 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechForensics: Audio-Visual Speech Representation Learning for Face Forgery Detection
Aug 13, 2025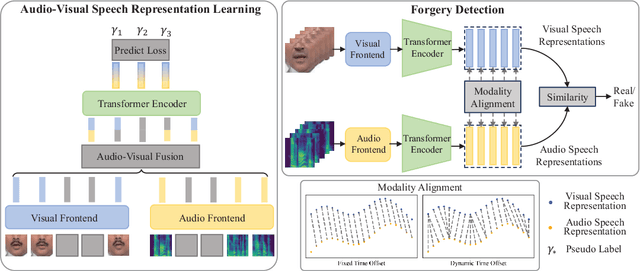
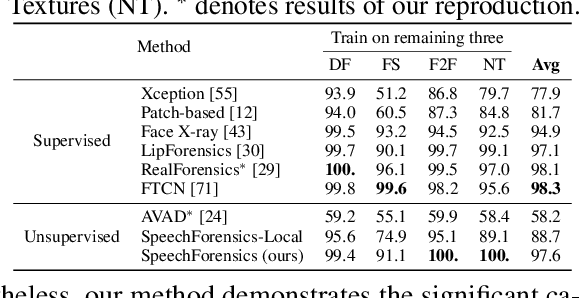
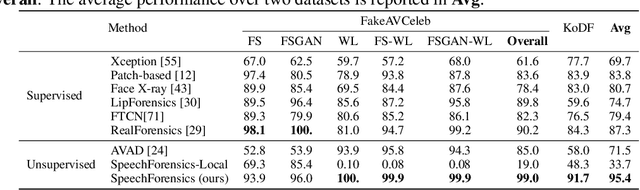
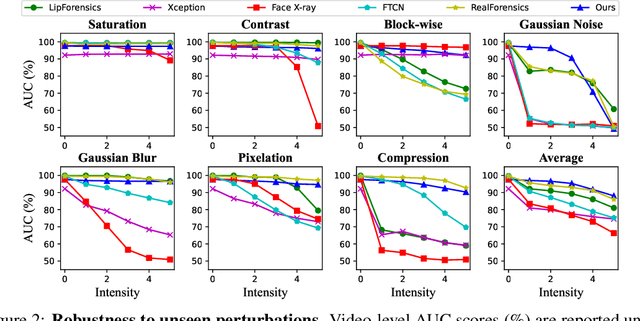
Detection of face forgery videos remains a formidable challenge in the field of digital forensics, especially the generalization to unseen datasets and common perturbations. In this paper, we tackle this issue by leveraging the synergy between audio and visual speech elements, embarking on a novel approach through audio-visual speech representation learning. Our work is motivated by the finding that audio signals, enriched with speech content, can provide precise information effectively reflecting facial movements. To this end, we first learn precise audio-visual speech representations on real videos via a self-supervised masked prediction task, which encodes both local and global semantic information simultaneously. Then, the derived model is directly transferred to the forgery detection task. Extensive experiments demonstrate that our method outperforms the state-of-the-art methods in terms of cross-dataset generalization and robustness, without the participation of any fake video in model training. Code is available at https://github.com/Eleven4AI/SpeechForensics.
* Accepted by NeurIPS 2024
How Generalizable are Deepfake Detectors? An Empirical Study
Aug 08, 2023



Deepfake videos and images are becoming increasingly credible, posing a significant threat given their potential to facilitate fraud or bypass access control systems. This has motivated the development of deepfake detection methods, in which deep learning models are trained to distinguish between real and synthesized footage. Unfortunately, existing detection models struggle to generalize to deepfakes from datasets they were not trained on, but little work has been done to examine why or how this limitation can be addressed. In this paper, we present the first empirical study on the generalizability of deepfake detectors, an essential goal for detectors to stay one step ahead of attackers. Our study utilizes six deepfake datasets, five deepfake detection methods, and two model augmentation approaches, confirming that detectors do not generalize in zero-shot settings. Additionally, we find that detectors are learning unwanted properties specific to synthesis methods and struggling to extract discriminative features, limiting their ability to generalize. Finally, we find that there are neurons universally contributing to detection across seen and unseen datasets, illuminating a possible path forward to zero-shot generalizability.