 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are Highly Aligned with Human Ratings of Emotional Stimuli
Aug 19, 2025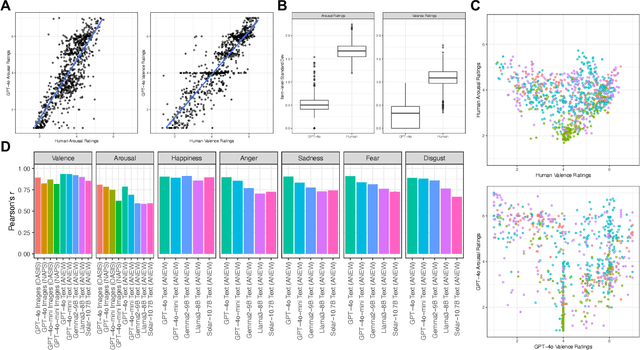
Emotions exert an immense influence over human behavior and cognition in both commonplace and high-stress tasks. Discussions of whether or how to integrate large language models (LLMs) into everyday life (e.g., acting as proxies for, or interacting with, human agents), should be informed by an understanding of how these tools evaluate emotionally loaded stimuli or situations. A model's alignment with human behavior in these cases can inform the effectiveness of LLMs for certain roles or interactions. To help build this understanding, we elicited ratings from multiple popular LLMs for datasets of words and images that were previously rated for their emotional content by humans. We found that when performing the same rating tasks, GPT-4o responded very similarly to human participants across modalities, stimuli and most rating scales (r = 0.9 or higher in many cases). However, arousal ratings were less well aligned between human and LLM raters, while happiness ratings were most highly aligned. Overall LLMs aligned better within a five-category (happiness, anger, sadness, fear, disgust) emotion framework than within a two-dimensional (arousal and valence) organization. Finally, LLM ratings were substantially more homogenous than human ratings. Together these results begin to describe how LLM agents interpret emotional stimuli and highlight similarities and differences among biological and artificial intelligence in key behavioral domains.
Turing Representational Similarity Analysis (RSA): A Flexible Method for Measuring Alignment Between Human and Artificial Intelligence
Nov 30, 2024As we consider entrusting Large Language Models (LLMs) with key societal and decision-making roles, measuring their alignment with human cognition becomes critical. This requires methods that can assess how these systems represent information and facilitate comparisons to human understanding across diverse tasks. To meet this need, we developed Turing Representational Similarity Analysis (RSA), a method that uses pairwise similarity ratings to quantify alignment between AIs and humans. We tested this approach on semantic alignment across text and image modalities, measuring how different Large Language and Vision Language Model (LLM and VLM) similarity judgments aligned with human responses at both group and individual levels. GPT-4o showed the strongest alignment with human performance among the models we tested, particularly when leveraging its text processing capabilities rather than image processing, regardless of the input modality. However, no model we studied adequately captured the inter-individual variability observed among human participants. This method helped uncover certain hyperparameters and prompts that could steer model behavior to have more or less human-like qualities at an inter-individual or group level. Turing RSA enables the efficient and flexible quantification of human-AI alignment and complements existing accuracy-based benchmark tasks. We demonstrate its utility across multiple modalities (words, sentences, images) for understanding how LLMs encode knowledge and for examining representational alignment with human cognition.
A Broad-Coverage Deep Semantic Lexicon for Verbs
Jul 06, 2020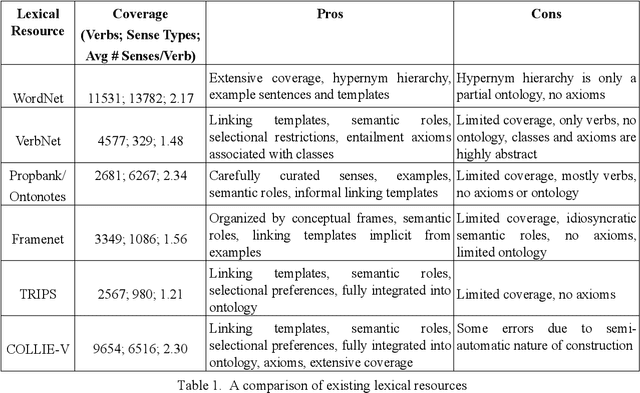

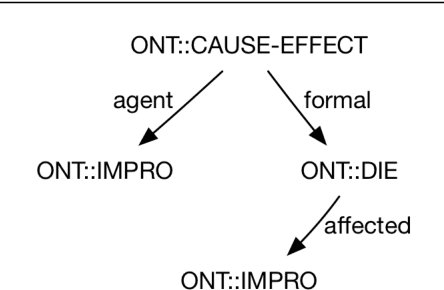
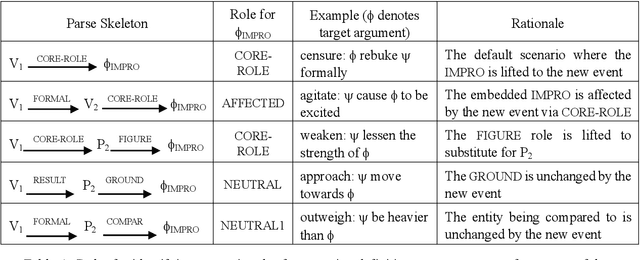
Progress on deep language understanding is inhibited by the lack of a broad coverage lexicon that connects linguistic behavior to ontological concepts and axioms. We have developed COLLIE-V, a deep lexical resource for verbs, with the coverage of WordNet and syntactic and semantic details that meet or exceed existing resources. Bootstrapping from a hand-built lexicon and ontology, new ontological concepts and lexical entries, together with semantic role preferences and entailment axioms, are automatically derived by combining multiple constraints from parsing dictionary definitions and examples. We evaluated the accuracy of the technique along a number of different dimensions and were able to obtain high accuracy in deriving new concepts and lexical entries. COLLIE-V is publicly available.
Hinting Semantic Parsing with Statistical Word Sense Disambiguation
Jul 06, 2020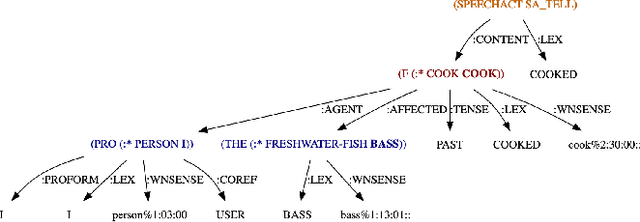
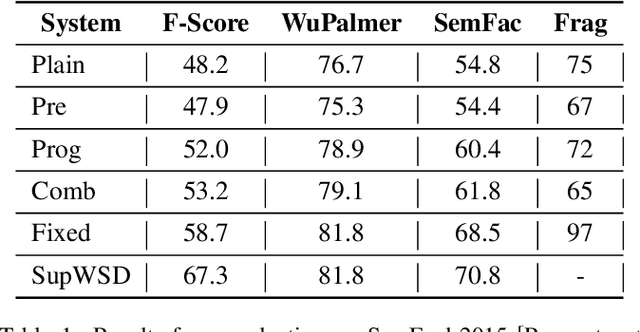
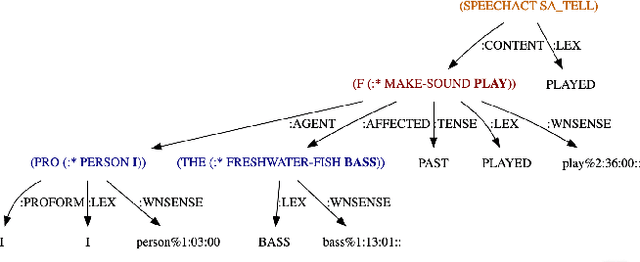

The task of Semantic Parsing can be approximated as a transformation of an utterance into a logical form graph where edges represent semantic roles and nodes represent word senses. The resulting representation should be capture the meaning of the utterance and be suitable for reasoning. Word senses and semantic roles are interdependent, meaning errors in assigning word senses can cause errors in assigning semantic roles and vice versa. While statistical approaches to word sense disambiguation outperform logical, rule-based semantic parsers for raw word sense assignment, these statistical word sense disambiguation systems do not produce the rich role structure or detailed semantic representation of the input. In this work, we provide hints from a statistical WSD system to guide a logical semantic parser to produce better semantic type assignments while maintaining the soundness of the resulting logical forms. We observe an improvement of up to 10.5% in F-score, however we find that this improvement comes at a cost to the structural integrity of the parse
#MeToo on Campus: Studying College Sexual Assault at Scale Using Data Reported on Social Media
Jan 16, 2020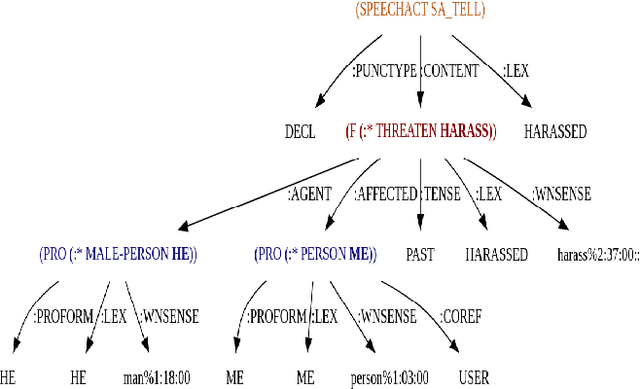
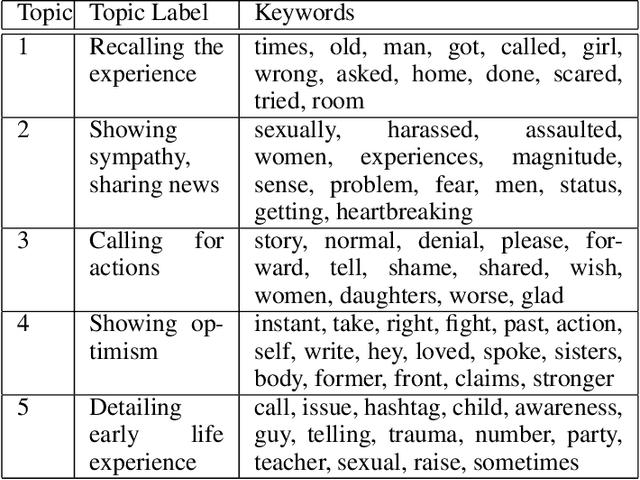
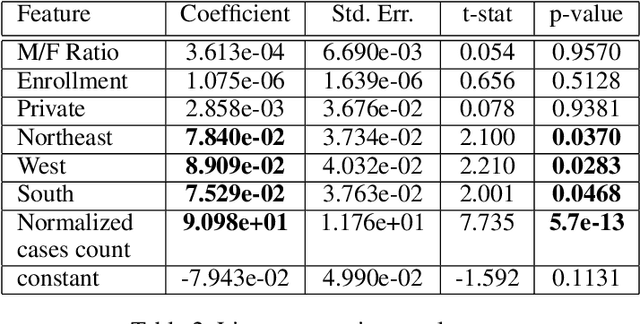
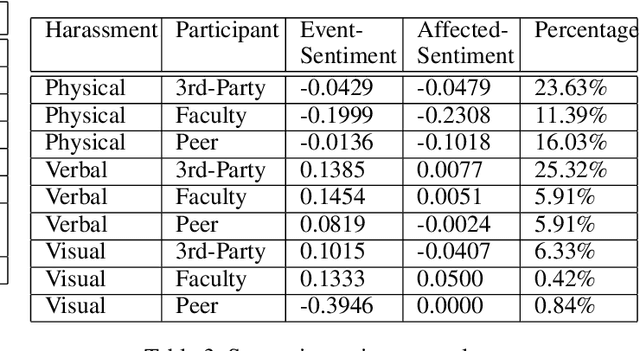
Recently, the emergence of the #MeToo trend on social media has empowered thousands of people to share their own sexual harassment experiences. This viral trend, in conjunction with the massive personal information and content available on Twitter, presents a promising opportunity to extract data driven insights to complement the ongoing survey based studies about sexual harassment in college. In this paper, we analyze the influence of the #MeToo trend on a pool of college followers. The results show that the majority of topics embedded in those #MeToo tweets detail sexual harassment stories, and there exists a significant correlation between the prevalence of this trend and official reports on several major geographical regions. Furthermore, we discover the outstanding sentiments of the #MeToo tweets using deep semantic meaning representations and their implications on the affected users experiencing different types of sexual harassment. We hope this study can raise further awareness regarding sexual misconduct in academia.