 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTNeuro: A Benchmark for Evaluating Representations of Brain Structure Across Multiple Levels of Abstraction
Jan 01, 2023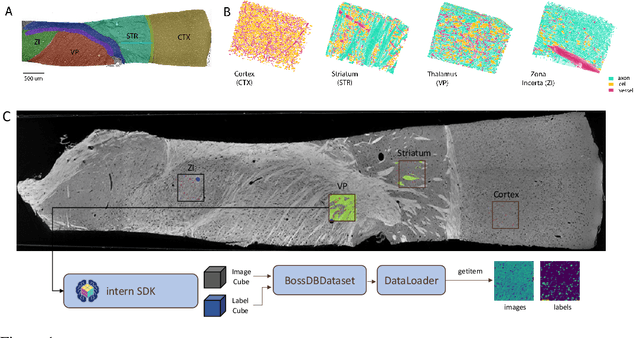
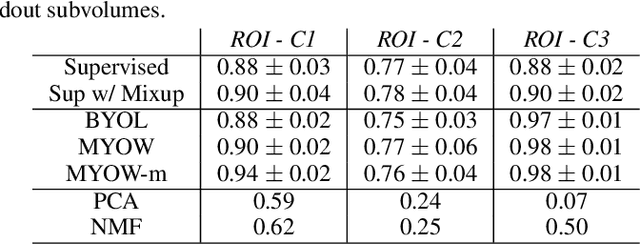

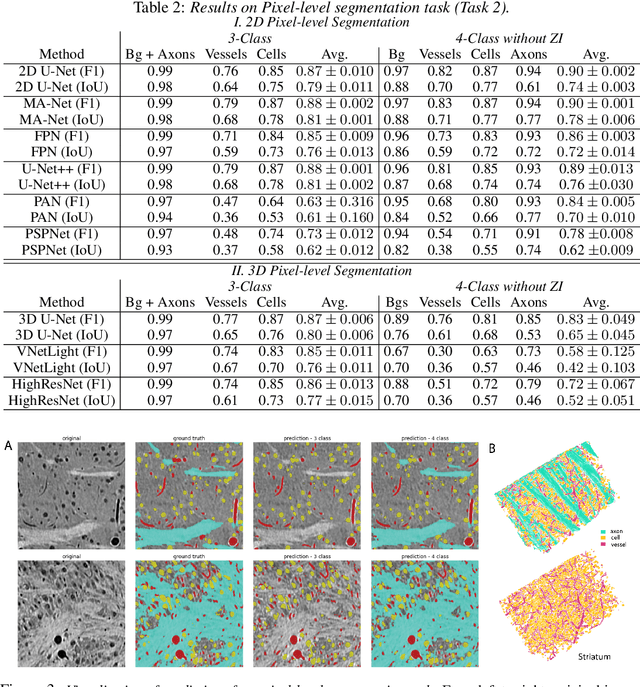
There are multiple scales of abstraction from which we can describe the same image, depending on whether we are focusing on fine-grained details or a more global attribute of the image. In brain mapping, learning to automatically parse images to build representations of both small-scale features (e.g., the presence of cells or blood vessels) and global properties of an image (e.g., which brain region the image comes from) is a crucial and open challenge. However, most existing datasets and benchmarks for neuroanatomy consider only a single downstream task at a time. To bridge this gap, we introduce a new dataset, annotations, and multiple downstream tasks that provide diverse ways to readout information about brain structure and architecture from the same image. Our multi-task neuroimaging benchmark (MTNeuro) is built on volumetric, micrometer-resolution X-ray microtomography images spanning a large thalamocortical section of mouse brain, encompassing multiple cortical and subcortical regions. We generated a number of different prediction challenges and evaluated several supervised and self-supervised models for brain-region prediction and pixel-level semantic segmentation of microstructures. Our experiments not only highlight the rich heterogeneity of this dataset, but also provide insights into how self-supervised approaches can be used to learn representations that capture multiple attributes of a single image and perform well on a variety of downstream tasks. Datasets, code, and pre-trained baseline models are provided at: https://mtneuro.github.io/ .
Mine Your Own vieW: Self-Supervised Learning Through Across-Sample Prediction
Feb 19, 2021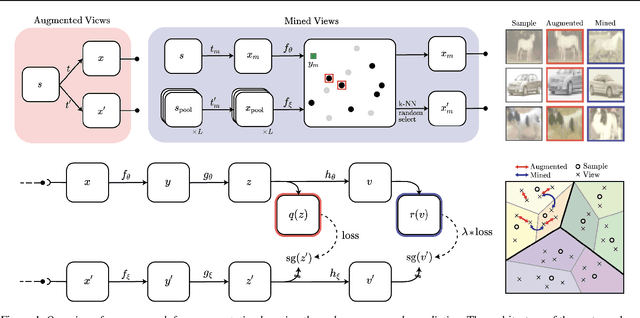
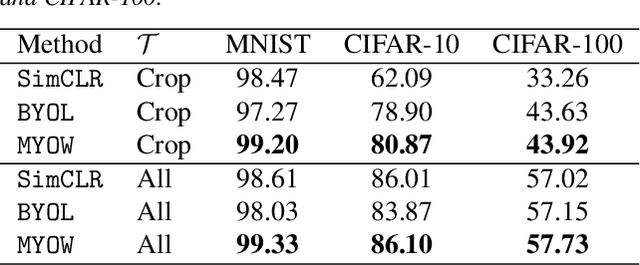
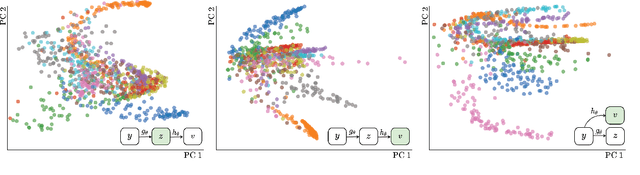
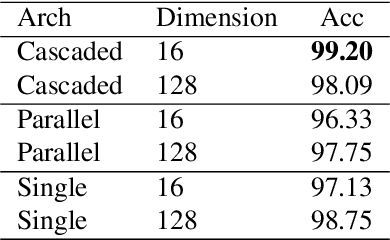
State-of-the-art methods for self-supervised learning (SSL) build representations by maximizing the similarity between different augmented "views" of a sample. Because these approaches try to match views of the same sample, they can be too myopic and fail to produce meaningful results when augmentations are not sufficiently rich. This motivates the use of the dataset itself to find similar, yet distinct, samples to serve as views for one another. In this paper, we introduce Mine Your Own vieW (MYOW), a new approach for building across-sample prediction into SSL. The idea behind our approach is to actively mine views, finding samples that are close in the representation space of the network, and then predict, from one sample's latent representation, the representation of a nearby sample. In addition to showing the promise of MYOW on standard datasets used in computer vision, we highlight the power of this idea in a novel application in neuroscience where rich augmentations are not already established. When applied to neural datasets, MYOW outperforms other self-supervised approaches in all examples (in some cases by more than 10%), and surpasses the supervised baseline for most datasets. By learning to predict the latent representation of similar samples, we show that it is possible to learn good representations in new domains where augmentations are still limited.