 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are Highly Aligned with Human Ratings of Emotional Stimuli
Aug 19, 2025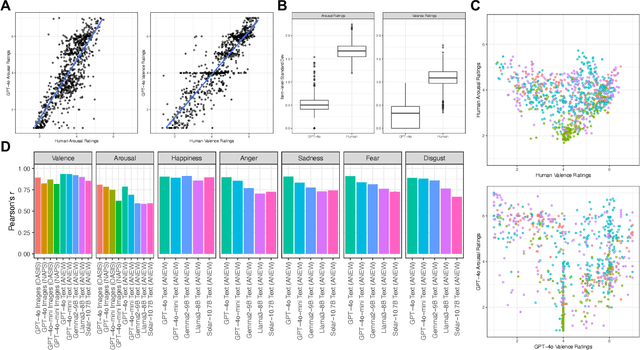
Emotions exert an immense influence over human behavior and cognition in both commonplace and high-stress tasks. Discussions of whether or how to integrate large language models (LLMs) into everyday life (e.g., acting as proxies for, or interacting with, human agents), should be informed by an understanding of how these tools evaluate emotionally loaded stimuli or situations. A model's alignment with human behavior in these cases can inform the effectiveness of LLMs for certain roles or interactions. To help build this understanding, we elicited ratings from multiple popular LLMs for datasets of words and images that were previously rated for their emotional content by humans. We found that when performing the same rating tasks, GPT-4o responded very similarly to human participants across modalities, stimuli and most rating scales (r = 0.9 or higher in many cases). However, arousal ratings were less well aligned between human and LLM raters, while happiness ratings were most highly aligned. Overall LLMs aligned better within a five-category (happiness, anger, sadness, fear, disgust) emotion framework than within a two-dimensional (arousal and valence) organization. Finally, LLM ratings were substantially more homogenous than human ratings. Together these results begin to describe how LLM agents interpret emotional stimuli and highlight similarities and differences among biological and artificial intelligence in key behavioral domains.
Turing Representational Similarity Analysis (RSA): A Flexible Method for Measuring Alignment Between Human and Artificial Intelligence
Nov 30, 2024As we consider entrusting Large Language Models (LLMs) with key societal and decision-making roles, measuring their alignment with human cognition becomes critical. This requires methods that can assess how these systems represent information and facilitate comparisons to human understanding across diverse tasks. To meet this need, we developed Turing Representational Similarity Analysis (RSA), a method that uses pairwise similarity ratings to quantify alignment between AIs and humans. We tested this approach on semantic alignment across text and image modalities, measuring how different Large Language and Vision Language Model (LLM and VLM) similarity judgments aligned with human responses at both group and individual levels. GPT-4o showed the strongest alignment with human performance among the models we tested, particularly when leveraging its text processing capabilities rather than image processing, regardless of the input modality. However, no model we studied adequately captured the inter-individual variability observed among human participants. This method helped uncover certain hyperparameters and prompts that could steer model behavior to have more or less human-like qualities at an inter-individual or group level. Turing RSA enables the efficient and flexible quantification of human-AI alignment and complements existing accuracy-based benchmark tasks. We demonstrate its utility across multiple modalities (words, sentences, images) for understanding how LLMs encode knowledge and for examining representational alignment with human cognition.
Continual learning benefits from multiple sleep mechanisms: NREM, REM, and Synaptic Downscaling
Sep 09, 2022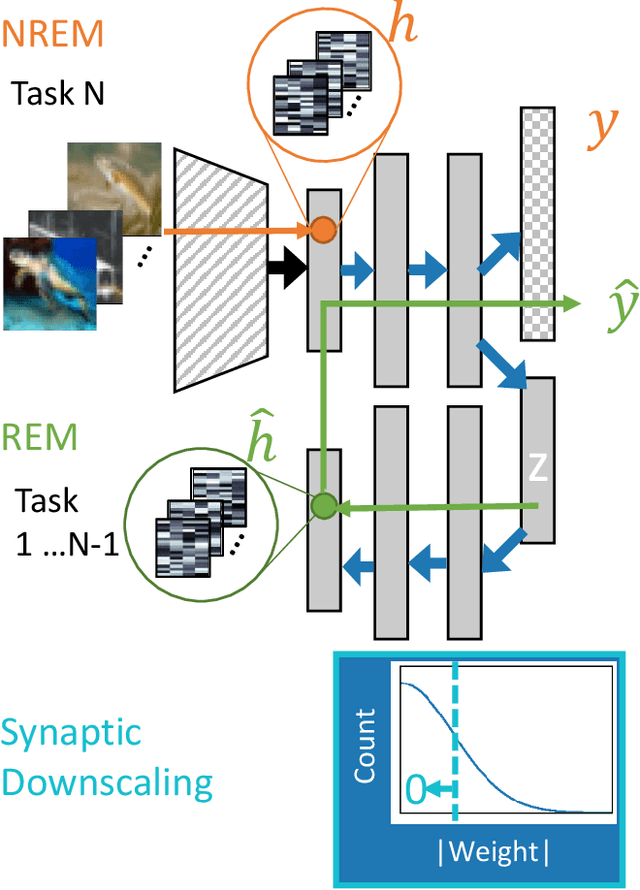
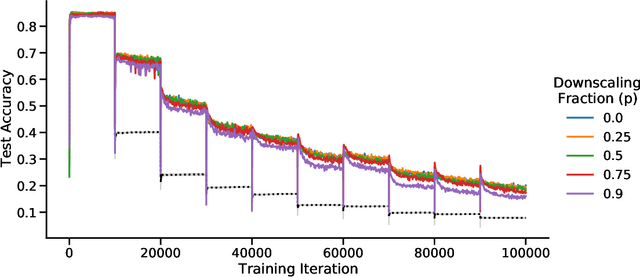
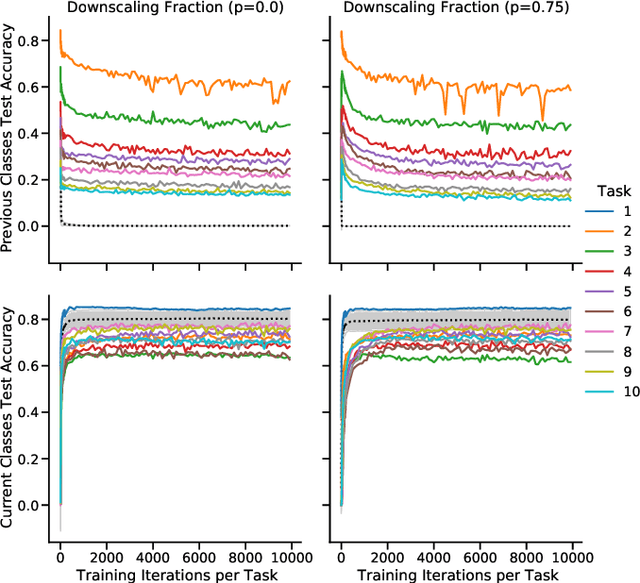
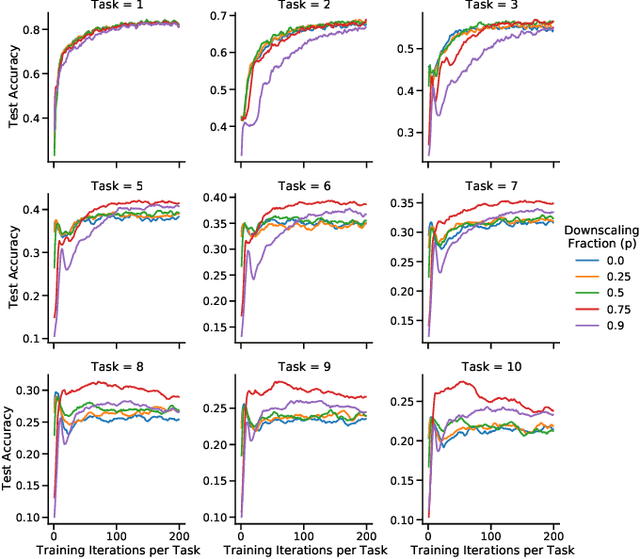
Learning new tasks and skills in succession without losing prior learning (i.e., catastrophic forgetting) is a computational challenge for both artificial and biological neural networks, yet artificial systems struggle to achieve parity with their biological analogues. Mammalian brains employ numerous neural operations in support of continual learning during sleep. These are ripe for artificial adaptation. Here, we investigate how modeling three distinct components of mammalian sleep together affects continual learning in artificial neural networks: (1) a veridical memory replay process observed during non-rapid eye movement (NREM) sleep; (2) a generative memory replay process linked to REM sleep; and (3) a synaptic downscaling process which has been proposed to tune signal-to-noise ratios and support neural upkeep. We find benefits from the inclusion of all three sleep components when evaluating performance on a continual learning CIFAR-100 image classification benchmark. Maximum accuracy improved during training and catastrophic forgetting was reduced during later tasks. While some catastrophic forgetting persisted over the course of network training, higher levels of synaptic downscaling lead to better retention of early tasks and further facilitated the recovery of early task accuracy during subsequent training. One key takeaway is that there is a trade-off at hand when considering the level of synaptic downscaling to use - more aggressive downscaling better protects early tasks, but less downscaling enhances the ability to learn new tasks. Intermediate levels can strike a balance with the highest overall accuracies during training. Overall, our results both provide insight into how to adapt sleep components to enhance artificial continual learning systems and highlight areas for future neuroscientific sleep research to further such systems.
Evaluating semantic models with word-sentence relatedness
Jan 03, 2017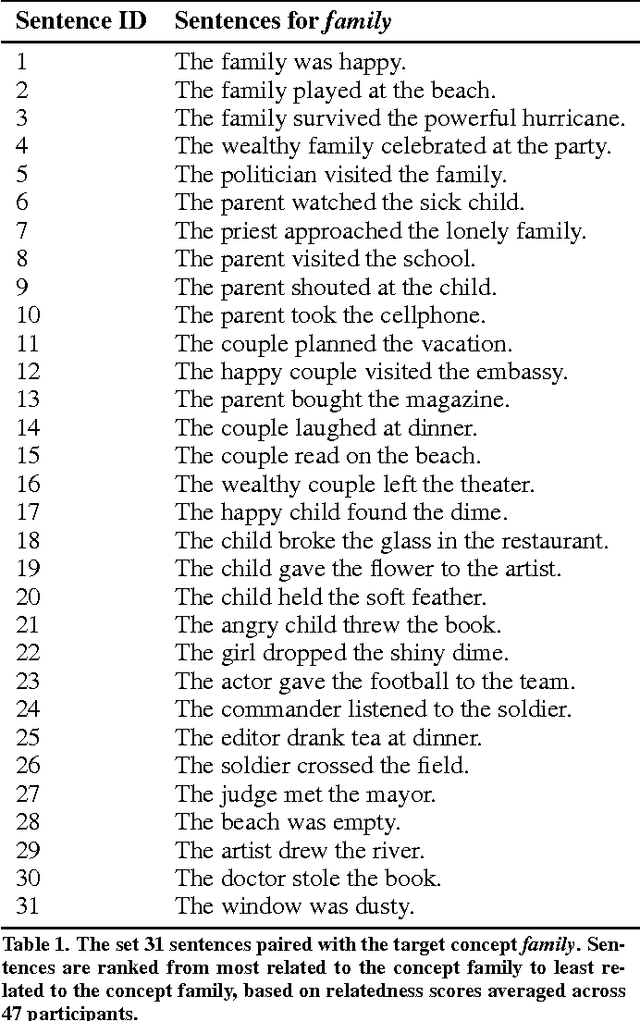


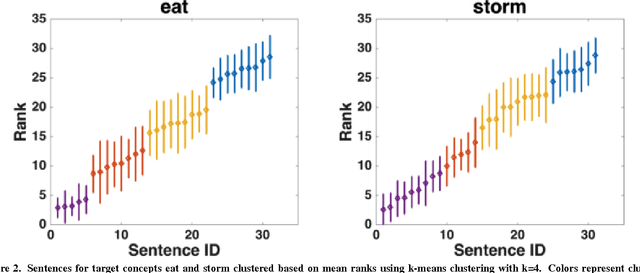
Semantic textual similarity (STS) systems are designed to encode and evaluate the semantic similarity between words, phrases, sentences, and documents. One method for assessing the quality or authenticity of semantic information encoded in these systems is by comparison with human judgments. A data set for evaluating semantic models was developed consisting of 775 English word-sentence pairs, each annotated for semantic relatedness by human raters engaged in a Maximum Difference Scaling (MDS) task, as well as a faster alternative task. As a sample application of this relatedness data, behavior-based relatedness was compared to the relatedness computed via four off-the-shelf STS models: n-gram, Latent Semantic Analysis (LSA), Word2Vec, and UMBC Ebiquity. Some STS models captured much of the variance in the human judgments collected, but they were not sensitive to the implicatures and entailments that were processed and considered by the participants. All text stimuli and judgment data have been made freely available.