 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverything Is All It Takes: A Multipronged Strategy for Zero-Shot Cross-Lingual Information Extraction
Sep 14, 2021


Zero-shot cross-lingual information extraction (IE) describes the construction of an IE model for some target language, given existing annotations exclusively in some other language, typically English. While the advance of pretrained multilingual encoders suggests an easy optimism of "train on English, run on any language", we find through a thorough exploration and extension of techniques that a combination of approaches, both new and old, leads to better performance than any one cross-lingual strategy in particular. We explore techniques including data projection and self-training, and how different pretrained encoders impact them. We use English-to-Arabic IE as our initial example, demonstrating strong performance in this setting for event extraction, named entity recognition, part-of-speech tagging, and dependency parsing. We then apply data projection and self-training to three tasks across eight target languages. Because no single set of techniques performs the best across all tasks, we encourage practitioners to explore various configurations of the techniques described in this work when seeking to improve on zero-shot training.
LOME: Large Ontology Multilingual Extraction
Jan 28, 2021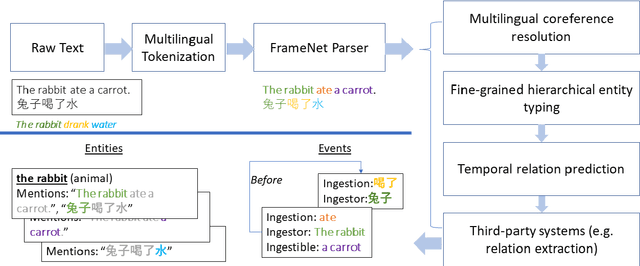
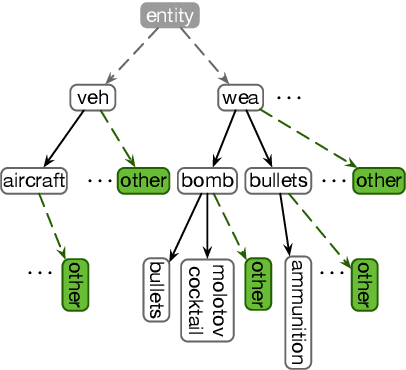
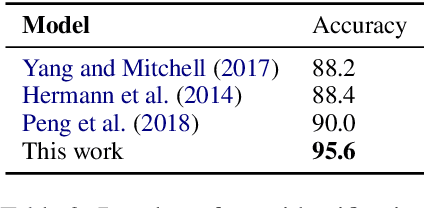
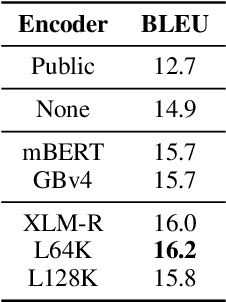
We present LOME, a system for performing multilingual information extraction. Given a text document as input, our core system identifies spans of textual entity and event mentions with a FrameNet (Baker et al., 1998) parser. It subsequently performs coreference resolution, fine-grained entity typing, and temporal relation prediction between events. By doing so, the system constructs an event and entity focused knowledge graph. We can further apply third-party modules for other types of annotation, like relation extraction. Our (multilingual) first-party modules either outperform or are competitive with the (monolingual) state-of-the-art. We achieve this through the use of multilingual encoders like XLM-R (Conneau et al., 2020) and leveraging multilingual training data. LOME is available as a Docker container on Docker Hub. In addition, a lightweight version of the system is accessible as a web demo.
Low-Resource Contextual Topic Identification on Speech
Sep 28, 2018


In topic identification (topic ID) on real-world unstructured audio, an audio instance of variable topic shifts is first broken into sequential segments, and each segment is independently classified. We first present a general purpose method for topic ID on spoken segments in low-resource languages, using a cascade of universal acoustic modeling, translation lexicons to English, and English-language topic classification. Next, instead of classifying each segment independently, we demonstrate that exploring the contextual dependencies across sequential segments can provide large improvements. In particular, we propose an attention-based contextual model which is able to leverage the contexts in a selective manner. We test both our contextual and non-contextual models on four LORELEI languages, and on all but one our attention-based contextual model significantly outperforms the context-independent models.
Automatic Speech Recognition and Topic Identification for Almost-Zero-Resource Languages
Jun 18, 2018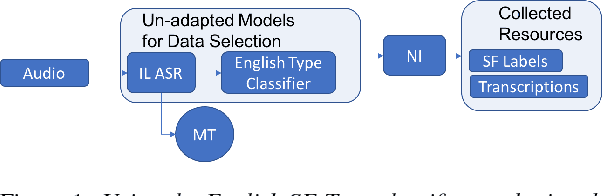
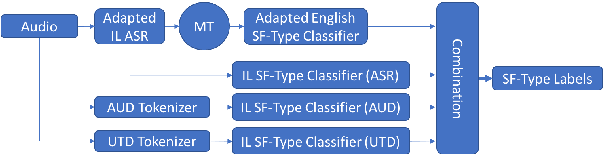
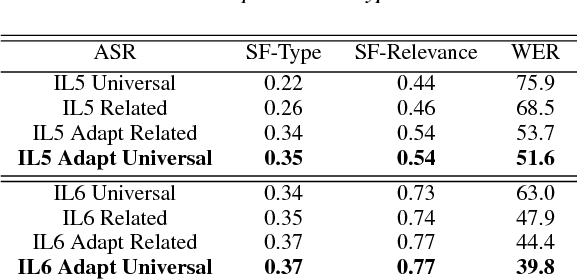
Automatic speech recognition (ASR) systems often need to be developed for extremely low-resource languages to serve end-uses such as audio content categorization and search. While universal phone recognition is natural to consider when no transcribed speech is available to train an ASR system in a language, adapting universal phone models using very small amounts (minutes rather than hours) of transcribed speech also needs to be studied, particularly with state-of-the-art DNN-based acoustic models. The DARPA LORELEI program provides a framework for such very-low-resource ASR studies, and provides an extrinsic metric for evaluating ASR performance in a humanitarian assistance, disaster relief setting. This paper presents our Kaldi-based systems for the program, which employ a universal phone modeling approach to ASR, and describes recipes for very rapid adaptation of this universal ASR system. The results we obtain significantly outperform results obtained by many competing approaches on the NIST LoReHLT 2017 Evaluation datasets.
Topic Identification for Speech without ASR
Jul 11, 2017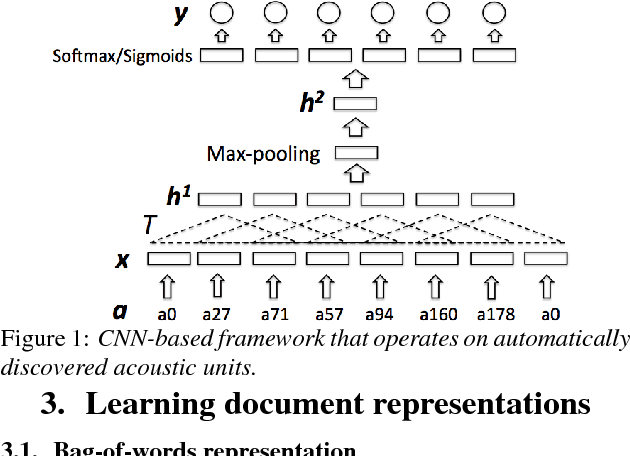

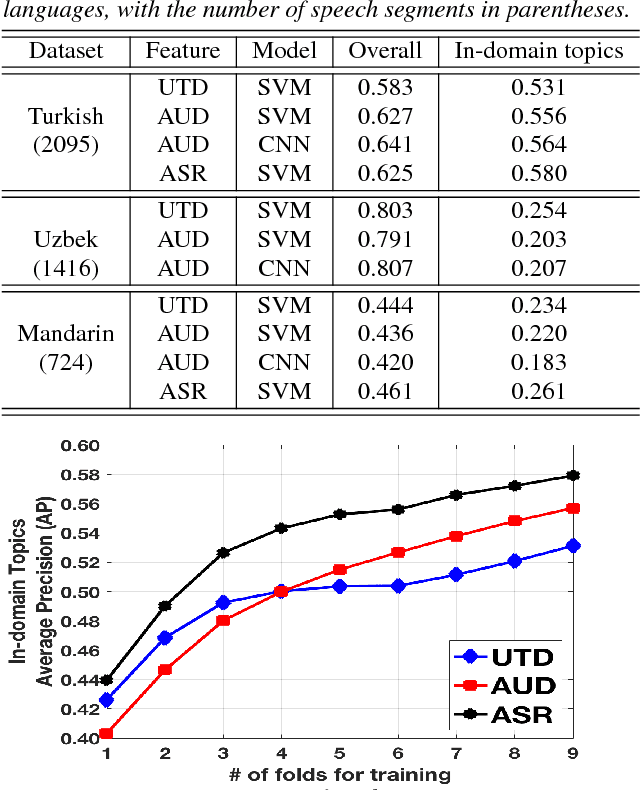
Modern topic identification (topic ID) systems for speech use automatic speech recognition (ASR) to produce speech transcripts, and perform supervised classification on such ASR outputs. However, under resource-limited conditions, the manually transcribed speech required to develop standard ASR systems can be severely limited or unavailable. In this paper, we investigate alternative unsupervised solutions to obtaining tokenizations of speech in terms of a vocabulary of automatically discovered word-like or phoneme-like units, without depending on the supervised training of ASR systems. Moreover, using automatic phoneme-like tokenizations, we demonstrate that a convolutional neural network based framework for learning spoken document representations provides competitive performance compared to a standard bag-of-words representation, as evidenced by comprehensive topic ID evaluations on both single-label and multi-label classification tasks.
Interactive Knowledge Base Population
May 31, 2015Most work on building knowledge bases has focused on collecting entities and facts from as large a collection of documents as possible. We argue for and describe a new paradigm where the focus is on a high-recall extraction over a small collection of documents under the supervision of a human expert, that we call Interactive Knowledge Base Population (IKBP).