 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Intelligence in Movement
Jul 03, 2025
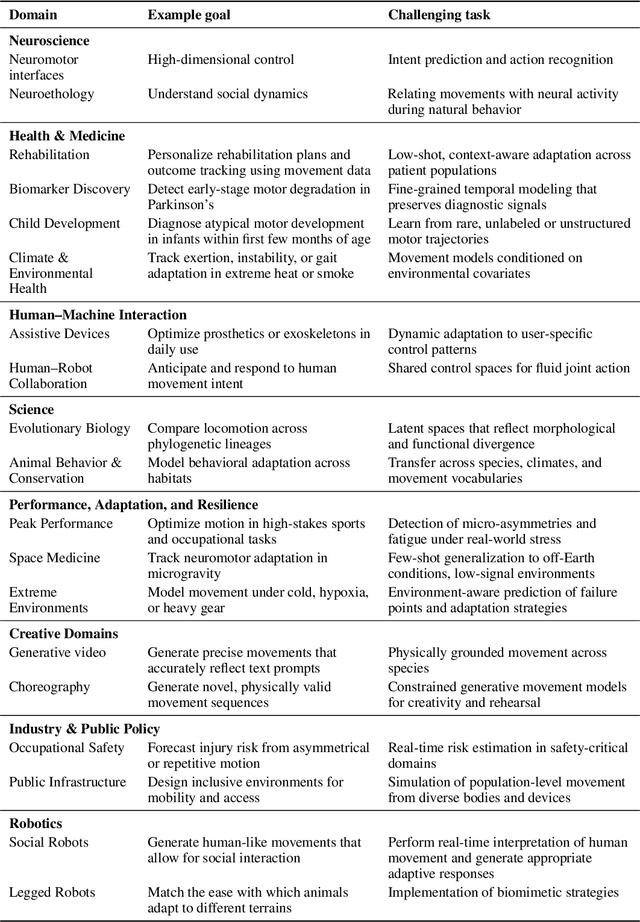
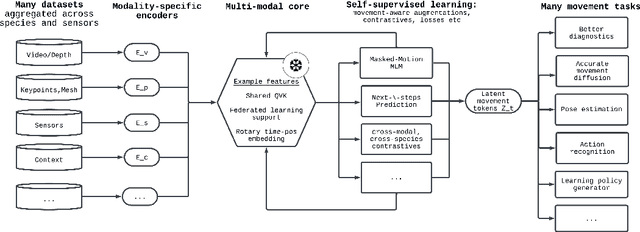
Recent advances in machine learning have dramatically improved our ability to model language, vision, and other high-dimensional data, yet they continue to struggle with one of the most fundamental aspects of biological systems: movement. Across neuroscience, medicine, robotics, and ethology, movement is essential for interpreting behavior, predicting intent, and enabling interaction. Despite its core significance in our intelligence, movement is often treated as an afterthought rather than as a rich and structured modality in its own right. This reflects a deeper fragmentation in how movement data is collected and modeled, often constrained by task-specific goals and domain-specific assumptions. But movement is not domain-bound. It reflects shared physical constraints, conserved morphological structures, and purposeful dynamics that cut across species and settings. We argue that movement should be treated as a primary modeling target for AI. It is inherently structured and grounded in embodiment and physics. This structure, often allowing for compact, lower-dimensional representations (e.g., pose), makes it more interpretable and computationally tractable to model than raw, high-dimensional sensory inputs. Developing models that can learn from and generalize across diverse movement data will not only advance core capabilities in generative modeling and control, but also create a shared foundation for understanding behavior across biological and artificial systems. Movement is not just an outcome, it is a window into how intelligent systems engage with the world.
Empirical influence functions to understand the logic of fine-tuning
Jun 01, 2024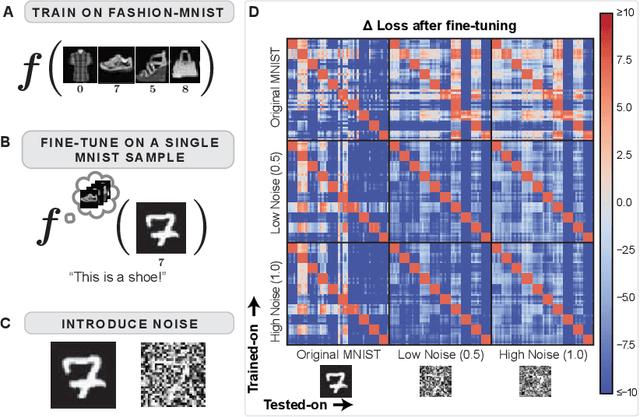
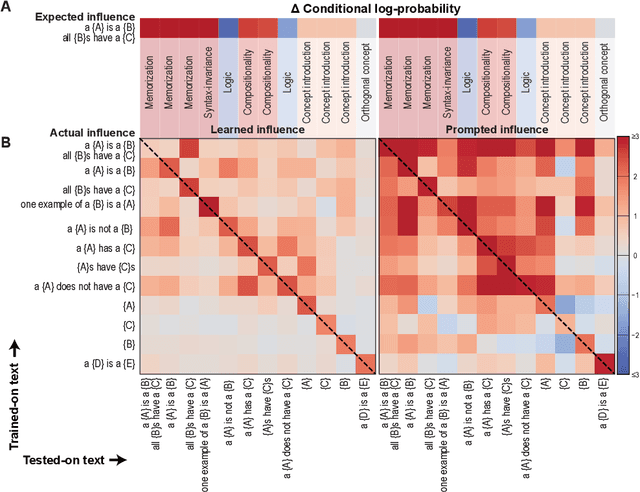
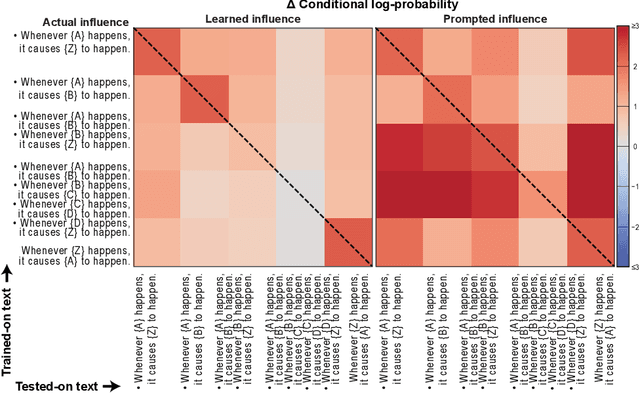
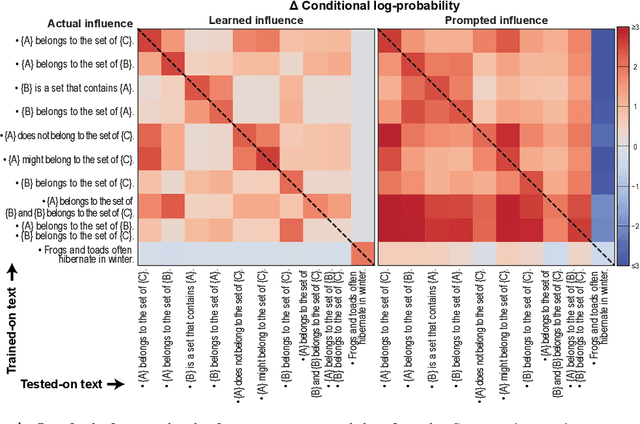
Understanding the process of learning in neural networks is crucial for improving their performance and interpreting their behavior. This can be approximately understood by asking how a model's output is influenced when we fine-tune on a new training sample. There are desiderata for such influences, such as decreasing influence with semantic distance, sparseness, noise invariance, transitive causality, and logical consistency. Here we use the empirical influence measured using fine-tuning to demonstrate how individual training samples affect outputs. We show that these desiderata are violated for both for simple convolutional networks and for a modern LLM. We also illustrate how prompting can partially rescue this failure. Our paper presents an efficient and practical way of quantifying how well neural networks learn from fine-tuning stimuli. Our results suggest that popular models cannot generalize or perform logic in the way they appear to.
A large language model-assisted education tool to provide feedback on open-ended responses
Jul 25, 2023


Open-ended questions are a favored tool among instructors for assessing student understanding and encouraging critical exploration of course material. Providing feedback for such responses is a time-consuming task that can lead to overwhelmed instructors and decreased feedback quality. Many instructors resort to simpler question formats, like multiple-choice questions, which provide immediate feedback but at the expense of personalized and insightful comments. Here, we present a tool that uses large language models (LLMs), guided by instructor-defined criteria, to automate responses to open-ended questions. Our tool delivers rapid personalized feedback, enabling students to quickly test their knowledge and identify areas for improvement. We provide open-source reference implementations both as a web application and as a Jupyter Notebook widget that can be used with instructional coding or math notebooks. With instructor guidance, LLMs hold promise to enhance student learning outcomes and elevate instructional methodologies.
Exploiting Large Neuroimaging Datasets to Create Connectome-Constrained Approaches for more Robust, Efficient, and Adaptable Artificial Intelligence
May 26, 2023Despite the progress in deep learning networks, efficient learning at the edge (enabling adaptable, low-complexity machine learning solutions) remains a critical need for defense and commercial applications. We envision a pipeline to utilize large neuroimaging datasets, including maps of the brain which capture neuron and synapse connectivity, to improve machine learning approaches. We have pursued different approaches within this pipeline structure. First, as a demonstration of data-driven discovery, the team has developed a technique for discovery of repeated subcircuits, or motifs. These were incorporated into a neural architecture search approach to evolve network architectures. Second, we have conducted analysis of the heading direction circuit in the fruit fly, which performs fusion of visual and angular velocity features, to explore augmenting existing computational models with new insight. Our team discovered a novel pattern of connectivity, implemented a new model, and demonstrated sensor fusion on a robotic platform. Third, the team analyzed circuitry for memory formation in the fruit fly connectome, enabling the design of a novel generative replay approach. Finally, the team has begun analysis of connectivity in mammalian cortex to explore potential improvements to transformer networks. These constraints increased network robustness on the most challenging examples in the CIFAR-10-C computer vision robustness benchmark task, while reducing learnable attention parameters by over an order of magnitude. Taken together, these results demonstrate multiple potential approaches to utilize insight from neural systems for developing robust and efficient machine learning techniques.
Scatterbrained: A flexible and expandable pattern for decentralized machine learning
Dec 14, 2021
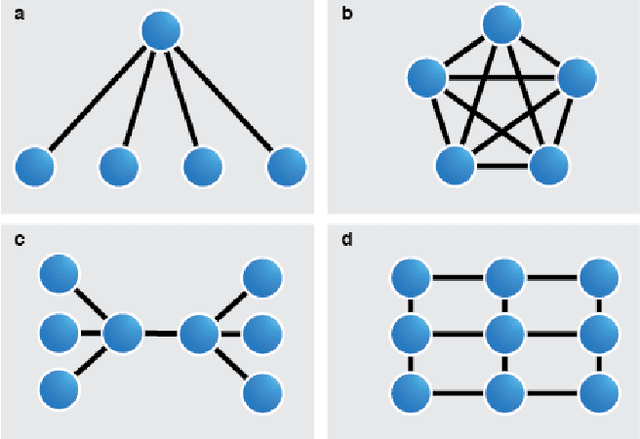


Federated machine learning is a technique for training a model across multiple devices without exchanging data between them. Because data remains local to each compute node, federated learning is well-suited for use-cases in fields where data is carefully controlled, such as medicine, or in domains with bandwidth constraints. One weakness of this approach is that most federated learning tools rely upon a central server to perform workload delegation and to produce a single shared model. Here, we suggest a flexible framework for decentralizing the federated learning pattern, and provide an open-source, reference implementation compatible with PyTorch.