 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing evolutionary computation to optimize task performance of unclocked, recurrent Boolean circuits in FPGAs
Mar 19, 2024



It has been shown that unclocked, recurrent networks of Boolean gates in FPGAs can be used for low-SWaP reservoir computing. In such systems, topology and node functionality of the network are randomly initialized. To create a network that solves a task, weights are applied to output nodes and learning is achieved by adjusting those weights with conventional machine learning methods. However, performance is often limited compared to networks where all parameters are learned. Herein, we explore an alternative learning approach for unclocked, recurrent networks in FPGAs. We use evolutionary computation to evolve the Boolean functions of network nodes. In one type of implementation the output nodes are used directly to perform a task and all learning is via evolution of the network's node functions. In a second type of implementation a back-end classifier is used as in traditional reservoir computing. In that case, both evolution of node functions and adjustment of output node weights contribute to learning. We demonstrate the practicality of node function evolution, obtaining an accuracy improvement of ~30% on an image classification task while processing at a rate of over three million samples per second. We additionally demonstrate evolvability of network memory and dynamic output signals.
Exploiting Large Neuroimaging Datasets to Create Connectome-Constrained Approaches for more Robust, Efficient, and Adaptable Artificial Intelligence
May 26, 2023Despite the progress in deep learning networks, efficient learning at the edge (enabling adaptable, low-complexity machine learning solutions) remains a critical need for defense and commercial applications. We envision a pipeline to utilize large neuroimaging datasets, including maps of the brain which capture neuron and synapse connectivity, to improve machine learning approaches. We have pursued different approaches within this pipeline structure. First, as a demonstration of data-driven discovery, the team has developed a technique for discovery of repeated subcircuits, or motifs. These were incorporated into a neural architecture search approach to evolve network architectures. Second, we have conducted analysis of the heading direction circuit in the fruit fly, which performs fusion of visual and angular velocity features, to explore augmenting existing computational models with new insight. Our team discovered a novel pattern of connectivity, implemented a new model, and demonstrated sensor fusion on a robotic platform. Third, the team analyzed circuitry for memory formation in the fruit fly connectome, enabling the design of a novel generative replay approach. Finally, the team has begun analysis of connectivity in mammalian cortex to explore potential improvements to transformer networks. These constraints increased network robustness on the most challenging examples in the CIFAR-10-C computer vision robustness benchmark task, while reducing learnable attention parameters by over an order of magnitude. Taken together, these results demonstrate multiple potential approaches to utilize insight from neural systems for developing robust and efficient machine learning techniques.
MTNeuro: A Benchmark for Evaluating Representations of Brain Structure Across Multiple Levels of Abstraction
Jan 01, 2023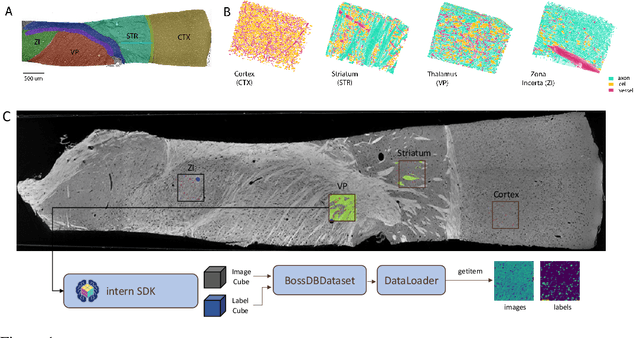

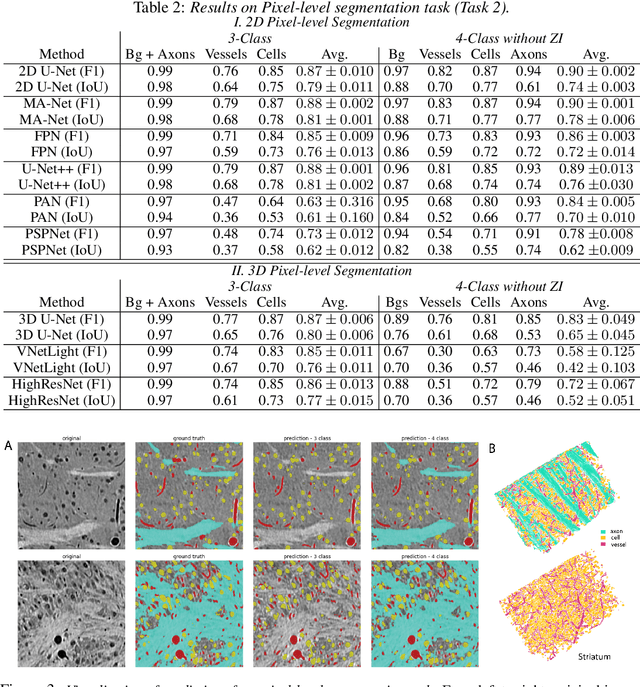
There are multiple scales of abstraction from which we can describe the same image, depending on whether we are focusing on fine-grained details or a more global attribute of the image. In brain mapping, learning to automatically parse images to build representations of both small-scale features (e.g., the presence of cells or blood vessels) and global properties of an image (e.g., which brain region the image comes from) is a crucial and open challenge. However, most existing datasets and benchmarks for neuroanatomy consider only a single downstream task at a time. To bridge this gap, we introduce a new dataset, annotations, and multiple downstream tasks that provide diverse ways to readout information about brain structure and architecture from the same image. Our multi-task neuroimaging benchmark (MTNeuro) is built on volumetric, micrometer-resolution X-ray microtomography images spanning a large thalamocortical section of mouse brain, encompassing multiple cortical and subcortical regions. We generated a number of different prediction challenges and evaluated several supervised and self-supervised models for brain-region prediction and pixel-level semantic segmentation of microstructures. Our experiments not only highlight the rich heterogeneity of this dataset, but also provide insights into how self-supervised approaches can be used to learn representations that capture multiple attributes of a single image and perform well on a variety of downstream tasks. Datasets, code, and pre-trained baseline models are provided at: https://mtneuro.github.io/ .
Continual learning benefits from multiple sleep mechanisms: NREM, REM, and Synaptic Downscaling
Sep 09, 2022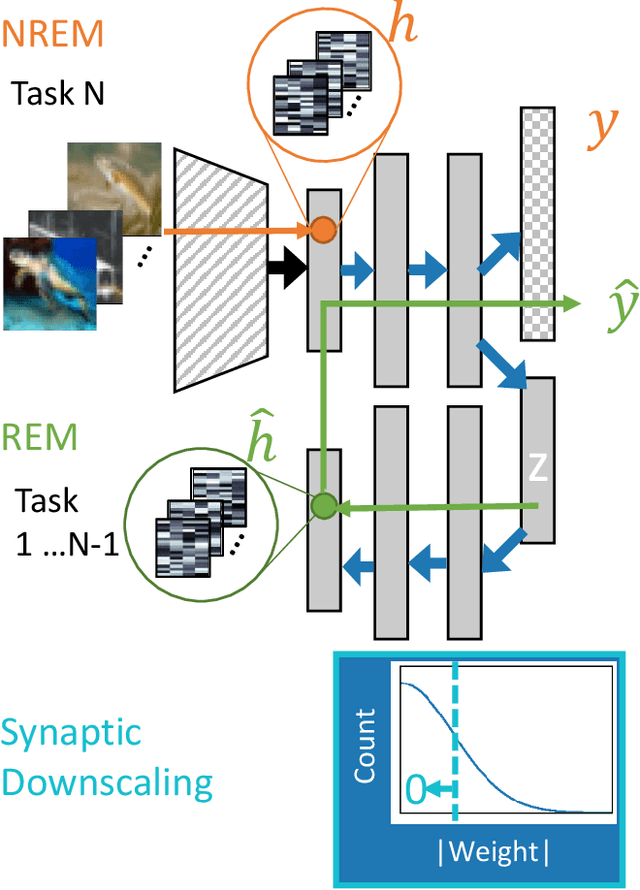
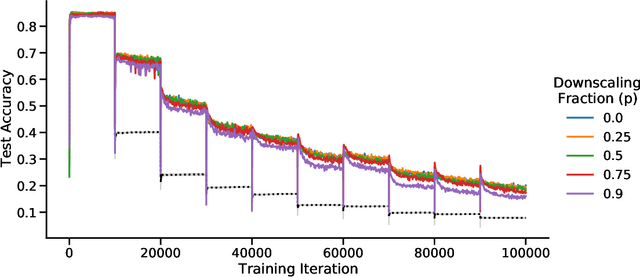
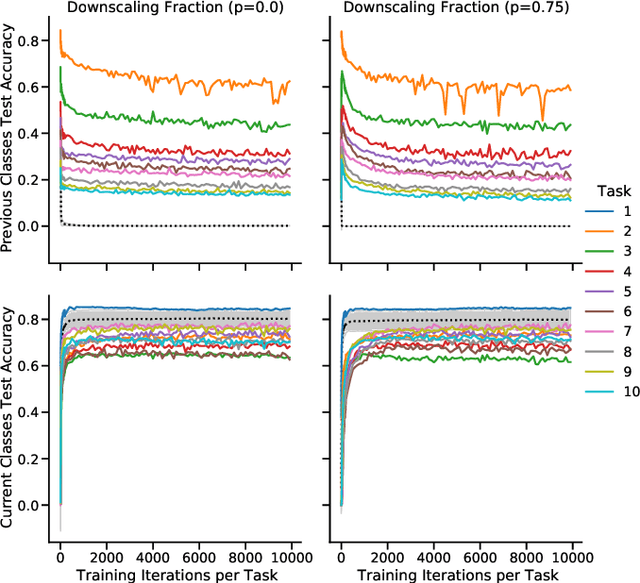
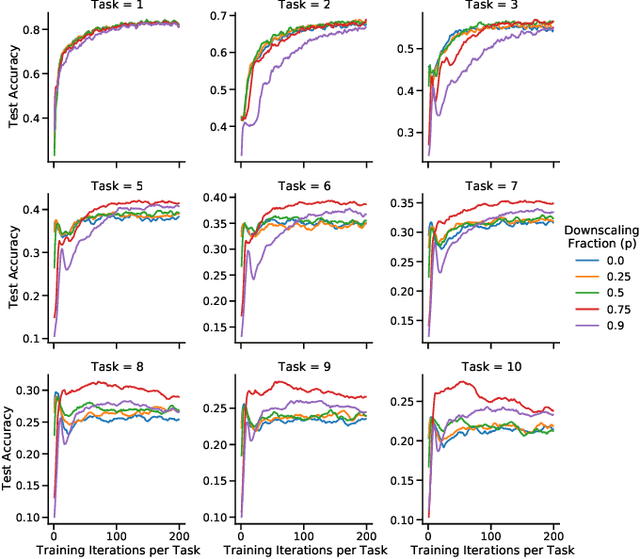
Learning new tasks and skills in succession without losing prior learning (i.e., catastrophic forgetting) is a computational challenge for both artificial and biological neural networks, yet artificial systems struggle to achieve parity with their biological analogues. Mammalian brains employ numerous neural operations in support of continual learning during sleep. These are ripe for artificial adaptation. Here, we investigate how modeling three distinct components of mammalian sleep together affects continual learning in artificial neural networks: (1) a veridical memory replay process observed during non-rapid eye movement (NREM) sleep; (2) a generative memory replay process linked to REM sleep; and (3) a synaptic downscaling process which has been proposed to tune signal-to-noise ratios and support neural upkeep. We find benefits from the inclusion of all three sleep components when evaluating performance on a continual learning CIFAR-100 image classification benchmark. Maximum accuracy improved during training and catastrophic forgetting was reduced during later tasks. While some catastrophic forgetting persisted over the course of network training, higher levels of synaptic downscaling lead to better retention of early tasks and further facilitated the recovery of early task accuracy during subsequent training. One key takeaway is that there is a trade-off at hand when considering the level of synaptic downscaling to use - more aggressive downscaling better protects early tasks, but less downscaling enhances the ability to learn new tasks. Intermediate levels can strike a balance with the highest overall accuracies during training. Overall, our results both provide insight into how to adapt sleep components to enhance artificial continual learning systems and highlight areas for future neuroscientific sleep research to further such systems.
L2Explorer: A Lifelong Reinforcement Learning Assessment Environment
Mar 14, 2022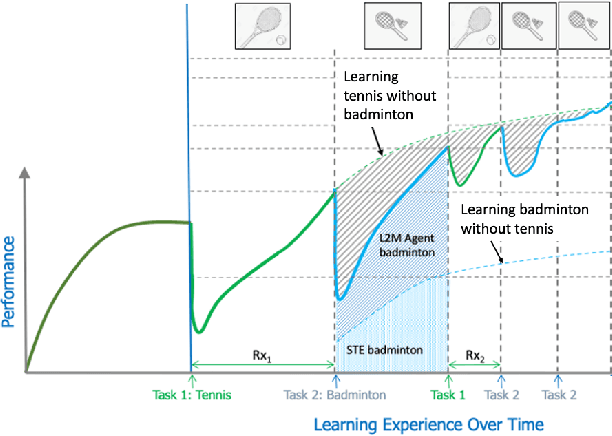



Despite groundbreaking progress in reinforcement learning for robotics, gameplay, and other complex domains, major challenges remain in applying reinforcement learning to the evolving, open-world problems often found in critical application spaces. Reinforcement learning solutions tend to generalize poorly when exposed to new tasks outside of the data distribution they are trained on, prompting an interest in continual learning algorithms. In tandem with research on continual learning algorithms, there is a need for challenge environments, carefully designed experiments, and metrics to assess research progress. We address the latter need by introducing a framework for continual reinforcement-learning development and assessment using Lifelong Learning Explorer (L2Explorer), a new, Unity-based, first-person 3D exploration environment that can be continuously reconfigured to generate a range of tasks and task variants structured into complex and evolving evaluation curricula. In contrast to procedurally generated worlds with randomized components, we have developed a systematic approach to defining curricula in response to controlled changes with accompanying metrics to assess transfer, performance recovery, and data efficiency. Taken together, the L2Explorer environment and evaluation approach provides a framework for developing future evaluation methodologies in open-world settings and rigorously evaluating approaches to lifelong learning.
Mine Your Own vieW: Self-Supervised Learning Through Across-Sample Prediction
Feb 19, 2021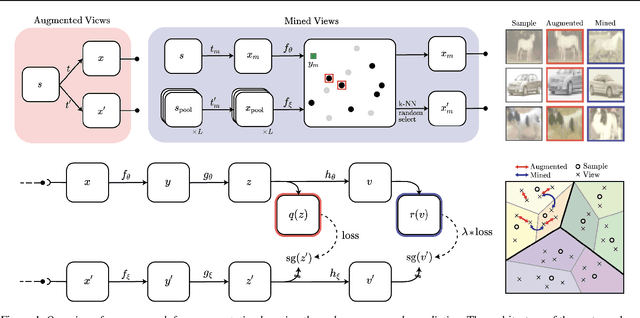
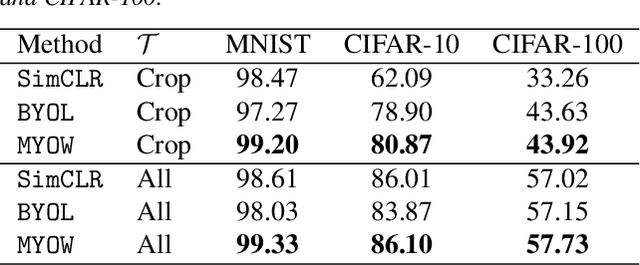
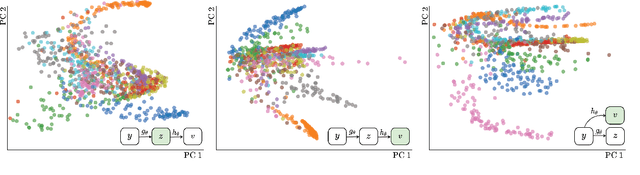
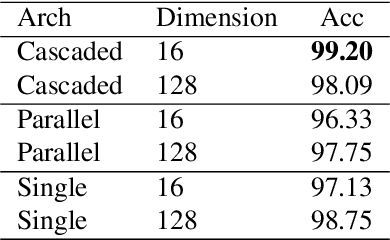
State-of-the-art methods for self-supervised learning (SSL) build representations by maximizing the similarity between different augmented "views" of a sample. Because these approaches try to match views of the same sample, they can be too myopic and fail to produce meaningful results when augmentations are not sufficiently rich. This motivates the use of the dataset itself to find similar, yet distinct, samples to serve as views for one another. In this paper, we introduce Mine Your Own vieW (MYOW), a new approach for building across-sample prediction into SSL. The idea behind our approach is to actively mine views, finding samples that are close in the representation space of the network, and then predict, from one sample's latent representation, the representation of a nearby sample. In addition to showing the promise of MYOW on standard datasets used in computer vision, we highlight the power of this idea in a novel application in neuroscience where rich augmentations are not already established. When applied to neural datasets, MYOW outperforms other self-supervised approaches in all examples (in some cases by more than 10%), and surpasses the supervised baseline for most datasets. By learning to predict the latent representation of similar samples, we show that it is possible to learn good representations in new domains where augmentations are still limited.