 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hand-Held Object Reconstruction from In-The-Wild Videos
May 04, 2023Prior works for reconstructing hand-held objects from a single image rely on direct 3D shape supervision which is challenging to gather in real world at scale. Consequently, these approaches do not generalize well when presented with novel objects in in-the-wild settings. While 3D supervision is a major bottleneck, there is an abundance of in-the-wild raw video data showing hand-object interactions. In this paper, we automatically extract 3D supervision (via multiview 2D supervision) from such raw video data to scale up the learning of models for hand-held object reconstruction. This requires tackling two key challenges: unknown camera pose and occlusion. For the former, we use hand pose (predicted from existing techniques, e.g. FrankMocap) as a proxy for object pose. For the latter, we learn data-driven 3D shape priors using synthetic objects from the ObMan dataset. We use these indirect 3D cues to train occupancy networks that predict the 3D shape of objects from a single RGB image. Our experiments on the MOW and HO3D datasets show the effectiveness of these supervisory signals at predicting the 3D shape for real-world hand-held objects without any direct real-world 3D supervision.
MTNeuro: A Benchmark for Evaluating Representations of Brain Structure Across Multiple Levels of Abstraction
Jan 01, 2023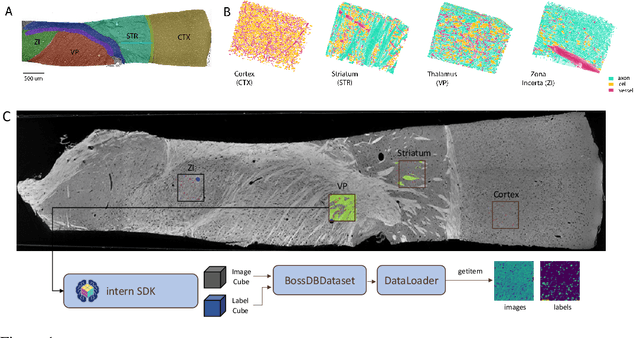
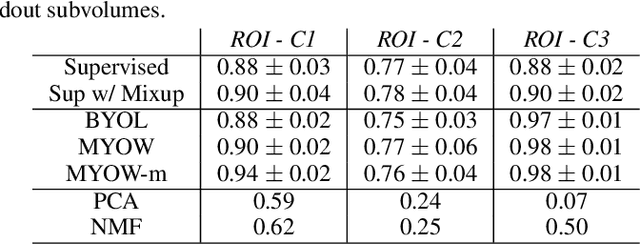

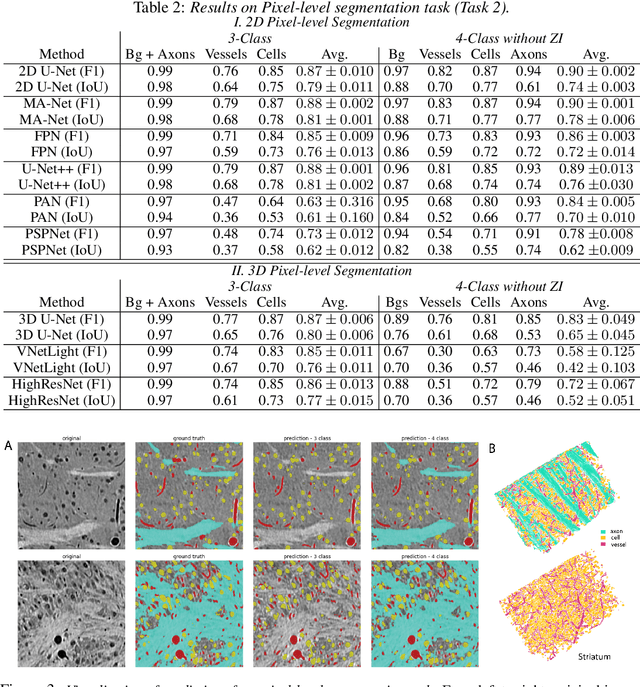
There are multiple scales of abstraction from which we can describe the same image, depending on whether we are focusing on fine-grained details or a more global attribute of the image. In brain mapping, learning to automatically parse images to build representations of both small-scale features (e.g., the presence of cells or blood vessels) and global properties of an image (e.g., which brain region the image comes from) is a crucial and open challenge. However, most existing datasets and benchmarks for neuroanatomy consider only a single downstream task at a time. To bridge this gap, we introduce a new dataset, annotations, and multiple downstream tasks that provide diverse ways to readout information about brain structure and architecture from the same image. Our multi-task neuroimaging benchmark (MTNeuro) is built on volumetric, micrometer-resolution X-ray microtomography images spanning a large thalamocortical section of mouse brain, encompassing multiple cortical and subcortical regions. We generated a number of different prediction challenges and evaluated several supervised and self-supervised models for brain-region prediction and pixel-level semantic segmentation of microstructures. Our experiments not only highlight the rich heterogeneity of this dataset, but also provide insights into how self-supervised approaches can be used to learn representations that capture multiple attributes of a single image and perform well on a variety of downstream tasks. Datasets, code, and pre-trained baseline models are provided at: https://mtneuro.github.io/ .
Learning to Reduce False Positives in Analytic Bug Detectors
Mar 08, 2022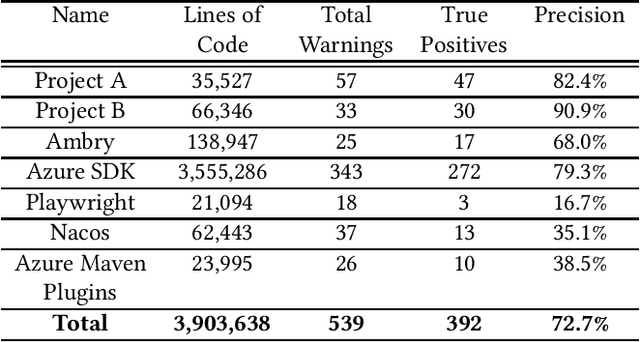
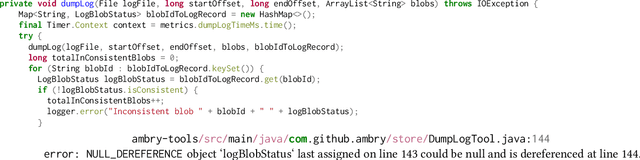
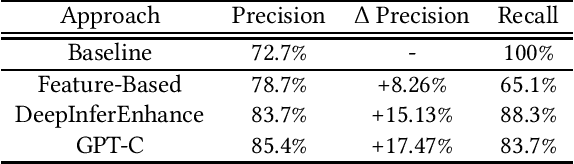
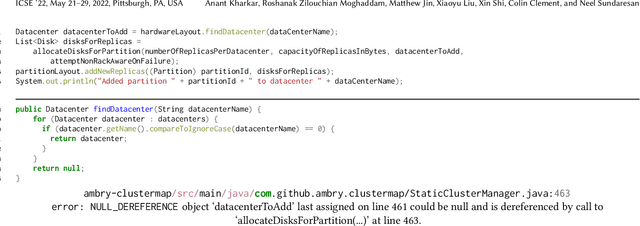
Due to increasingly complex software design and rapid iterative development, code defects and security vulnerabilities are prevalent in modern software. In response, programmers rely on static analysis tools to regularly scan their codebases and find potential bugs. In order to maximize coverage, however, these tools generally tend to report a significant number of false positives, requiring developers to manually verify each warning. To address this problem, we propose a Transformer-based learning approach to identify false positive bug warnings. We demonstrate that our models can improve the precision of static analysis by 17.5%. In addition, we validated the generalizability of this approach across two major bug types: null dereference and resource leak.