 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechForensics: Audio-Visual Speech Representation Learning for Face Forgery Detection
Aug 13, 2025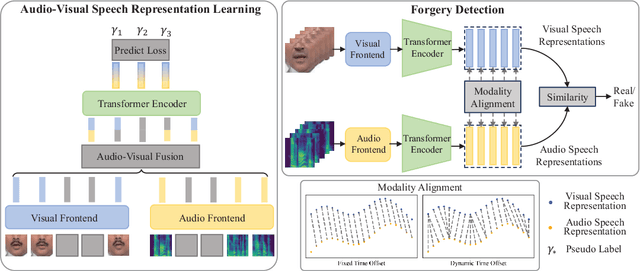
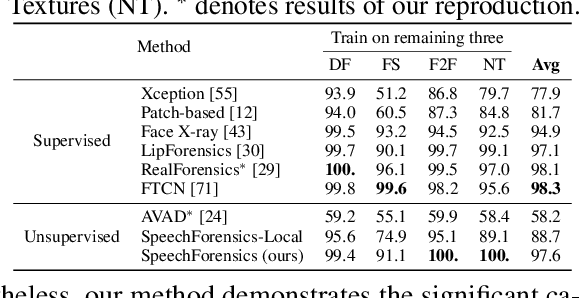
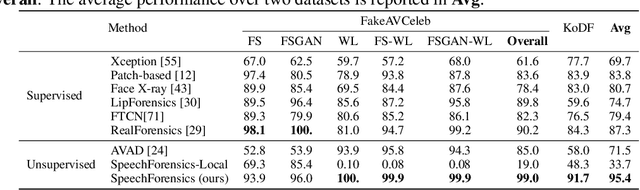
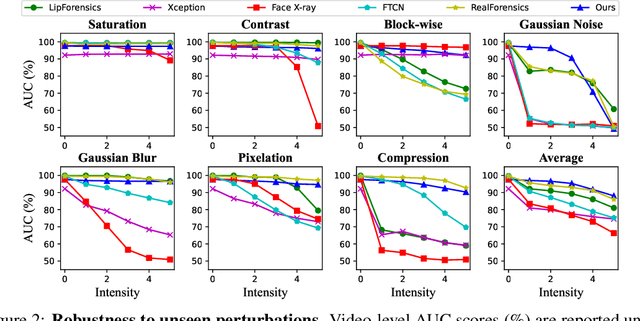
Detection of face forgery videos remains a formidable challenge in the field of digital forensics, especially the generalization to unseen datasets and common perturbations. In this paper, we tackle this issue by leveraging the synergy between audio and visual speech elements, embarking on a novel approach through audio-visual speech representation learning. Our work is motivated by the finding that audio signals, enriched with speech content, can provide precise information effectively reflecting facial movements. To this end, we first learn precise audio-visual speech representations on real videos via a self-supervised masked prediction task, which encodes both local and global semantic information simultaneously. Then, the derived model is directly transferred to the forgery detection task. Extensive experiments demonstrate that our method outperforms the state-of-the-art methods in terms of cross-dataset generalization and robustness, without the participation of any fake video in model training. Code is available at https://github.com/Eleven4AI/SpeechForensics.
* Accepted by NeurIPS 2024
GLIMMER: Incorporating Graph and Lexical Features in Unsupervised Multi-Document Summarization
Aug 19, 2024



Pre-trained language models are increasingly being used in multi-document summarization tasks. However, these models need large-scale corpora for pre-training and are domain-dependent. Other non-neural unsupervised summarization approaches mostly rely on key sentence extraction, which can lead to information loss. To address these challenges, we propose a lightweight yet effective unsupervised approach called GLIMMER: a Graph and LexIcal features based unsupervised Multi-docuMEnt summaRization approach. It first constructs a sentence graph from the source documents, then automatically identifies semantic clusters by mining low-level features from raw texts, thereby improving intra-cluster correlation and the fluency of generated sentences. Finally, it summarizes clusters into natural sentences. Experiments conducted on Multi-News, Multi-XScience and DUC-2004 demonstrate that our approach outperforms existing unsupervised approaches. Furthermore, it surpasses state-of-the-art pre-trained multi-document summarization models (e.g. PEGASUS and PRIMERA) under zero-shot settings in terms of ROUGE scores. Additionally, human evaluations indicate that summaries generated by GLIMMER achieve high readability and informativeness scores. Our code is available at https://github.com/Oswald1997/GLIMMER.