 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegaWika 2: A More Comprehensive Multilingual Collection of Articles and their Sources
Aug 05, 2025We introduce MegaWika 2, a large, multilingual dataset of Wikipedia articles with their citations and scraped web sources; articles are represented in a rich data structure, and scraped source texts are stored inline with precise character offsets of their citations in the article text. MegaWika 2 is a major upgrade from the original MegaWika, spanning six times as many articles and twice as many fully scraped citations. Both MegaWika and MegaWika 2 support report generation research ; whereas MegaWika also focused on supporting question answering and retrieval applications, MegaWika 2 is designed to support fact checking and analyses across time and language.
How Grounded is Wikipedia? A Study on Structured Evidential Support
Jun 14, 2025Wikipedia is a critical resource for modern NLP, serving as a rich repository of up-to-date and citation-backed information on a wide variety of subjects. The reliability of Wikipedia -- its groundedness in its cited sources -- is vital to this purpose. This work provides a quantitative analysis of the extent to which Wikipedia *is* so grounded and of how readily grounding evidence may be retrieved. To this end, we introduce PeopleProfiles -- a large-scale, multi-level dataset of claim support annotations on Wikipedia articles of notable people. We show that roughly 20% of claims in Wikipedia *lead* sections are unsupported by the article body; roughly 27% of annotated claims in the article *body* are unsupported by their (publicly accessible) cited sources; and >80% of lead claims cannot be traced to these sources via annotated body evidence. Further, we show that recovery of complex grounding evidence for claims that *are* supported remains a challenge for standard retrieval methods.
CLAIMCHECK: How Grounded are LLM Critiques of Scientific Papers?
Mar 27, 2025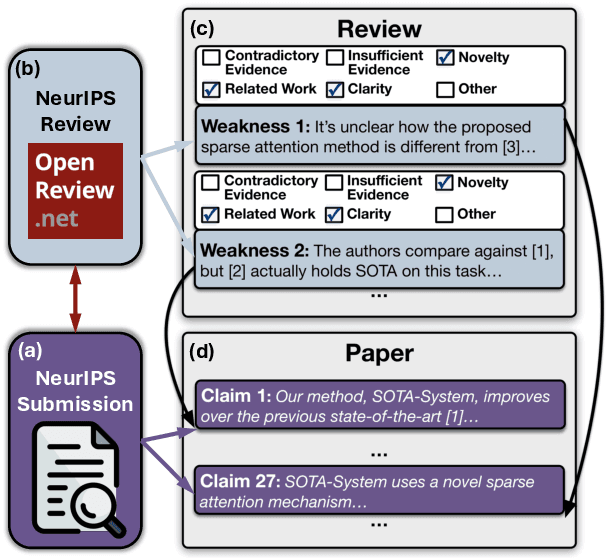
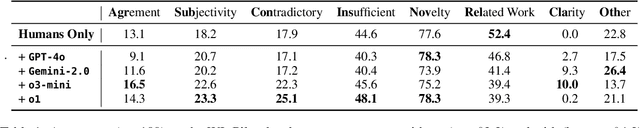
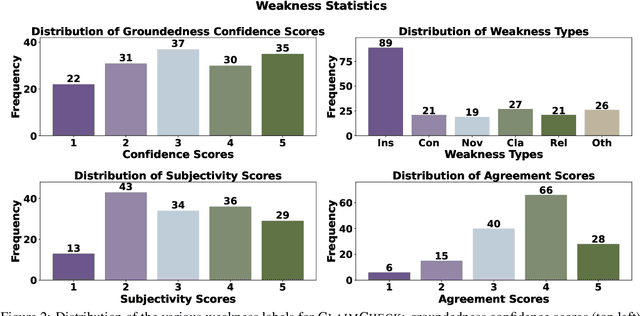
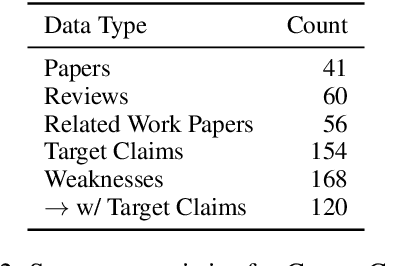
A core part of scientific peer review involves providing expert critiques that directly assess the scientific claims a paper makes. While it is now possible to automatically generate plausible (if generic) reviews, ensuring that these reviews are sound and grounded in the papers' claims remains challenging. To facilitate LLM benchmarking on these challenges, we introduce CLAIMCHECK, an annotated dataset of NeurIPS 2023 and 2024 submissions and reviews mined from OpenReview. CLAIMCHECK is richly annotated by ML experts for weakness statements in the reviews and the paper claims that they dispute, as well as fine-grained labels of the validity, objectivity, and type of the identified weaknesses. We benchmark several LLMs on three claim-centric tasks supported by CLAIMCHECK, requiring models to (1) associate weaknesses with the claims they dispute, (2) predict fine-grained labels for weaknesses and rewrite the weaknesses to enhance their specificity, and (3) verify a paper's claims with grounded reasoning. Our experiments reveal that cutting-edge LLMs, while capable of predicting weakness labels in (2), continue to underperform relative to human experts on all other tasks.
LOME: Large Ontology Multilingual Extraction
Jan 28, 2021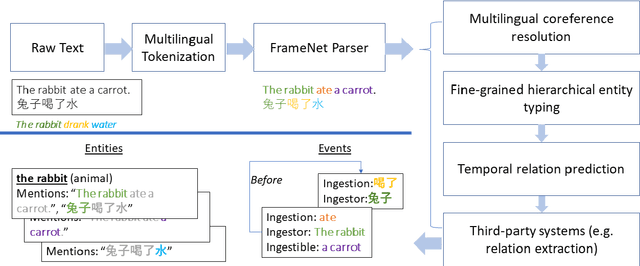
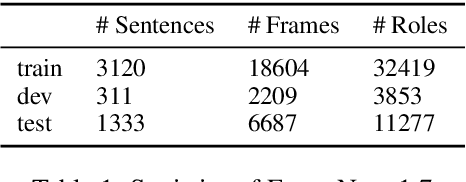
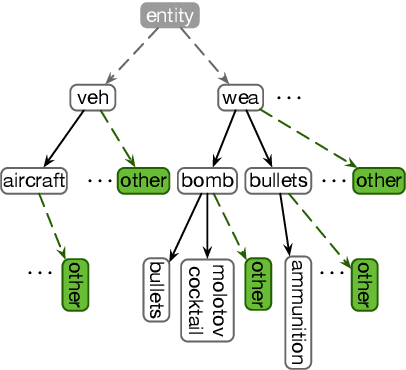
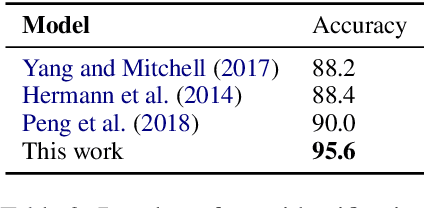
We present LOME, a system for performing multilingual information extraction. Given a text document as input, our core system identifies spans of textual entity and event mentions with a FrameNet (Baker et al., 1998) parser. It subsequently performs coreference resolution, fine-grained entity typing, and temporal relation prediction between events. By doing so, the system constructs an event and entity focused knowledge graph. We can further apply third-party modules for other types of annotation, like relation extraction. Our (multilingual) first-party modules either outperform or are competitive with the (monolingual) state-of-the-art. We achieve this through the use of multilingual encoders like XLM-R (Conneau et al., 2020) and leveraging multilingual training data. LOME is available as a Docker container on Docker Hub. In addition, a lightweight version of the system is accessible as a web demo.
On Measuring Social Biases in Sentence Encoders
Mar 25, 2019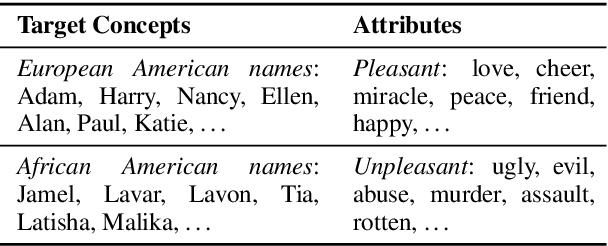
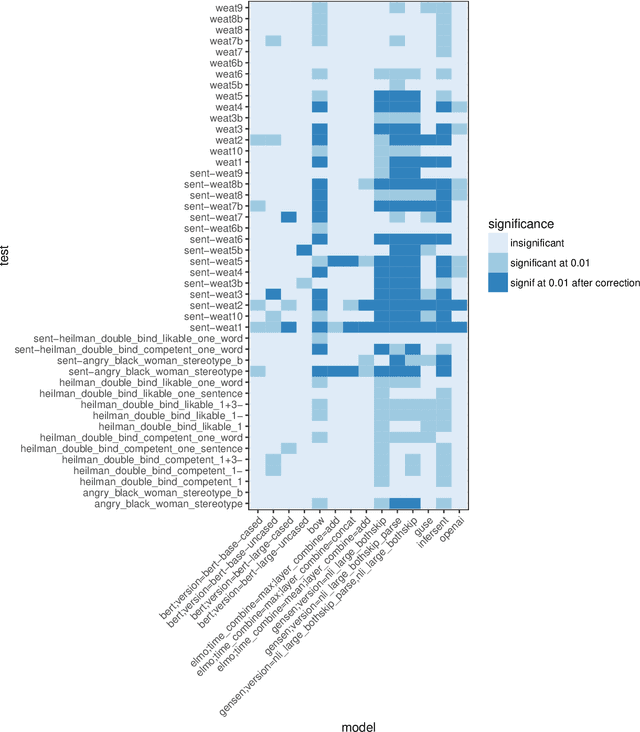

The Word Embedding Association Test shows that GloVe and word2vec word embeddings exhibit human-like implicit biases based on gender, race, and other social constructs (Caliskan et al., 2017). Meanwhile, research on learning reusable text representations has begun to explore sentence-level texts, with some sentence encoders seeing enthusiastic adoption. Accordingly, we extend the Word Embedding Association Test to measure bias in sentence encoders. We then test several sentence encoders, including state-of-the-art methods such as ELMo and BERT, for the social biases studied in prior work and two important biases that are difficult or impossible to test at the word level. We observe mixed results including suspicious patterns of sensitivity that suggest the test's assumptions may not hold in general. We conclude by proposing directions for future work on measuring bias in sentence encoders.
Streaming Word Embeddings with the Space-Saving Algorithm
Apr 24, 2017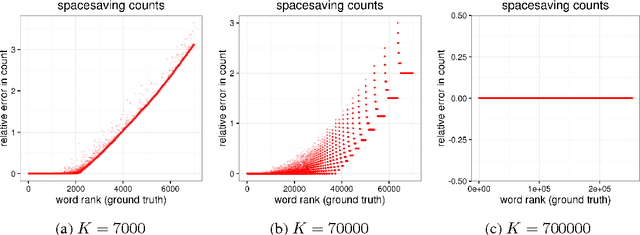

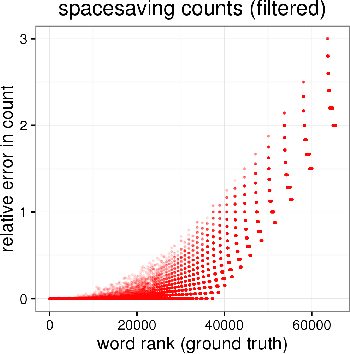
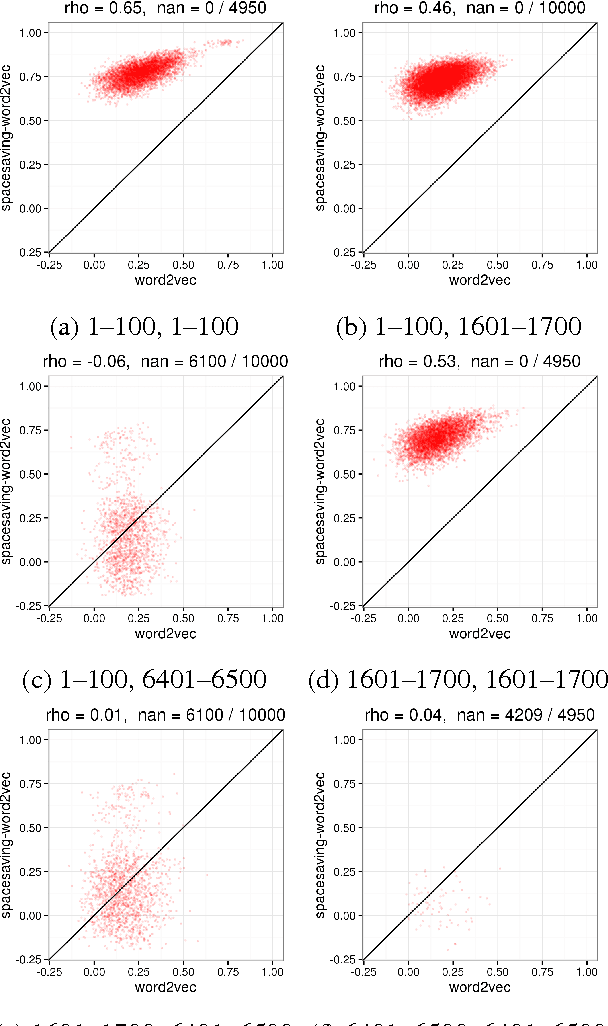
We develop a streaming (one-pass, bounded-memory) word embedding algorithm based on the canonical skip-gram with negative sampling algorithm implemented in word2vec. We compare our streaming algorithm to word2vec empirically by measuring the cosine similarity between word pairs under each algorithm and by applying each algorithm in the downstream task of hashtag prediction on a two-month interval of the Twitter sample stream. We then discuss the results of these experiments, concluding they provide partial validation of our approach as a streaming replacement for word2vec. Finally, we discuss potential failure modes and suggest directions for future work.
Analysis of Morphology in Topic Modeling
Aug 13, 2016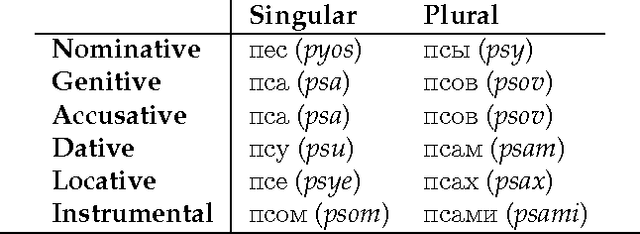


Topic models make strong assumptions about their data. In particular, different words are implicitly assumed to have different meanings: topic models are often used as human-interpretable dimensionality reductions and a proliferation of words with identical meanings would undermine the utility of the top-$m$ word list representation of a topic. Though a number of authors have added preprocessing steps such as lemmatization to better accommodate these assumptions, the effects of such data massaging have not been publicly studied. We make first steps toward elucidating the role of morphology in topic modeling by testing the effect of lemmatization on the interpretability of a latent Dirichlet allocation (LDA) model. Using a word intrusion evaluation, we quantitatively demonstrate that lemmatization provides a significant benefit to the interpretability of a model learned on Wikipedia articles in a morphologically rich language.