 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are Highly Aligned with Human Ratings of Emotional Stimuli
Aug 19, 2025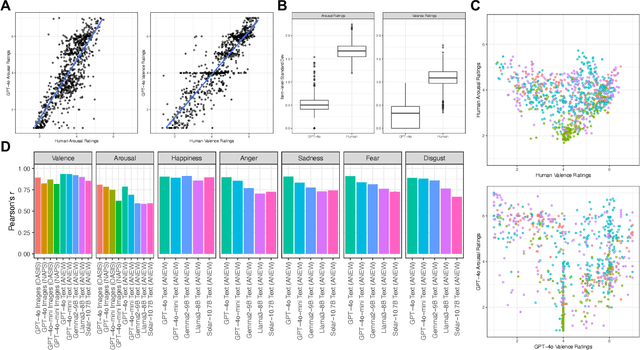
Emotions exert an immense influence over human behavior and cognition in both commonplace and high-stress tasks. Discussions of whether or how to integrate large language models (LLMs) into everyday life (e.g., acting as proxies for, or interacting with, human agents), should be informed by an understanding of how these tools evaluate emotionally loaded stimuli or situations. A model's alignment with human behavior in these cases can inform the effectiveness of LLMs for certain roles or interactions. To help build this understanding, we elicited ratings from multiple popular LLMs for datasets of words and images that were previously rated for their emotional content by humans. We found that when performing the same rating tasks, GPT-4o responded very similarly to human participants across modalities, stimuli and most rating scales (r = 0.9 or higher in many cases). However, arousal ratings were less well aligned between human and LLM raters, while happiness ratings were most highly aligned. Overall LLMs aligned better within a five-category (happiness, anger, sadness, fear, disgust) emotion framework than within a two-dimensional (arousal and valence) organization. Finally, LLM ratings were substantially more homogenous than human ratings. Together these results begin to describe how LLM agents interpret emotional stimuli and highlight similarities and differences among biological and artificial intelligence in key behavioral domains.
Self-Supervised Convolutional Audio Models are Flexible Acoustic Feature Learners: A Domain Specificity and Transfer-Learning Study
Feb 04, 2025Self-supervised learning (SSL) algorithms have emerged as powerful tools that can leverage large quantities of unlabeled audio data to pre-train robust representations that support strong performance on diverse downstream tasks. Up to now these have mostly been developed separately for speech and non-speech applications. Here, we explored the domain specificity of a convolutional model's pre-training data relative to different downstream speech and non-speech tasks using a self-supervised pre-training approach (BYOL-A). We found that these pre-trained models (regardless of whether they were pre-trained on speech data, non-speech data or both) enabled good performance on nearly all downstream tasks, beating or nearly matching the performance of popular domain-specific models. Only small domain-specificity advantages were observed between the different pre-training datasets. The popular domain-specific models used as baselines performed very well in their target domains, but generally faltered outside of them. Together, these results demonstrate that SSL methods can be a powerful way to learn flexible representations for domain specific data without labels. These models can be a powerful resource for later transfer learning, fine-tuning or data exploration applications when the downstream data are similar, but also perhaps when there may be a domain mismatch.
Targeted Adversarial Denoising Autoencoders (TADA) for Neural Time Series Filtration
Jan 10, 2025



Current machine learning (ML)-based algorithms for filtering electroencephalography (EEG) time series data face challenges related to cumbersome training times, regularization, and accurate reconstruction. To address these shortcomings, we present an ML filtration algorithm driven by a logistic covariance-targeted adversarial denoising autoencoder (TADA). We hypothesize that the expressivity of a targeted, correlation-driven convolutional autoencoder will enable effective time series filtration while minimizing compute requirements (e.g., runtime, model size). Furthermore, we expect that adversarial training with covariance rescaling will minimize signal degradation. To test this hypothesis, a TADA system prototype was trained and evaluated on the task of removing electromyographic (EMG) noise from EEG data in the EEGdenoiseNet dataset, which includes EMG and EEG data from 67 subjects. The TADA filter surpasses conventional signal filtration algorithms across quantitative metrics (Correlation Coefficient, Temporal RRMSE, Spectral RRMSE), and performs competitively against other deep learning architectures at a reduced model size of less than 400,000 trainable parameters. Further experimentation will be necessary to assess the viability of TADA on a wider range of deployment cases.
Turing Representational Similarity Analysis (RSA): A Flexible Method for Measuring Alignment Between Human and Artificial Intelligence
Nov 30, 2024As we consider entrusting Large Language Models (LLMs) with key societal and decision-making roles, measuring their alignment with human cognition becomes critical. This requires methods that can assess how these systems represent information and facilitate comparisons to human understanding across diverse tasks. To meet this need, we developed Turing Representational Similarity Analysis (RSA), a method that uses pairwise similarity ratings to quantify alignment between AIs and humans. We tested this approach on semantic alignment across text and image modalities, measuring how different Large Language and Vision Language Model (LLM and VLM) similarity judgments aligned with human responses at both group and individual levels. GPT-4o showed the strongest alignment with human performance among the models we tested, particularly when leveraging its text processing capabilities rather than image processing, regardless of the input modality. However, no model we studied adequately captured the inter-individual variability observed among human participants. This method helped uncover certain hyperparameters and prompts that could steer model behavior to have more or less human-like qualities at an inter-individual or group level. Turing RSA enables the efficient and flexible quantification of human-AI alignment and complements existing accuracy-based benchmark tasks. We demonstrate its utility across multiple modalities (words, sentences, images) for understanding how LLMs encode knowledge and for examining representational alignment with human cognition.