Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Word Embeddings with the Space-Saving Algorithm
Paper and Code
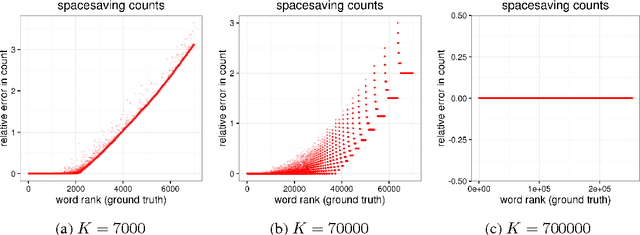

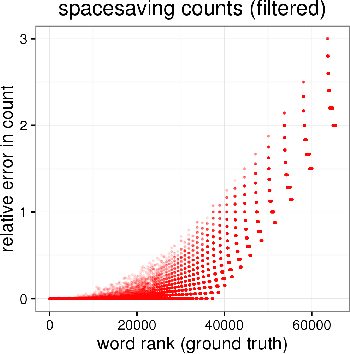
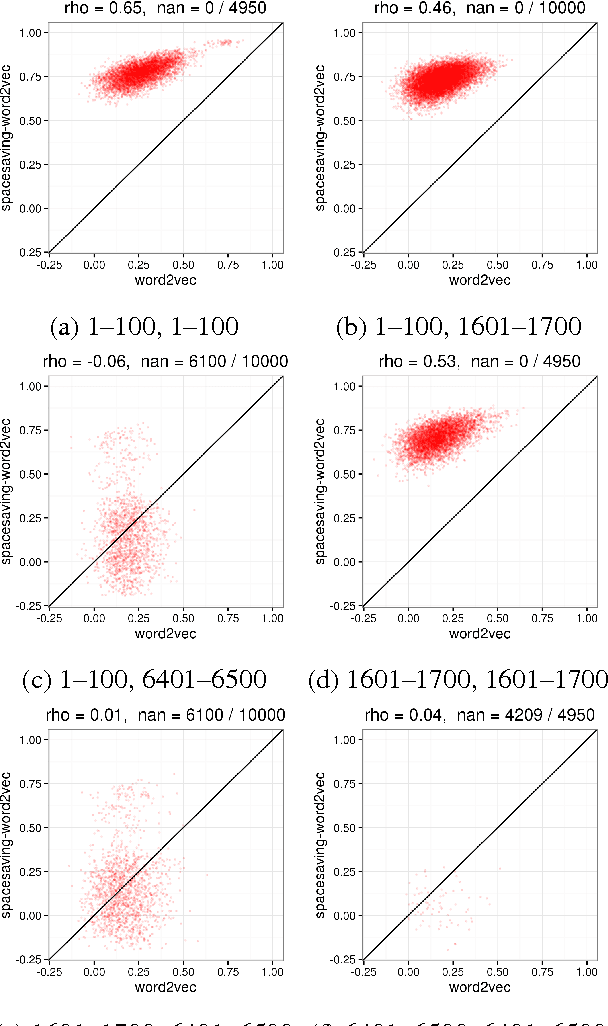
We develop a streaming (one-pass, bounded-memory) word embedding algorithm based on the canonical skip-gram with negative sampling algorithm implemented in word2vec. We compare our streaming algorithm to word2vec empirically by measuring the cosine similarity between word pairs under each algorithm and by applying each algorithm in the downstream task of hashtag prediction on a two-month interval of the Twitter sample stream. We then discuss the results of these experiments, concluding they provide partial validation of our approach as a streaming replacement for word2vec. Finally, we discuss potential failure modes and suggest directions for future work.
* 16 pages
View paper on