 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3BASiL: An Algorithmic Framework for Sparse plus Low-Rank Compression of LLMs
Mar 02, 2026Sparse plus Low-Rank $(\mathbf{S} + \mathbf{LR})$ decomposition of Large Language Models (LLMs) has emerged as a promising direction in model compression, aiming to decompose pre-trained model weights into a sum of sparse and low-rank matrices $(\mathbf{W} \approx \mathbf{S} + \mathbf{LR})$. Despite recent progress, existing methods often suffer from substantial performance degradation compared to dense models. In this work, we introduce 3BASiL-TM, an efficient one-shot post-training method for $(\mathbf{S} + \mathbf{LR})$ decomposition of LLMs that addresses this gap. Our approach first introduces a novel 3-Block Alternating Direction Method of Multipliers (ADMM) method, termed 3BASiL, to minimize the layer-wise reconstruction error with convergence guarantees. We then design an efficient transformer-matching (TM) refinement step that jointly optimizes the sparse and low-rank components across transformer layers. This step minimizes a novel memory-efficient loss that aligns outputs at the transformer level. Notably, the TM procedure is universal as it can enhance any $(\mathbf{S} + \mathbf{LR})$ decomposition, including pure sparsity. Our numerical experiments show that 3BASiL-TM reduces the WikiText2 perplexity gap relative to dense LLaMA-8B model by over 30% under a (2:4 Sparse + 64 LR) configuration, compared to prior methods. Moreover, our method achieves over 2.5x faster compression runtime on an A100 GPU compared to SOTA $(\mathbf{S} + \mathbf{LR})$ method. Our code is available at https://github.com/mazumder-lab/3BASiL.
Efficient and Debiased Learning of Average Hazard Under Non-Proportional Hazards
Feb 13, 2026The hazard ratio from the Cox proportional hazards model is a ubiquitous summary of treatment effect. However, when hazards are non-proportional, the hazard ratio can lose a stable causal interpretation and become study-dependent because it effectively averages time-varying effects with weights determined by follow-up and censoring. We consider the average hazard (AH) as an alternative causal estimand: a population-level person-time event rate that remains well-defined and interpretable without assuming proportional hazards. Although AH can be estimated nonparametrically and regression-style adjustments have been proposed, existing approaches do not provide a general framework for flexible, high-dimensional nuisance estimation with valid sqrt{n} inference. We address this gap by developing a semiparametric, doubly robust framework for covariate-adjusted AH. We establish pathwise differentiability of AH in the nonparametric model, derive its efficient influence function, and construct cross-fitted, debiased estimators that leverage machine learning for nuisance estimation while retaining asymptotically normal, sqrt{n}-consistent inference under mild product-rate conditions. Simulations demonstrate that the proposed estimator achieves small bias and near-nominal confidence-interval coverage across proportional and non-proportional hazards settings, including crossing-hazards regimes where Cox-based summaries can be unstable. We illustrate practical utility in comparative effectiveness research by comparing immunotherapy regimens for advanced melanoma using SEER-Medicare linked data.
SpeechForensics: Audio-Visual Speech Representation Learning for Face Forgery Detection
Aug 13, 2025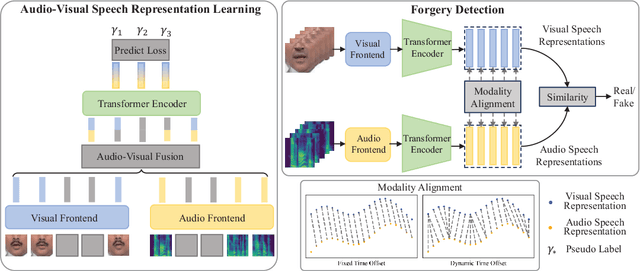
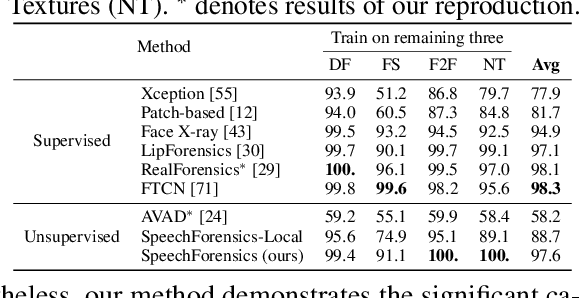
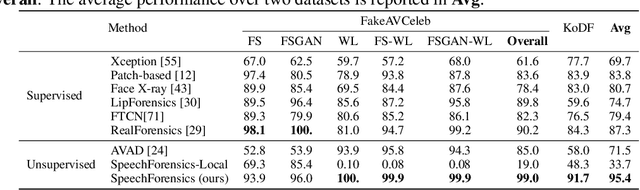
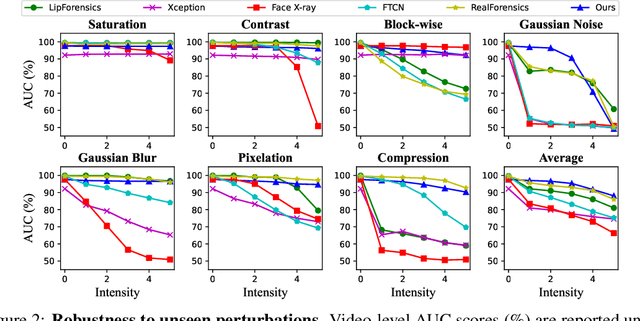
Detection of face forgery videos remains a formidable challenge in the field of digital forensics, especially the generalization to unseen datasets and common perturbations. In this paper, we tackle this issue by leveraging the synergy between audio and visual speech elements, embarking on a novel approach through audio-visual speech representation learning. Our work is motivated by the finding that audio signals, enriched with speech content, can provide precise information effectively reflecting facial movements. To this end, we first learn precise audio-visual speech representations on real videos via a self-supervised masked prediction task, which encodes both local and global semantic information simultaneously. Then, the derived model is directly transferred to the forgery detection task. Extensive experiments demonstrate that our method outperforms the state-of-the-art methods in terms of cross-dataset generalization and robustness, without the participation of any fake video in model training. Code is available at https://github.com/Eleven4AI/SpeechForensics.
* Accepted by NeurIPS 2024
TSENOR: Highly-Efficient Algorithm for Finding Transposable N:M Sparse Masks
May 29, 2025Network pruning reduces the computational requirements of large neural networks, with N:M sparsity -- retaining only N out of every M consecutive weights -- offering a compelling balance between compressed model quality and hardware acceleration. However, N:M sparsity only accelerates forward-pass computations, as N:M patterns are not preserved during matrix transposition, limiting efficiency during training where both passes are computationally intensive. While transposable N:M sparsity has been proposed to address this limitation, existing methods for finding transposable N:M sparse masks either fail to scale to large models or are restricted to M=4 which results in suboptimal compression-accuracy trade-off. We introduce an efficient solver for transposable N:M masks that scales to billion-parameter models. We formulate mask generation as optimal transport problems and solve through entropy regularization and Dykstra's algorithm, followed by a rounding procedure. Our tensor-based implementation exploits GPU parallelism, achieving up to 100x speedup with only 1-10% error compared to existing methods. Our approach can be integrated with layer-wise N:M pruning frameworks including Wanda, SparseGPT and ALPS to produce transposable N:M sparse models with arbitrary N:M values. Experiments show that LLaMA3.2-8B with transposable 16:32 sparsity maintains performance close to its standard N:M counterpart and outperforms standard 2:4 sparse model, showing the practical value of our approach.
Integrating Chaotic Evolutionary and Local Search Techniques in Decision Space for Enhanced Evolutionary Multi-Objective Optimization
Nov 12, 2024



This paper presents innovative approaches to optimization problems, focusing on both Single-Objective Multi-Modal Optimization (SOMMOP) and Multi-Objective Optimization (MOO). In SOMMOP, we integrate chaotic evolution with niching techniques, as well as Persistence-Based Clustering combined with Gaussian mutation. The proposed algorithms, Chaotic Evolution with Deterministic Crowding (CEDC) and Chaotic Evolution with Clustering Algorithm (CECA), utilize chaotic dynamics to enhance population diversity and improve search efficiency. For MOO, we extend these methods into a comprehensive framework that incorporates Uncertainty-Based Selection, Adaptive Parameter Tuning, and introduces a radius \( R \) concept in deterministic crowding, which enables clearer and more precise separation of populations at peak points. Experimental results demonstrate that the proposed algorithms outperform traditional methods, achieving superior optimization accuracy and robustness across a variety of benchmark functions.
GLIMMER: Incorporating Graph and Lexical Features in Unsupervised Multi-Document Summarization
Aug 19, 2024



Pre-trained language models are increasingly being used in multi-document summarization tasks. However, these models need large-scale corpora for pre-training and are domain-dependent. Other non-neural unsupervised summarization approaches mostly rely on key sentence extraction, which can lead to information loss. To address these challenges, we propose a lightweight yet effective unsupervised approach called GLIMMER: a Graph and LexIcal features based unsupervised Multi-docuMEnt summaRization approach. It first constructs a sentence graph from the source documents, then automatically identifies semantic clusters by mining low-level features from raw texts, thereby improving intra-cluster correlation and the fluency of generated sentences. Finally, it summarizes clusters into natural sentences. Experiments conducted on Multi-News, Multi-XScience and DUC-2004 demonstrate that our approach outperforms existing unsupervised approaches. Furthermore, it surpasses state-of-the-art pre-trained multi-document summarization models (e.g. PEGASUS and PRIMERA) under zero-shot settings in terms of ROUGE scores. Additionally, human evaluations indicate that summaries generated by GLIMMER achieve high readability and informativeness scores. Our code is available at https://github.com/Oswald1997/GLIMMER.
ALPS: Improved Optimization for Highly Sparse One-Shot Pruning for Large Language Models
Jun 12, 2024



The impressive performance of Large Language Models (LLMs) across various natural language processing tasks comes at the cost of vast computational resources and storage requirements. One-shot pruning techniques offer a way to alleviate these burdens by removing redundant weights without the need for retraining. Yet, the massive scale of LLMs often forces current pruning approaches to rely on heuristics instead of optimization-based techniques, potentially resulting in suboptimal compression. In this paper, we introduce ALPS, an optimization-based framework that tackles the pruning problem using the operator splitting technique and a preconditioned conjugate gradient-based post-processing step. Our approach incorporates novel techniques to accelerate and theoretically guarantee convergence while leveraging vectorization and GPU parallelism for efficiency. ALPS substantially outperforms state-of-the-art methods in terms of the pruning objective and perplexity reduction, particularly for highly sparse models. On the OPT-30B model with 70% sparsity, ALPS achieves a 13% reduction in test perplexity on the WikiText dataset and a 19% improvement in zero-shot benchmark performance compared to existing methods.
FALCON: FLOP-Aware Combinatorial Optimization for Neural Network Pruning
Mar 11, 2024



The increasing computational demands of modern neural networks present deployment challenges on resource-constrained devices. Network pruning offers a solution to reduce model size and computational cost while maintaining performance. However, most current pruning methods focus primarily on improving sparsity by reducing the number of nonzero parameters, often neglecting other deployment costs such as inference time, which are closely related to the number of floating-point operations (FLOPs). In this paper, we propose FALCON, a novel combinatorial-optimization-based framework for network pruning that jointly takes into account model accuracy (fidelity), FLOPs, and sparsity constraints. A main building block of our approach is an integer linear program (ILP) that simultaneously handles FLOP and sparsity constraints. We present a novel algorithm to approximately solve the ILP. We propose a novel first-order method for our optimization framework which makes use of our ILP solver. Using problem structure (e.g., the low-rank structure of approx. Hessian), we can address instances with millions of parameters. Our experiments demonstrate that FALCON achieves superior accuracy compared to other pruning approaches within a fixed FLOP budget. For instance, for ResNet50 with 20% of the total FLOPs retained, our approach improves the accuracy by 48% relative to state-of-the-art. Furthermore, in gradual pruning settings with re-training between pruning steps, our framework outperforms existing pruning methods, emphasizing the significance of incorporating both FLOP and sparsity constraints for effective network pruning.
Human Pose-based Estimation, Tracking and Action Recognition with Deep Learning: A Survey
Oct 19, 2023



Human pose analysis has garnered significant attention within both the research community and practical applications, owing to its expanding array of uses, including gaming, video surveillance, sports performance analysis, and human-computer interactions, among others. The advent of deep learning has significantly improved the accuracy of pose capture, making pose-based applications increasingly practical. This paper presents a comprehensive survey of pose-based applications utilizing deep learning, encompassing pose estimation, pose tracking, and action recognition.Pose estimation involves the determination of human joint positions from images or image sequences. Pose tracking is an emerging research direction aimed at generating consistent human pose trajectories over time. Action recognition, on the other hand, targets the identification of action types using pose estimation or tracking data. These three tasks are intricately interconnected, with the latter often reliant on the former. In this survey, we comprehensively review related works, spanning from single-person pose estimation to multi-person pose estimation, from 2D pose estimation to 3D pose estimation, from single image to video, from mining temporal context gradually to pose tracking, and lastly from tracking to pose-based action recognition. As a survey centered on the application of deep learning to pose analysis, we explicitly discuss both the strengths and limitations of existing techniques. Notably, we emphasize methodologies for integrating these three tasks into a unified framework within video sequences. Additionally, we explore the challenges involved and outline potential directions for future research.
Fast as CHITA: Neural Network Pruning with Combinatorial Optimization
Feb 28, 2023



The sheer size of modern neural networks makes model serving a serious computational challenge. A popular class of compression techniques overcomes this challenge by pruning or sparsifying the weights of pretrained networks. While useful, these techniques often face serious tradeoffs between computational requirements and compression quality. In this work, we propose a novel optimization-based pruning framework that considers the combined effect of pruning (and updating) multiple weights subject to a sparsity constraint. Our approach, CHITA, extends the classical Optimal Brain Surgeon framework and results in significant improvements in speed, memory, and performance over existing optimization-based approaches for network pruning. CHITA's main workhorse performs combinatorial optimization updates on a memory-friendly representation of local quadratic approximation(s) of the loss function. On a standard benchmark of pretrained models and datasets, CHITA leads to significantly better sparsity-accuracy tradeoffs than competing methods. For example, for MLPNet with only 2% of the weights retained, our approach improves the accuracy by 63% relative to the state of the art. Furthermore, when used in conjunction with fine-tuning SGD steps, our method achieves significant accuracy gains over the state-of-the-art approaches.