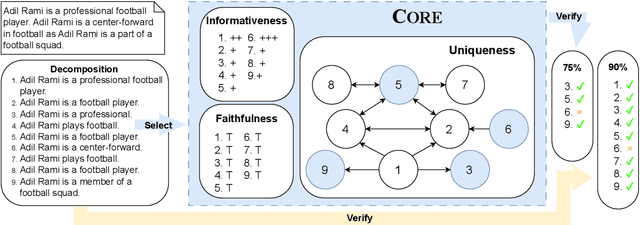

Hallucinations -- the generation of untrue claims -- pose a challenge to the application of large language models (LLMs) [1] thereby motivating the development of metrics to evaluate factual precision. We observe that popular metrics using the Decompose-Then-Verify framework, such as FActScore [2], can be manipulated by adding obvious or repetitive claims to artificially inflate scores. We expand the FActScore dataset to design and analyze factual precision metrics, demonstrating that models can be trained to achieve high scores under existing metrics through exploiting the issues we identify. This motivates our new customizable plug-and-play subclaim selection component called Core, which filters down individual subclaims according to their uniqueness and informativeness. Metrics augmented by Core are substantially more robust as shown in head-to-head comparisons. We release an evaluation framework supporting the modular use of Core (https://github.com/zipJiang/Core) and various decomposition strategies, and we suggest its adoption by the LLM community. [1] Hong et al., "The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models", arXiv:2404.05904v2 [cs.CL]. [2] Min et al., "FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation", arXiv:2305.14251v2 [cs.CL].
A Closer Look at Claim Decomposition
Mar 18, 2024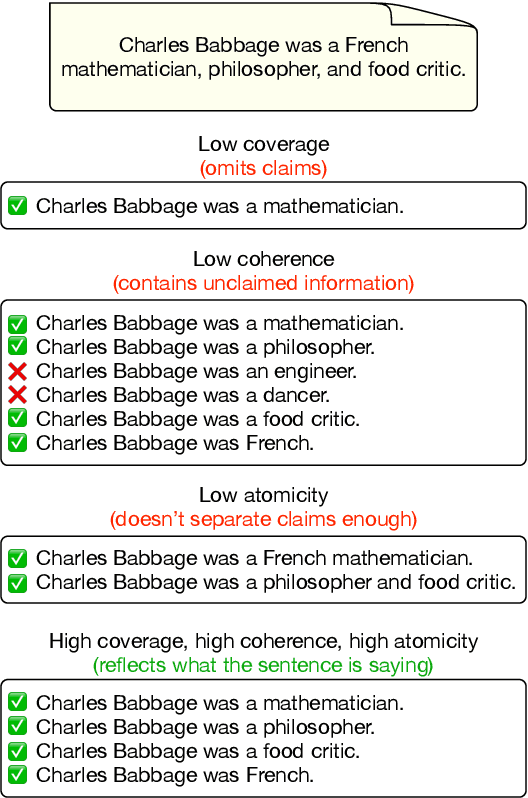

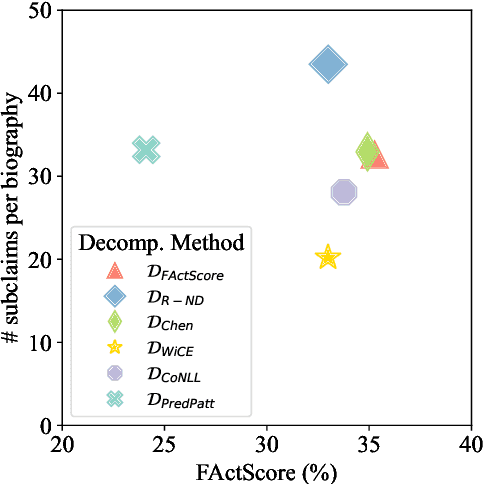
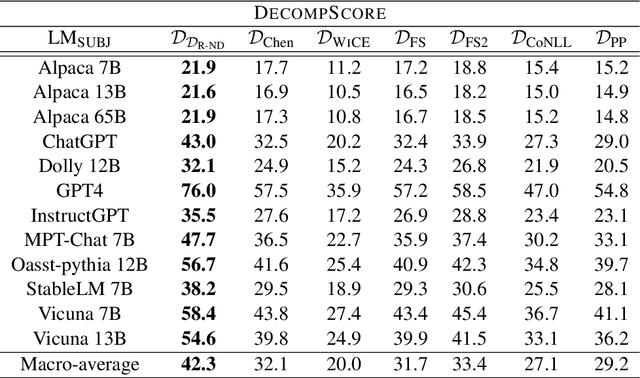
As generated text becomes more commonplace, it is increasingly important to evaluate how well-supported such text is by external knowledge sources. Many approaches for evaluating textual support rely on some method for decomposing text into its individual subclaims which are scored against a trusted reference. We investigate how various methods of claim decomposition -- especially LLM-based methods -- affect the result of an evaluation approach such as the recently proposed FActScore, finding that it is sensitive to the decomposition method used. This sensitivity arises because such metrics attribute overall textual support to the model that generated the text even though error can also come from the metric's decomposition step. To measure decomposition quality, we introduce an adaptation of FActScore, which we call DecompScore. We then propose an LLM-based approach to generating decompositions inspired by Bertrand Russell's theory of logical atomism and neo-Davidsonian semantics and demonstrate its improved decomposition quality over previous methods.
An Augmentation Strategy for Visually Rich Documents
Dec 22, 2022Many business workflows require extracting important fields from form-like documents (e.g. bank statements, bills of lading, purchase orders, etc.). Recent techniques for automating this task work well only when trained with large datasets. In this work we propose a novel data augmentation technique to improve performance when training data is scarce, e.g. 10-250 documents. Our technique, which we call FieldSwap, works by swapping out the key phrases of a source field with the key phrases of a target field to generate new synthetic examples of the target field for use in training. We demonstrate that this approach can yield 1-7 F1 point improvements in extraction performance.
Everything Is All It Takes: A Multipronged Strategy for Zero-Shot Cross-Lingual Information Extraction
Sep 14, 2021

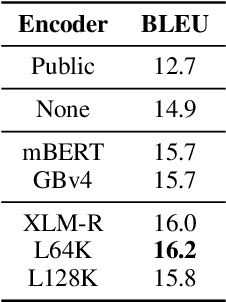

Zero-shot cross-lingual information extraction (IE) describes the construction of an IE model for some target language, given existing annotations exclusively in some other language, typically English. While the advance of pretrained multilingual encoders suggests an easy optimism of "train on English, run on any language", we find through a thorough exploration and extension of techniques that a combination of approaches, both new and old, leads to better performance than any one cross-lingual strategy in particular. We explore techniques including data projection and self-training, and how different pretrained encoders impact them. We use English-to-Arabic IE as our initial example, demonstrating strong performance in this setting for event extraction, named entity recognition, part-of-speech tagging, and dependency parsing. We then apply data projection and self-training to three tasks across eight target languages. Because no single set of techniques performs the best across all tasks, we encourage practitioners to explore various configurations of the techniques described in this work when seeking to improve on zero-shot training.
Gradual Fine-Tuning for Low-Resource Domain Adaptation
Mar 03, 2021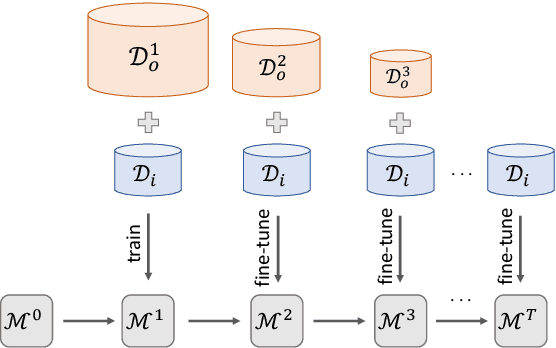
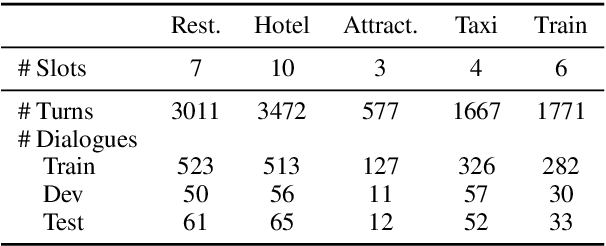
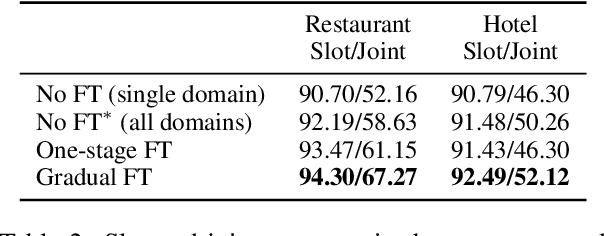
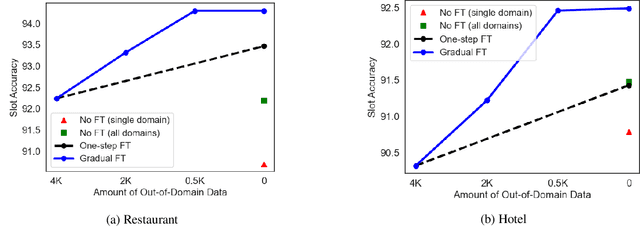
Fine-tuning is known to improve NLP models by adapting an initial model trained on more plentiful but less domain-salient examples to data in a target domain. Such domain adaptation is typically done using one stage of fine-tuning. We demonstrate that gradually fine-tuning in a multi-stage process can yield substantial further gains and can be applied without modifying the model or learning objective.
Reading the Manual: Event Extraction as Definition Comprehension
Dec 03, 2019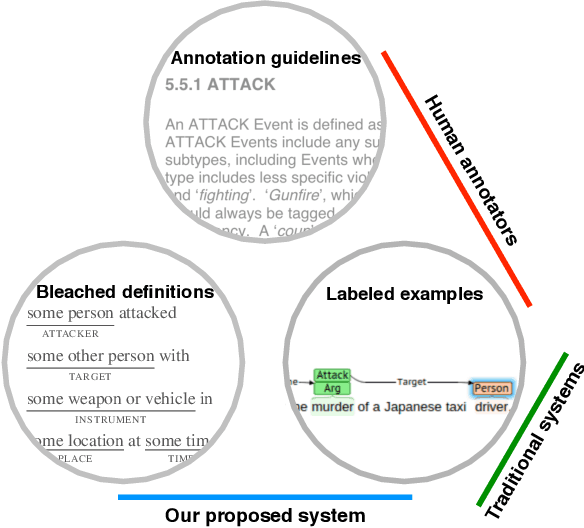
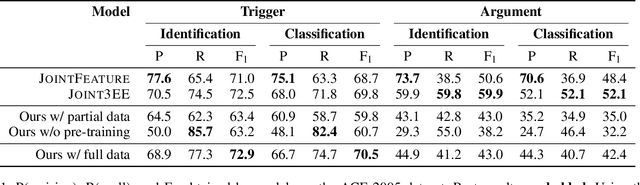
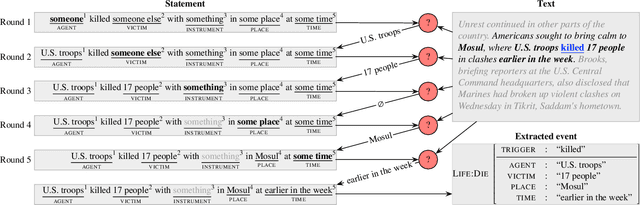
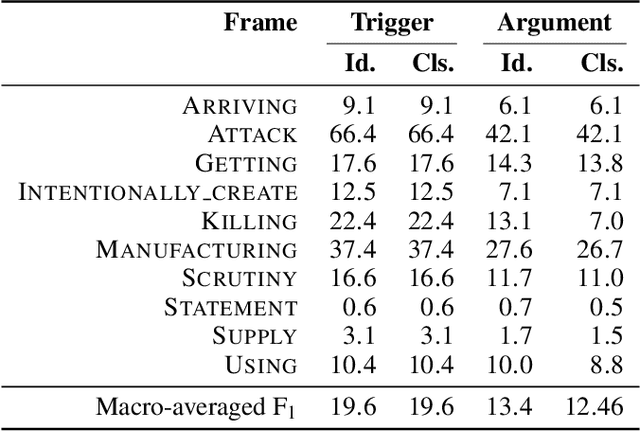
We propose a novel approach to event extraction that supplies models with \emph{bleached statements}: machine-readable natural language sentences that are based on annotation guidelines and that describe generic occurrences of events. We introduce a model that incrementally replaces the bleached arguments in a statement with responses obtained by querying text with the statement itself. Experimental results demonstrate that our model is able to extract events under closed ontologies and can generalize to unseen event types simply by reading new bleached statements.
Multi-Sentence Argument Linking
Nov 09, 2019
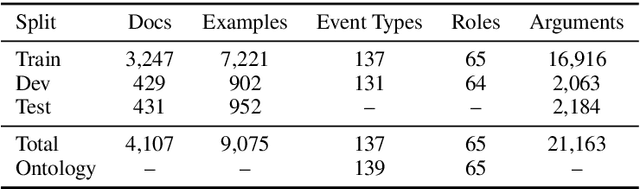
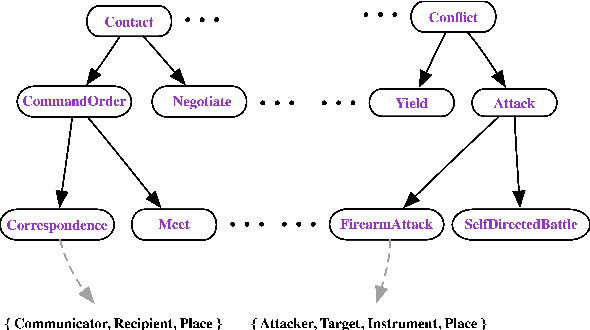
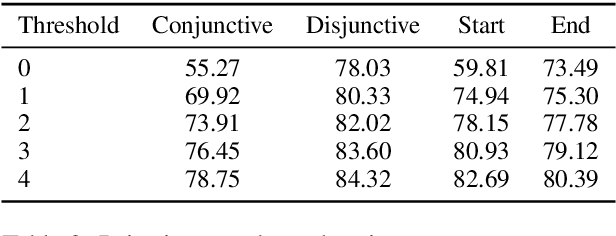
We introduce a dataset with annotated Roles Across Multiple Sentences (RAMS), consisting of over 9,000 annotated events. This enables the development of a novel span-based labeling framework that operates at the document level, which connects related ideas in sentence-level semantic role labeling and coreference resolution. We achieve 68.1 F1 on RAMS when given argument span boundaries and 73.2 F1 when also given gold event types. We additionally illustrate the applicability of the approach to the slot filling task in the Gun Violence Database.