 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Emotion Regression with Multi-Objective Optimization and VAD-Aware Audio Modeling for the 10th ABAW EMI Track
Mar 14, 2026We participated in the 10th ABAW Challenge, focusing on the Emotional Mimicry Intensity (EMI) Estimation track on the Hume-Vidmimic2 dataset. This task aims to predict six continuous emotion dimensions: Admiration, Amusement, Determination, Empathic Pain, Excitement, and Joy. Through systematic multimodal exploration of pretrained high-level features, we found that, under our pretrained feature setting, direct feature concatenation outperformed the more complex fusion strategies we tested. This empirical finding motivated us to design a systematic approach built upon three core principles: (i) preserving modality-specific attributes through feature-level concatenation; (ii) improving training stability and metric alignment via multi-objective optimization; and (iii) enriching acoustic representations with a VAD-inspired latent prior. Our final framework integrates concatenation-based multimodal fusion, a shared six-dimensional regression head, multi-objective optimization with MSE, Pearson-correlation, and auxiliary branch supervision, EMA for parameter stabilization, and a VAD-inspired latent prior for the acoustic branch. On the official validation set, the proposed scheme achieved our best mean Pearson Correlation Coefficient of 0.478567.
CPEP: Contrastive Pose-EMG Pre-training Enhances Gesture Generalization on EMG Signals
Sep 04, 2025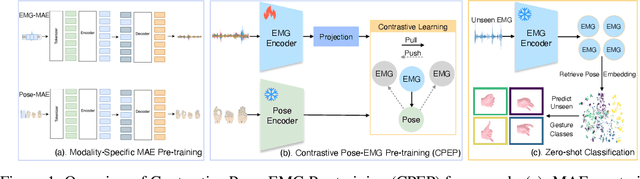

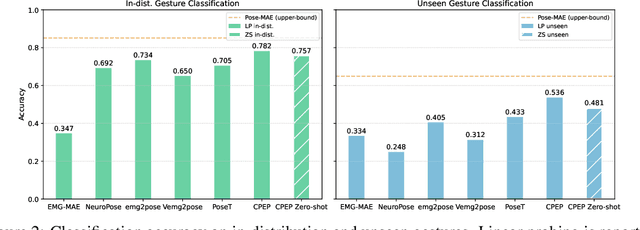
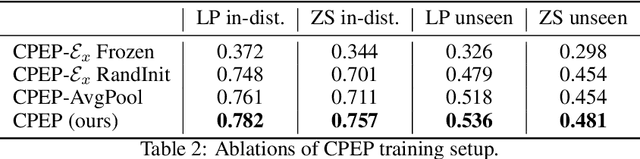
Hand gesture classification using high-quality structured data such as videos, images, and hand skeletons is a well-explored problem in computer vision. Leveraging low-power, cost-effective biosignals, e.g. surface electromyography (sEMG), allows for continuous gesture prediction on wearables. In this paper, we demonstrate that learning representations from weak-modality data that are aligned with those from structured, high-quality data can improve representation quality and enables zero-shot classification. Specifically, we propose a Contrastive Pose-EMG Pre-training (CPEP) framework to align EMG and pose representations, where we learn an EMG encoder that produces high-quality and pose-informative representations. We assess the gesture classification performance of our model through linear probing and zero-shot setups. Our model outperforms emg2pose benchmark models by up to 21% on in-distribution gesture classification and 72% on unseen (out-of-distribution) gesture classification.
MEF-Explore: Communication-Constrained Multi-Robot Entropy-Field-Based Exploration
May 29, 2025Collaborative multiple robots for unknown environment exploration have become mainstream due to their remarkable performance and efficiency. However, most existing methods assume perfect robots' communication during exploration, which is unattainable in real-world settings. Though there have been recent works aiming to tackle communication-constrained situations, substantial room for advancement remains for both information-sharing and exploration strategy aspects. In this paper, we propose a Communication-Constrained Multi-Robot Entropy-Field-Based Exploration (MEF-Explore). The first module of the proposed method is the two-layer inter-robot communication-aware information-sharing strategy. A dynamic graph is used to represent a multi-robot network and to determine communication based on whether it is low-speed or high-speed. Specifically, low-speed communication, which is always accessible between every robot, can only be used to share their current positions. If robots are within a certain range, high-speed communication will be available for inter-robot map merging. The second module is the entropy-field-based exploration strategy. Particularly, robots explore the unknown area distributedly according to the novel forms constructed to evaluate the entropies of frontiers and robots. These entropies can also trigger implicit robot rendezvous to enhance inter-robot map merging if feasible. In addition, we include the duration-adaptive goal-assigning module to manage robots' goal assignment. The simulation results demonstrate that our MEF-Explore surpasses the existing ones regarding exploration time and success rate in all scenarios. For real-world experiments, our method leads to a 21.32% faster exploration time and a 16.67% higher success rate compared to the baseline.
Your contrastive learning problem is secretly a distribution alignment problem
Feb 27, 2025Despite the success of contrastive learning (CL) in vision and language, its theoretical foundations and mechanisms for building representations remain poorly understood. In this work, we build connections between noise contrastive estimation losses widely used in CL and distribution alignment with entropic optimal transport (OT). This connection allows us to develop a family of different losses and multistep iterative variants for existing CL methods. Intuitively, by using more information from the distribution of latents, our approach allows a more distribution-aware manipulation of the relationships within augmented sample sets. We provide theoretical insights and experimental evidence demonstrating the benefits of our approach for {\em generalized contrastive alignment}. Through this framework, it is possible to leverage tools in OT to build unbalanced losses to handle noisy views and customize the representation space by changing the constraints on alignment. By reframing contrastive learning as an alignment problem and leveraging existing optimization tools for OT, our work provides new insights and connections between different self-supervised learning models in addition to new tools that can be more easily adapted to incorporate domain knowledge into learning.
* 10 pages, 5 figures, NeurIPS 2024 submission, includes supplementary material
TransPathNet: A Novel Two-Stage Framework for Indoor Radio Map Prediction
Jan 27, 2025


Accurate indoor pathloss prediction is crucial for optimizing wireless communication in indoor settings, where diverse materials and complex electromagnetic interactions pose significant modeling challenges. This paper introduces TransPathNet, a novel two-stage deep learning framework that leverages transformer-based feature extraction and multiscale convolutional attention decoding to generate high-precision indoor radio pathloss maps. TransPathNet demonstrates state-of-the-art performance in the ICASSP 2025 Indoor Pathloss Radio Map Prediction Challenge, achieving an overall Root Mean Squared Error (RMSE) of 10.397 dB on the challenge full test set and 9.73 dB on the challenge Kaggle test set, showing excellent generalization capabilities across different indoor geometries, frequencies, and antenna patterns. Our project page, including the associated code, is available at https://lixin.ai/TransPathNet/.
Context-Aware Adapter Tuning for Few-Shot Relation Learning in Knowledge Graphs
Oct 11, 2024



Knowledge graphs (KGs) are instrumental in various real-world applications, yet they often suffer from incompleteness due to missing relations. To predict instances for novel relations with limited training examples, few-shot relation learning approaches have emerged, utilizing techniques such as meta-learning. However, the assumption is that novel relations in meta-testing and base relations in meta-training are independently and identically distributed, which may not hold in practice. To address the limitation, we propose RelAdapter, a context-aware adapter for few-shot relation learning in KGs designed to enhance the adaptation process in meta-learning. First, RelAdapter is equipped with a lightweight adapter module that facilitates relation-specific, tunable adaptation of meta-knowledge in a parameter-efficient manner. Second, RelAdapter is enriched with contextual information about the target relation, enabling enhanced adaptation to each distinct relation. Extensive experiments on three benchmark KGs validate the superiority of RelAdapter over state-of-the-art methods.
Generalizable autoregressive modeling of time series through functional narratives
Oct 10, 2024



Time series data are inherently functions of time, yet current transformers often learn time series by modeling them as mere concatenations of time periods, overlooking their functional properties. In this work, we propose a novel objective for transformers that learn time series by re-interpreting them as temporal functions. We build an alternative sequence of time series by constructing degradation operators of different intensity in the functional space, creating augmented variants of the original sample that are abstracted or simplified to different degrees. Based on the new set of generated sequence, we train an autoregressive transformer that progressively recovers the original sample from the most simplified variant. Analogous to the next word prediction task in languages that learns narratives by connecting different words, our autoregressive transformer aims to learn the Narratives of Time Series (NoTS) by connecting different functions in time. Theoretically, we justify the construction of the alternative sequence through its advantages in approximating functions. When learning time series data with transformers, constructing sequences of temporal functions allows for a broader class of approximable functions (e.g., differentiation) compared to sequences of time periods, leading to a 26\% performance improvement in synthetic feature regression experiments. Experimentally, we validate NoTS in 3 different tasks across 22 real-world datasets, where we show that NoTS significantly outperforms other pre-training methods by up to 6\%. Additionally, combining NoTS on top of existing transformer architectures can consistently boost the performance. Our results demonstrate the potential of NoTS as a general-purpose dynamic learner, offering a viable alternative for developing foundation models for time series analysis.
Diversified and Adaptive Negative Sampling on Knowledge Graphs
Oct 10, 2024



In knowledge graph embedding, aside from positive triplets (ie: facts in the knowledge graph), the negative triplets used for training also have a direct influence on the model performance. In reality, since knowledge graphs are sparse and incomplete, negative triplets often lack explicit labels, and thus they are often obtained from various sampling strategies (eg: randomly replacing an entity in a positive triplet). An ideal sampled negative triplet should be informative enough to help the model train better. However, existing methods often ignore diversity and adaptiveness in their sampling process, which harms the informativeness of negative triplets. As such, we propose a generative adversarial approach called Diversified and Adaptive Negative Sampling DANS on knowledge graphs. DANS is equipped with a two-way generator that generates more diverse negative triplets through two pathways, and an adaptive mechanism that produces more fine-grained examples by localizing the global generator for different entities and relations. On the one hand, the two-way generator increase the overall informativeness with more diverse negative examples; on the other hand, the adaptive mechanism increases the individual sample-wise informativeness with more fine-grained sampling. Finally, we evaluate the performance of DANS on three benchmark knowledge graphs to demonstrate its effectiveness through quantitative and qualitative experiments.
GLIMMER: Incorporating Graph and Lexical Features in Unsupervised Multi-Document Summarization
Aug 19, 2024



Pre-trained language models are increasingly being used in multi-document summarization tasks. However, these models need large-scale corpora for pre-training and are domain-dependent. Other non-neural unsupervised summarization approaches mostly rely on key sentence extraction, which can lead to information loss. To address these challenges, we propose a lightweight yet effective unsupervised approach called GLIMMER: a Graph and LexIcal features based unsupervised Multi-docuMEnt summaRization approach. It first constructs a sentence graph from the source documents, then automatically identifies semantic clusters by mining low-level features from raw texts, thereby improving intra-cluster correlation and the fluency of generated sentences. Finally, it summarizes clusters into natural sentences. Experiments conducted on Multi-News, Multi-XScience and DUC-2004 demonstrate that our approach outperforms existing unsupervised approaches. Furthermore, it surpasses state-of-the-art pre-trained multi-document summarization models (e.g. PEGASUS and PRIMERA) under zero-shot settings in terms of ROUGE scores. Additionally, human evaluations indicate that summaries generated by GLIMMER achieve high readability and informativeness scores. Our code is available at https://github.com/Oswald1997/GLIMMER.
Model-driven Heart Rate Estimation and Heart Murmur Detection based on Phonocardiogram
Jul 25, 2024
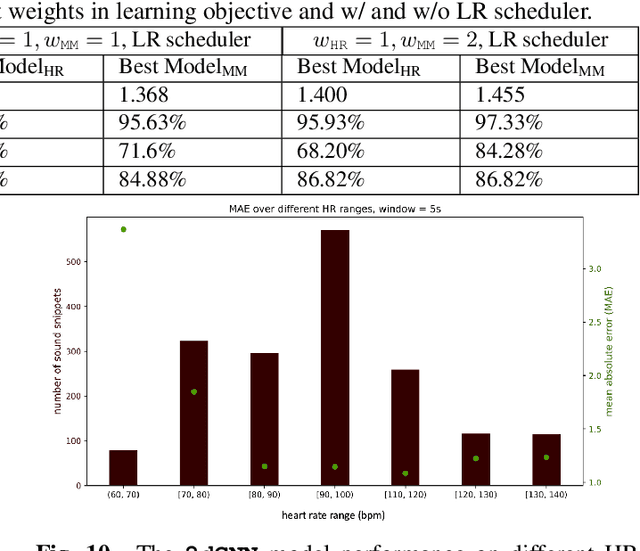
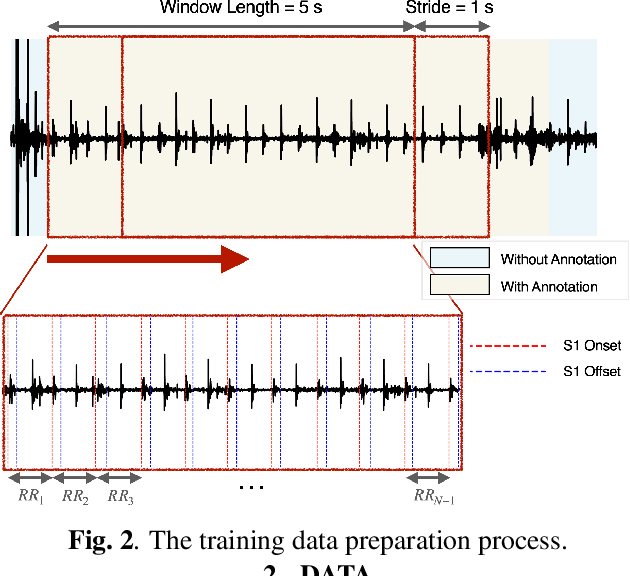
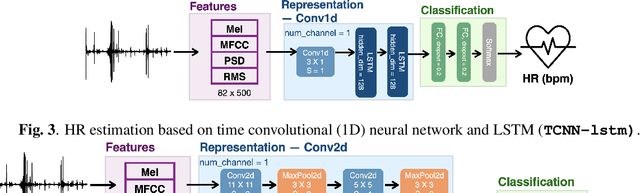
Acoustic signals are crucial for health monitoring, particularly heart sounds which provide essential data like heart rate and detect cardiac anomalies such as murmurs. This study utilizes a publicly available phonocardiogram (PCG) dataset to estimate heart rate using model-driven methods and extends the best-performing model to a multi-task learning (MTL) framework for simultaneous heart rate estimation and murmur detection. Heart rate estimates are derived using a sliding window technique on heart sound snippets, analyzed with a combination of acoustic features (Mel spectrogram, cepstral coefficients, power spectral density, root mean square energy). Our findings indicate that a 2D convolutional neural network (\textbf{\texttt{2dCNN}}) is most effective for heart rate estimation, achieving a mean absolute error (MAE) of 1.312 bpm. We systematically investigate the impact of different feature combinations and find that utilizing all four features yields the best results. The MTL model (\textbf{\texttt{2dCNN-MTL}}) achieves accuracy over 95% in murmur detection, surpassing existing models, while maintaining an MAE of 1.636 bpm in heart rate estimation, satisfying the requirements stated by Association for the Advancement of Medical Instrumentation (AAMI).