 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing evolutionary computation to optimize task performance of unclocked, recurrent Boolean circuits in FPGAs
Mar 19, 2024



It has been shown that unclocked, recurrent networks of Boolean gates in FPGAs can be used for low-SWaP reservoir computing. In such systems, topology and node functionality of the network are randomly initialized. To create a network that solves a task, weights are applied to output nodes and learning is achieved by adjusting those weights with conventional machine learning methods. However, performance is often limited compared to networks where all parameters are learned. Herein, we explore an alternative learning approach for unclocked, recurrent networks in FPGAs. We use evolutionary computation to evolve the Boolean functions of network nodes. In one type of implementation the output nodes are used directly to perform a task and all learning is via evolution of the network's node functions. In a second type of implementation a back-end classifier is used as in traditional reservoir computing. In that case, both evolution of node functions and adjustment of output node weights contribute to learning. We demonstrate the practicality of node function evolution, obtaining an accuracy improvement of ~30% on an image classification task while processing at a rate of over three million samples per second. We additionally demonstrate evolvability of network memory and dynamic output signals.
Exploiting Large Neuroimaging Datasets to Create Connectome-Constrained Approaches for more Robust, Efficient, and Adaptable Artificial Intelligence
May 26, 2023Despite the progress in deep learning networks, efficient learning at the edge (enabling adaptable, low-complexity machine learning solutions) remains a critical need for defense and commercial applications. We envision a pipeline to utilize large neuroimaging datasets, including maps of the brain which capture neuron and synapse connectivity, to improve machine learning approaches. We have pursued different approaches within this pipeline structure. First, as a demonstration of data-driven discovery, the team has developed a technique for discovery of repeated subcircuits, or motifs. These were incorporated into a neural architecture search approach to evolve network architectures. Second, we have conducted analysis of the heading direction circuit in the fruit fly, which performs fusion of visual and angular velocity features, to explore augmenting existing computational models with new insight. Our team discovered a novel pattern of connectivity, implemented a new model, and demonstrated sensor fusion on a robotic platform. Third, the team analyzed circuitry for memory formation in the fruit fly connectome, enabling the design of a novel generative replay approach. Finally, the team has begun analysis of connectivity in mammalian cortex to explore potential improvements to transformer networks. These constraints increased network robustness on the most challenging examples in the CIFAR-10-C computer vision robustness benchmark task, while reducing learnable attention parameters by over an order of magnitude. Taken together, these results demonstrate multiple potential approaches to utilize insight from neural systems for developing robust and efficient machine learning techniques.
Utilizing a null class to restrict decision spaces and defend against neural network adversarial attacks
Feb 24, 2020
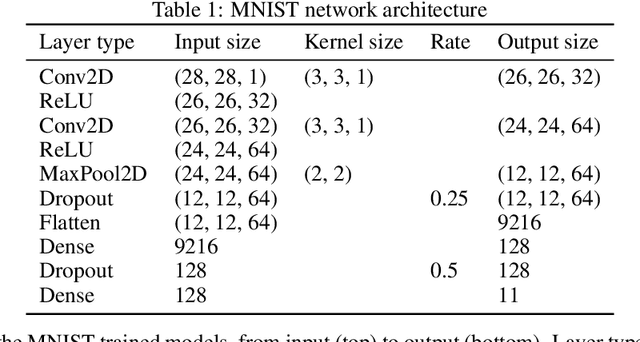
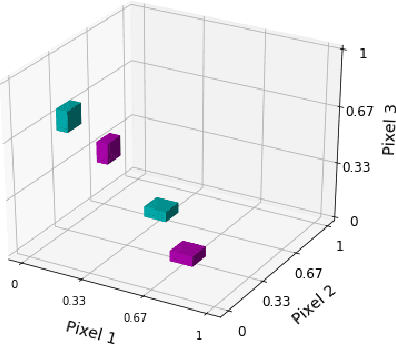
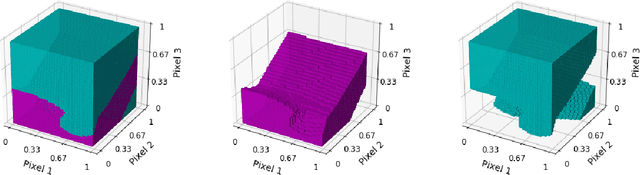
Despite recent progress, deep neural networks generally continue to be vulnerable to so-called adversarial examples--input images with small perturbations that can result in changes in the output classifications, despite no such change in the semantic meaning to human viewers. This is true even for seemingly simple challenges such as the MNIST digit classification task. In part, this suggests that these networks are not relying on the same set of object features as humans use to make these classifications. In this paper we examine an additional, and largely unexplored, cause behind this phenomenon--namely, the use of the conventional training paradigm in which the entire input space is parcellated among the training classes. Owing to this paradigm, learned decision spaces for individual classes span excessively large regions of the input space and include images that have no semantic similarity to images in the training set. In this study, we train models that include a null class. That is, models may "opt-out" of classifying an input image as one of the digit classes. During training, null images are created through a variety of methods, in an attempt to create tighter and more semantically meaningful decision spaces for the digit classes. The best performing models classify nearly all adversarial examples as nulls, rather than mistaking them as a member of an incorrect digit class, while simultaneously maintaining high accuracy on the unperturbed test set. The use of a null class and the training paradigm presented herein may provide an effective defense against adversarial attacks for some applications. Code for replicating this study will be made available at https://github.com/mattroos/null_class_adversarial_defense .