 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sinkhorn divergences for supervised change point detection
Feb 10, 2022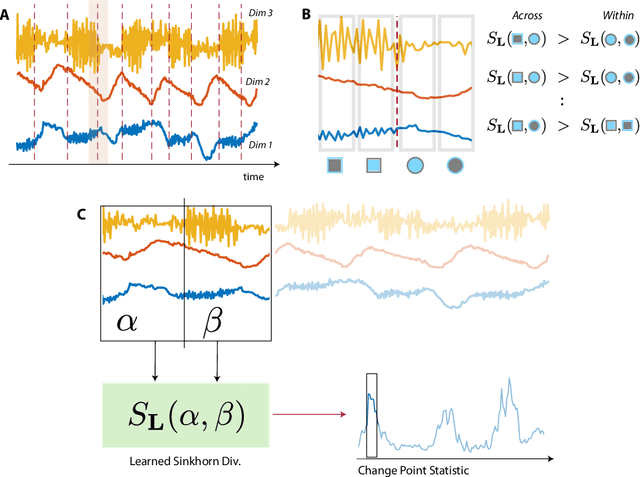
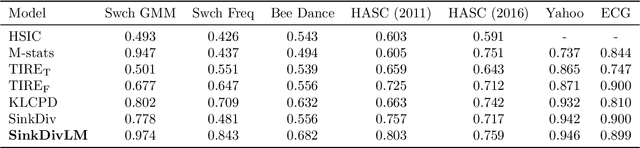
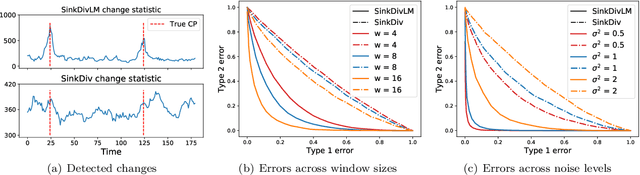
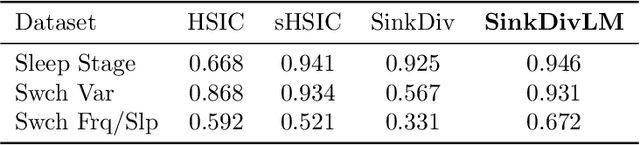
Many modern applications require detecting change points in complex sequential data. Most existing methods for change point detection are unsupervised and, as a consequence, lack any information regarding what kind of changes we want to detect or if some kinds of changes are safe to ignore. This often results in poor change detection performance. We present a novel change point detection framework that uses true change point instances as supervision for learning a ground metric such that Sinkhorn divergences can be then used in two-sample tests on sliding windows to detect change points in an online manner. Our method can be used to learn a sparse metric which can be useful for both feature selection and interpretation in high-dimensional change point detection settings. Experiments on simulated as well as real world sequences show that our proposed method can substantially improve change point detection performance over existing unsupervised change point detection methods using only few labeled change point instances.
Drop, Swap, and Generate: A Self-Supervised Approach for Generating Neural Activity
Nov 03, 2021Meaningful and simplified representations of neural activity can yield insights into how and what information is being processed within a neural circuit. However, without labels, finding representations that reveal the link between the brain and behavior can be challenging. Here, we introduce a novel unsupervised approach for learning disentangled representations of neural activity called Swap-VAE. Our approach combines a generative modeling framework with an instance-specific alignment loss that tries to maximize the representational similarity between transformed views of the input (brain state). These transformed (or augmented) views are created by dropping out neurons and jittering samples in time, which intuitively should lead the network to a representation that maintains both temporal consistency and invariance to the specific neurons used to represent the neural state. Through evaluations on both synthetic data and neural recordings from hundreds of neurons in different primate brains, we show that it is possible to build representations that disentangle neural datasets along relevant latent dimensions linked to behavior.
Mine Your Own vieW: Self-Supervised Learning Through Across-Sample Prediction
Feb 19, 2021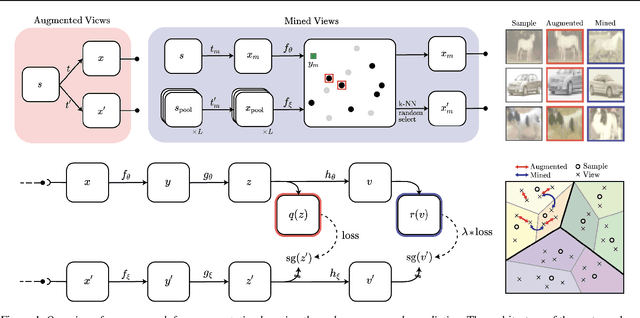
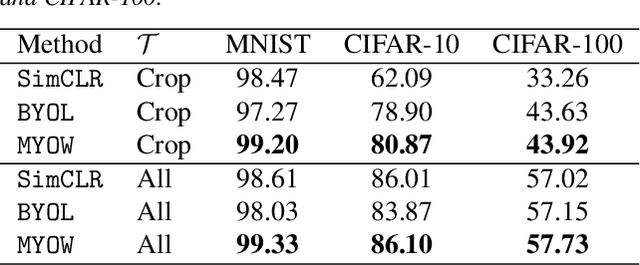
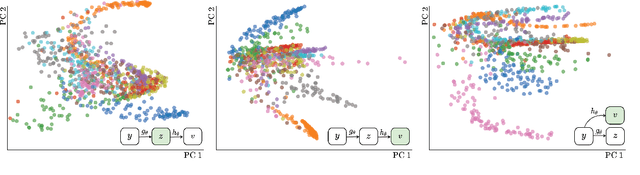
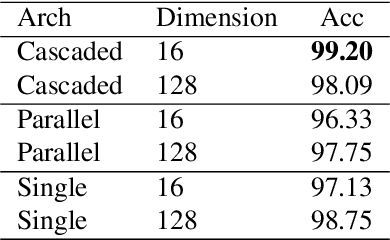
State-of-the-art methods for self-supervised learning (SSL) build representations by maximizing the similarity between different augmented "views" of a sample. Because these approaches try to match views of the same sample, they can be too myopic and fail to produce meaningful results when augmentations are not sufficiently rich. This motivates the use of the dataset itself to find similar, yet distinct, samples to serve as views for one another. In this paper, we introduce Mine Your Own vieW (MYOW), a new approach for building across-sample prediction into SSL. The idea behind our approach is to actively mine views, finding samples that are close in the representation space of the network, and then predict, from one sample's latent representation, the representation of a nearby sample. In addition to showing the promise of MYOW on standard datasets used in computer vision, we highlight the power of this idea in a novel application in neuroscience where rich augmentations are not already established. When applied to neural datasets, MYOW outperforms other self-supervised approaches in all examples (in some cases by more than 10%), and surpasses the supervised baseline for most datasets. By learning to predict the latent representation of similar samples, we show that it is possible to learn good representations in new domains where augmentations are still limited.