 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing a null class to restrict decision spaces and defend against neural network adversarial attacks
Paper and Code

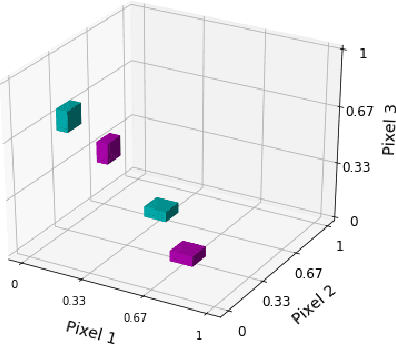
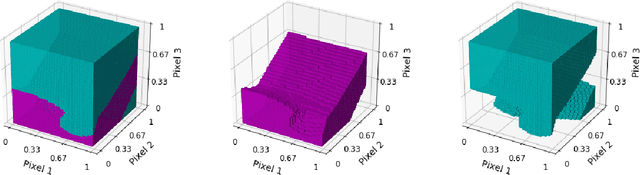
Despite recent progress, deep neural networks generally continue to be vulnerable to so-called adversarial examples--input images with small perturbations that can result in changes in the output classifications, despite no such change in the semantic meaning to human viewers. This is true even for seemingly simple challenges such as the MNIST digit classification task. In part, this suggests that these networks are not relying on the same set of object features as humans use to make these classifications. In this paper we examine an additional, and largely unexplored, cause behind this phenomenon--namely, the use of the conventional training paradigm in which the entire input space is parcellated among the training classes. Owing to this paradigm, learned decision spaces for individual classes span excessively large regions of the input space and include images that have no semantic similarity to images in the training set. In this study, we train models that include a null class. That is, models may "opt-out" of classifying an input image as one of the digit classes. During training, null images are created through a variety of methods, in an attempt to create tighter and more semantically meaningful decision spaces for the digit classes. The best performing models classify nearly all adversarial examples as nulls, rather than mistaking them as a member of an incorrect digit class, while simultaneously maintaining high accuracy on the unperturbed test set. The use of a null class and the training paradigm presented herein may provide an effective defense against adversarial attacks for some applications. Code for replicating this study will be made available at https://github.com/mattroos/null_class_adversarial_defense .