 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAMuS: Frames Across Multiple Sources
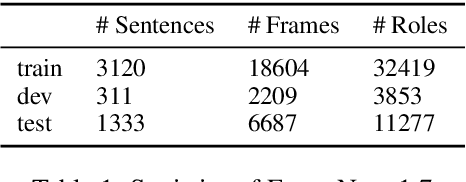
Nov 09, 2023Understanding event descriptions is a central aspect of language processing, but current approaches focus overwhelmingly on single sentences or documents. Aggregating information about an event \emph{across documents} can offer a much richer understanding. To this end, we present FAMuS, a new corpus of Wikipedia passages that \emph{report} on some event, paired with underlying, genre-diverse (non-Wikipedia) \emph{source} articles for the same event. Events and (cross-sentence) arguments in both report and source are annotated against FrameNet, providing broad coverage of different event types. We present results on two key event understanding tasks enabled by FAMuS: \emph{source validation} -- determining whether a document is a valid source for a target report event -- and \emph{cross-document argument extraction} -- full-document argument extraction for a target event from both its report and the correct source article. We release both FAMuS and our models to support further research.
MegaWika: Millions of reports and their sources across 50 diverse languages
Jul 13, 2023To foster the development of new models for collaborative AI-assisted report generation, we introduce MegaWika, consisting of 13 million Wikipedia articles in 50 diverse languages, along with their 71 million referenced source materials. We process this dataset for a myriad of applications, going beyond the initial Wikipedia citation extraction and web scraping of content, including translating non-English articles for cross-lingual applications and providing FrameNet parses for automated semantic analysis. MegaWika is the largest resource for sentence-level report generation and the only report generation dataset that is multilingual. We manually analyze the quality of this resource through a semantically stratified sample. Finally, we provide baseline results and trained models for crucial steps in automated report generation: cross-lingual question answering and citation retrieval.
PRESTO: A Multilingual Dataset for Parsing Realistic Task-Oriented Dialogs
Mar 17, 2023



Research interest in task-oriented dialogs has increased as systems such as Google Assistant, Alexa and Siri have become ubiquitous in everyday life. However, the impact of academic research in this area has been limited by the lack of datasets that realistically capture the wide array of user pain points. To enable research on some of the more challenging aspects of parsing realistic conversations, we introduce PRESTO, a public dataset of over 550K contextual multilingual conversations between humans and virtual assistants. PRESTO contains a diverse array of challenges that occur in real-world NLU tasks such as disfluencies, code-switching, and revisions. It is the only large scale human generated conversational parsing dataset that provides structured context such as a user's contacts and lists for each example. Our mT5 model based baselines demonstrate that the conversational phenomenon present in PRESTO are challenging to model, which is further pronounced in a low-resource setup.
On Event Individuation for Document-Level Information Extraction
Dec 19, 2022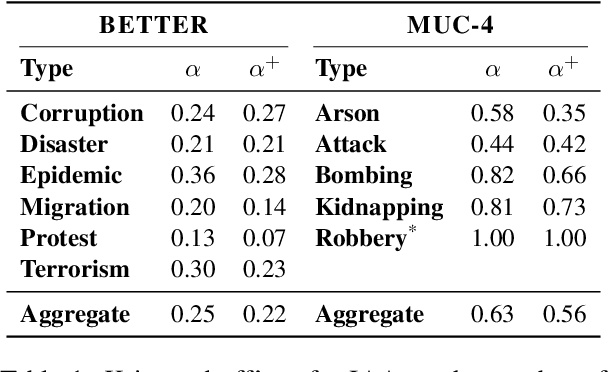

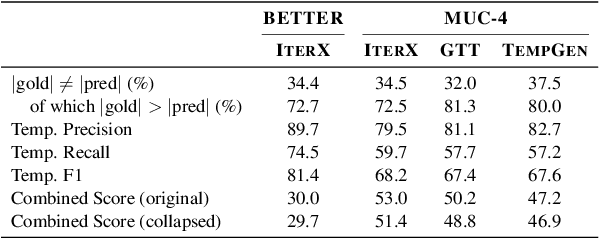
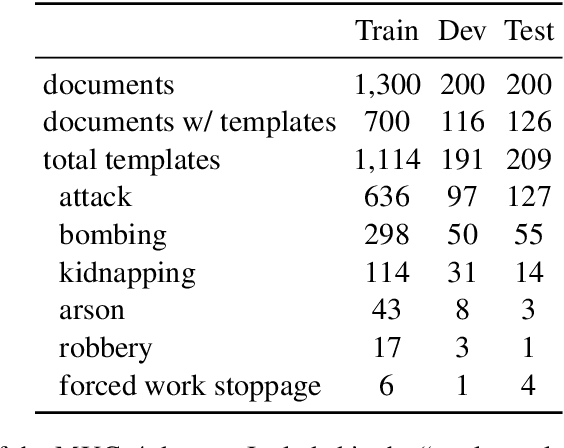
As information extraction (IE) systems have grown more capable at whole-document extraction, the classic task of \emph{template filling} has seen renewed interest as a benchmark for evaluating them. In this position paper, we call into question the suitability of template filling for this purpose. We argue that the task demands definitive answers to thorny questions of \emph{event individuation} -- the problem of distinguishing distinct events -- about which even human experts disagree. We show through annotation studies and error analysis that this raises concerns about the usefulness of template filling evaluation metrics, the quality of datasets for the task, and the ability of models to learn it. Finally, we consider possible solutions.
LOME: Large Ontology Multilingual Extraction
Jan 28, 2021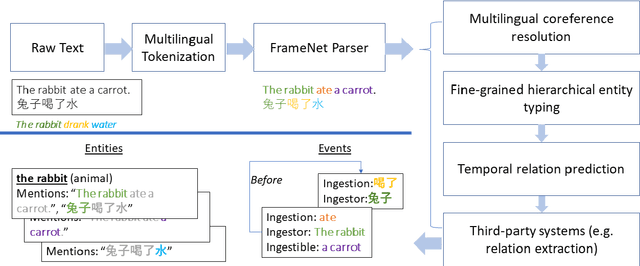
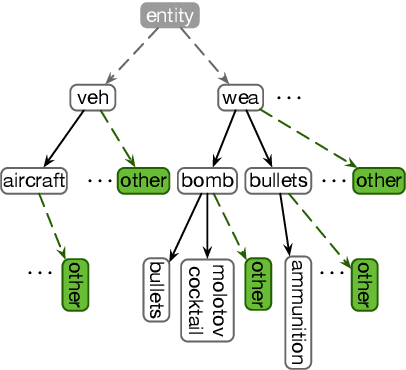
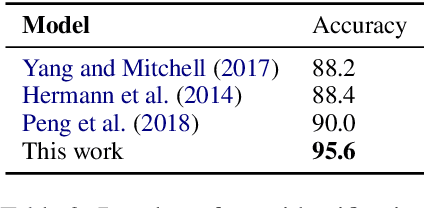
We present LOME, a system for performing multilingual information extraction. Given a text document as input, our core system identifies spans of textual entity and event mentions with a FrameNet (Baker et al., 1998) parser. It subsequently performs coreference resolution, fine-grained entity typing, and temporal relation prediction between events. By doing so, the system constructs an event and entity focused knowledge graph. We can further apply third-party modules for other types of annotation, like relation extraction. Our (multilingual) first-party modules either outperform or are competitive with the (monolingual) state-of-the-art. We achieve this through the use of multilingual encoders like XLM-R (Conneau et al., 2020) and leveraging multilingual training data. LOME is available as a Docker container on Docker Hub. In addition, a lightweight version of the system is accessible as a web demo.
Hinting Semantic Parsing with Statistical Word Sense Disambiguation
Jul 06, 2020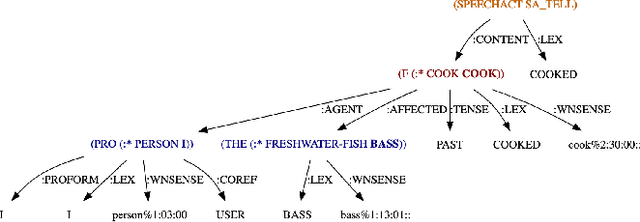
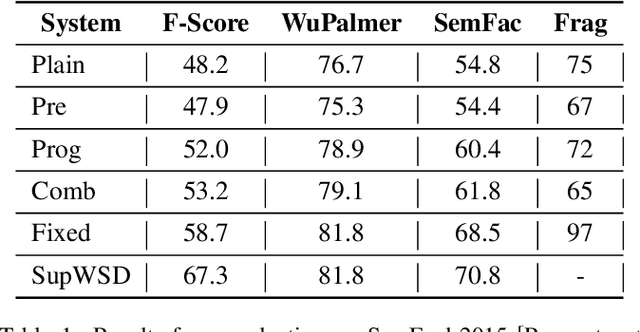
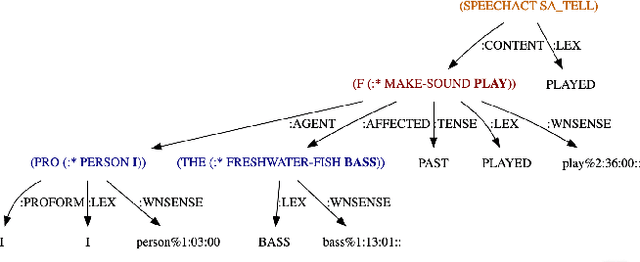

The task of Semantic Parsing can be approximated as a transformation of an utterance into a logical form graph where edges represent semantic roles and nodes represent word senses. The resulting representation should be capture the meaning of the utterance and be suitable for reasoning. Word senses and semantic roles are interdependent, meaning errors in assigning word senses can cause errors in assigning semantic roles and vice versa. While statistical approaches to word sense disambiguation outperform logical, rule-based semantic parsers for raw word sense assignment, these statistical word sense disambiguation systems do not produce the rich role structure or detailed semantic representation of the input. In this work, we provide hints from a statistical WSD system to guide a logical semantic parser to produce better semantic type assignments while maintaining the soundness of the resulting logical forms. We observe an improvement of up to 10.5% in F-score, however we find that this improvement comes at a cost to the structural integrity of the parse
The Universal Decompositional Semantics Dataset and Decomp Toolkit
Sep 30, 2019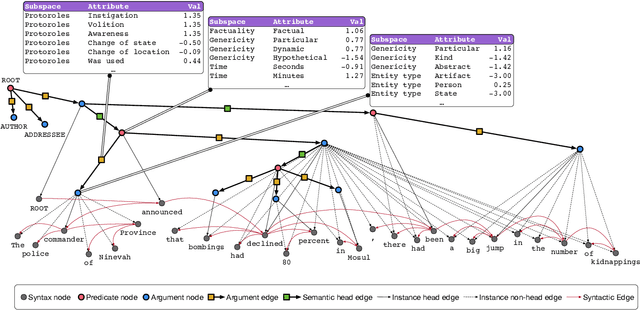
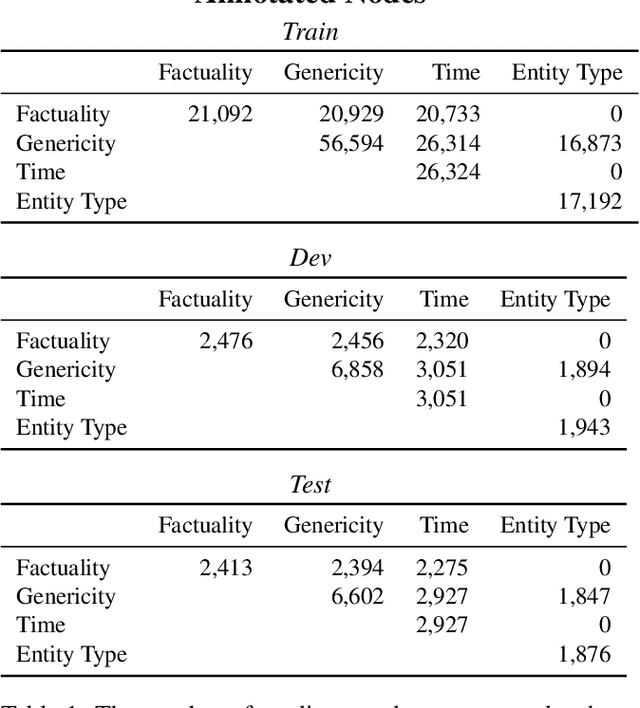

We present the Universal Decompositional Semantics (UDS) dataset (v1.0), which is bundled with the Decomp toolkit (v0.1). UDS1.0 unifies five high-quality, decompositional semantics-aligned annotation sets within a single semantic graph specification---with graph structures defined by the predicative patterns produced by the PredPatt tool and real-valued node and edge attributes constructed using sophisticated normalization procedures. The Decomp toolkit provides a suite of Python 3 tools for querying UDS graphs using SPARQL. Both UDS1.0 and Decomp0.1 are publicly available at http://decomp.io.