 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating semantic models with word-sentence relatedness
Jan 03, 2017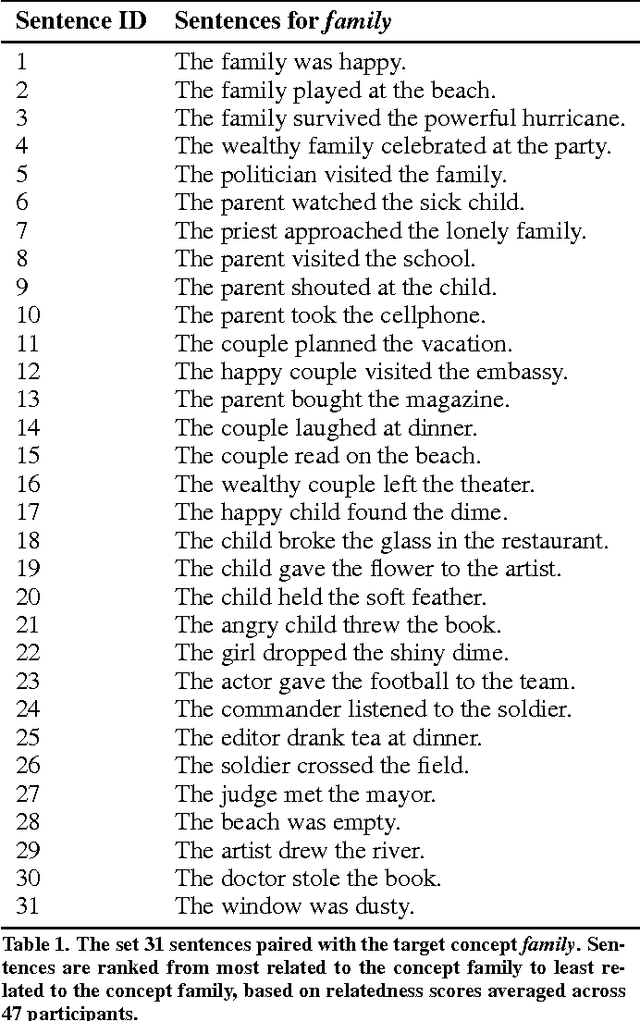


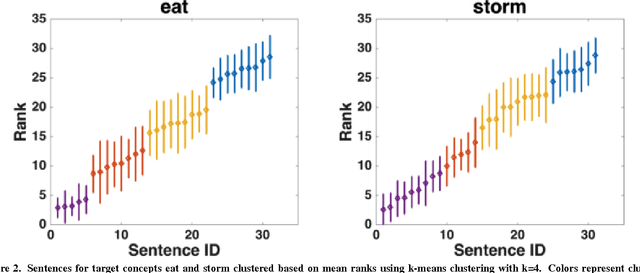
Semantic textual similarity (STS) systems are designed to encode and evaluate the semantic similarity between words, phrases, sentences, and documents. One method for assessing the quality or authenticity of semantic information encoded in these systems is by comparison with human judgments. A data set for evaluating semantic models was developed consisting of 775 English word-sentence pairs, each annotated for semantic relatedness by human raters engaged in a Maximum Difference Scaling (MDS) task, as well as a faster alternative task. As a sample application of this relatedness data, behavior-based relatedness was compared to the relatedness computed via four off-the-shelf STS models: n-gram, Latent Semantic Analysis (LSA), Word2Vec, and UMBC Ebiquity. Some STS models captured much of the variance in the human judgments collected, but they were not sensitive to the implicatures and entailments that were processed and considered by the participants. All text stimuli and judgment data have been made freely available.