 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Discrepancy Learning: Synthetic Faces Detection Based on Multi-Reconstruction
Apr 10, 2025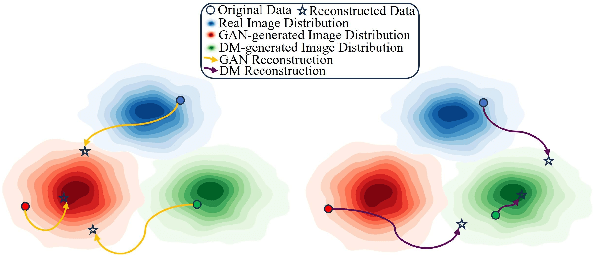

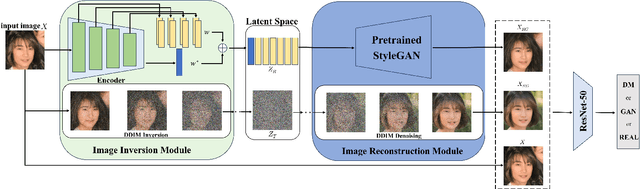

Advances in image generation enable hyper-realistic synthetic faces but also pose risks, thus making synthetic face detection crucial. Previous research focuses on the general differences between generated images and real images, often overlooking the discrepancies among various generative techniques. In this paper, we explore the intrinsic relationship between synthetic images and their corresponding generation technologies. We find that specific images exhibit significant reconstruction discrepancies across different generative methods and that matching generation techniques provide more accurate reconstructions. Based on this insight, we propose a Multi-Reconstruction-based detector. By reversing and reconstructing images using multiple generative models, we analyze the reconstruction differences among real, GAN-generated, and DM-generated images to facilitate effective differentiation. Additionally, we introduce the Asian Synthetic Face Dataset (ASFD), containing synthetic Asian faces generated with various GANs and DMs. This dataset complements existing synthetic face datasets. Experimental results demonstrate that our detector achieves exceptional performance, with strong generalization and robustness.
Exploring Depth Information for Detecting Manipulated Face Videos
Nov 27, 2024Face manipulation detection has been receiving a lot of attention for the reliability and security of the face images/videos. Recent studies focus on using auxiliary information or prior knowledge to capture robust manipulation traces, which are shown to be promising. As one of the important face features, the face depth map, which has shown to be effective in other areas such as face recognition or face detection, is unfortunately paid little attention to in literature for face manipulation detection. In this paper, we explore the possibility of incorporating the face depth map as auxiliary information for robust face manipulation detection. To this end, we first propose a Face Depth Map Transformer (FDMT) to estimate the face depth map patch by patch from an RGB face image, which is able to capture the local depth anomaly created due to manipulation. The estimated face depth map is then considered as auxiliary information to be integrated with the backbone features using a Multi-head Depth Attention (MDA) mechanism that is newly designed. We also propose an RGB-Depth Inconsistency Attention (RDIA) module to effectively capture the inter-frame inconsistency for multi-frame input. Various experiments demonstrate the advantage of our proposed method for face manipulation detection.
Are handcrafted filters helpful for attributing AI-generated images?
Jul 23, 2024Recently, a vast number of image generation models have been proposed, which raises concerns regarding the misuse of these artificial intelligence (AI) techniques for generating fake images. To attribute the AI-generated images, existing schemes usually design and train deep neural networks (DNNs) to learn the model fingerprints, which usually requires a large amount of data for effective learning. In this paper, we aim to answer the following two questions for AI-generated image attribution, 1) is it possible to design useful handcrafted filters to facilitate the fingerprint learning? and 2) how we could reduce the amount of training data after we incorporate the handcrafted filters? We first propose a set of Multi-Directional High-Pass Filters (MHFs) which are capable to extract the subtle fingerprints from various directions. Then, we propose a Directional Enhanced Feature Learning network (DEFL) to take both the MHFs and randomly-initialized filters into consideration. The output of the DEFL is fused with the semantic features to produce a compact fingerprint. To make the compact fingerprint discriminative among different models, we propose a Dual-Margin Contrastive (DMC) loss to tune our DEFL. Finally, we propose a reference based fingerprint classification scheme for image attribution. Experimental results demonstrate that it is indeed helpful to use our MHFs for attributing the AI-generated images. The performance of our proposed method is significantly better than the state-of-the-art for both the closed-set and open-set image attribution, where only a small amount of images are required for training.
ALPS: Improved Optimization for Highly Sparse One-Shot Pruning for Large Language Models
Jun 12, 2024



The impressive performance of Large Language Models (LLMs) across various natural language processing tasks comes at the cost of vast computational resources and storage requirements. One-shot pruning techniques offer a way to alleviate these burdens by removing redundant weights without the need for retraining. Yet, the massive scale of LLMs often forces current pruning approaches to rely on heuristics instead of optimization-based techniques, potentially resulting in suboptimal compression. In this paper, we introduce ALPS, an optimization-based framework that tackles the pruning problem using the operator splitting technique and a preconditioned conjugate gradient-based post-processing step. Our approach incorporates novel techniques to accelerate and theoretically guarantee convergence while leveraging vectorization and GPU parallelism for efficiency. ALPS substantially outperforms state-of-the-art methods in terms of the pruning objective and perplexity reduction, particularly for highly sparse models. On the OPT-30B model with 70% sparsity, ALPS achieves a 13% reduction in test perplexity on the WikiText dataset and a 19% improvement in zero-shot benchmark performance compared to existing methods.
On the Convergence of CART under Sufficient Impurity Decrease Condition
Oct 26, 2023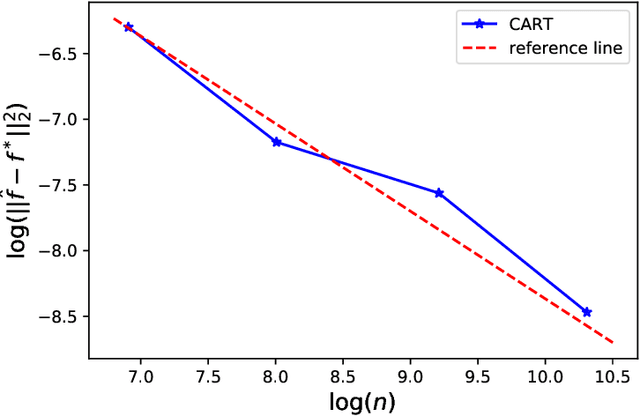
The decision tree is a flexible machine learning model that finds its success in numerous applications. It is usually fitted in a recursively greedy manner using CART. In this paper, we investigate the convergence rate of CART under a regression setting. First, we establish an upper bound on the prediction error of CART under a sufficient impurity decrease (SID) condition \cite{chi2022asymptotic} -- our result improves upon the known result by \cite{chi2022asymptotic} under a similar assumption. Furthermore, we provide examples that demonstrate the error bound cannot be further improved by more than a constant or a logarithmic factor. Second, we introduce a set of easily verifiable sufficient conditions for the SID condition. Specifically, we demonstrate that the SID condition can be satisfied in the case of an additive model, provided that the component functions adhere to a ``locally reverse Poincar{\'e} inequality". We discuss several well-known function classes in non-parametric estimation to illustrate the practical utility of this concept.
Exploring Depth Information for Face Manipulation Detection
Dec 29, 2022Face manipulation detection has been receiving a lot of attention for the reliability and security of the face images. Recent studies focus on using auxiliary information or prior knowledge to capture robust manipulation traces, which are shown to be promising. As one of the important face features, the face depth map, which has shown to be effective in other areas such as the face recognition or face detection, is unfortunately paid little attention to in literature for detecting the manipulated face images. In this paper, we explore the possibility of incorporating the face depth map as auxiliary information to tackle the problem of face manipulation detection in real world applications. To this end, we first propose a Face Depth Map Transformer (FDMT) to estimate the face depth map patch by patch from a RGB face image, which is able to capture the local depth anomaly created due to manipulation. The estimated face depth map is then considered as auxiliary information to be integrated with the backbone features using a Multi-head Depth Attention (MDA) mechanism that is newly designed. Various experiments demonstrate the advantage of our proposed method for face manipulation detection.
OSS Mentor A framework for improving developers contributions via deep reinforcement learning
Oct 24, 2022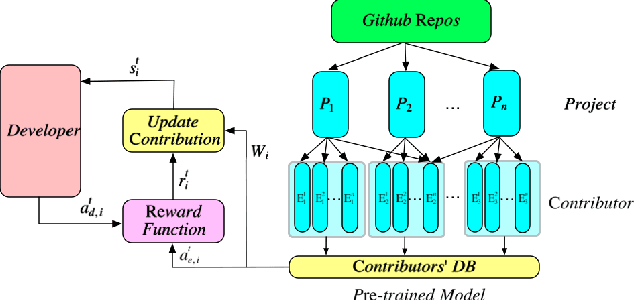
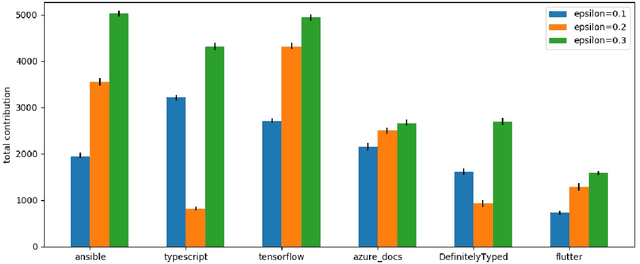
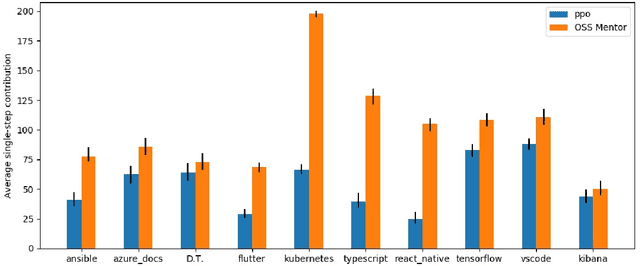
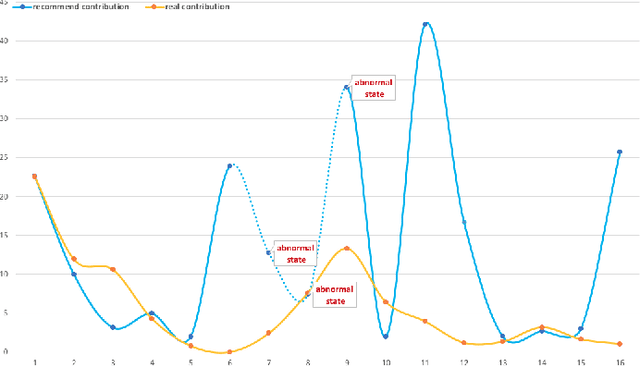
In open source project governance, there has been a lot of concern about how to measure developers' contributions. However, extremely sparse work has focused on enabling developers to improve their contributions, while it is significant and valuable. In this paper, we introduce a deep reinforcement learning framework named Open Source Software(OSS) Mentor, which can be trained from empirical knowledge and then adaptively help developers improve their contributions. Extensive experiments demonstrate that OSS Mentor significantly outperforms excellent experimental results. Moreover, it is the first time that the presented framework explores deep reinforcement learning techniques to manage open source software, which enables us to design a more robust framework to improve developers' contributions.
Quant-BnB: A Scalable Branch-and-Bound Method for Optimal Decision Trees with Continuous Features
Jun 29, 2022



Decision trees are one of the most useful and popular methods in the machine learning toolbox. In this paper, we consider the problem of learning optimal decision trees, a combinatorial optimization problem that is challenging to solve at scale. A common approach in the literature is to use greedy heuristics, which may not be optimal. Recently there has been significant interest in learning optimal decision trees using various approaches (e.g., based on integer programming, dynamic programming) -- to achieve computational scalability, most of these approaches focus on classification tasks with binary features. In this paper, we present a new discrete optimization method based on branch-and-bound (BnB) to obtain optimal decision trees. Different from existing customized approaches, we consider both regression and classification tasks with continuous features. The basic idea underlying our approach is to split the search space based on the quantiles of the feature distribution -- leading to upper and lower bounds for the underlying optimization problem along the BnB iterations. Our proposed algorithm Quant-BnB shows significant speedups compared to existing approaches for shallow optimal trees on various real datasets.
Linear regression with partially mismatched data: local search with theoretical guarantees
Jun 03, 2021

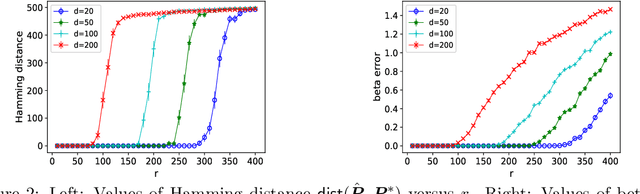

Linear regression is a fundamental modeling tool in statistics and related fields. In this paper, we study an important variant of linear regression in which the predictor-response pairs are partially mismatched. We use an optimization formulation to simultaneously learn the underlying regression coefficients and the permutation corresponding to the mismatches. The combinatorial structure of the problem leads to computational challenges. We propose and study a simple greedy local search algorithm for this optimization problem that enjoys strong theoretical guarantees and appealing computational performance. We prove that under a suitable scaling of the number of mismatched pairs compared to the number of samples and features, and certain assumptions on problem data; our local search algorithm converges to a nearly-optimal solution at a linear rate. In particular, in the noiseless case, our algorithm converges to the global optimal solution with a linear convergence rate. We also propose an approximate local search step that allows us to scale our approach to much larger instances. We conduct numerical experiments to gather further insights into our theoretical results and show promising performance gains compared to existing approaches.
Interior-point Methods Strike Back: Solving the Wasserstein Barycenter Problem
May 30, 2019
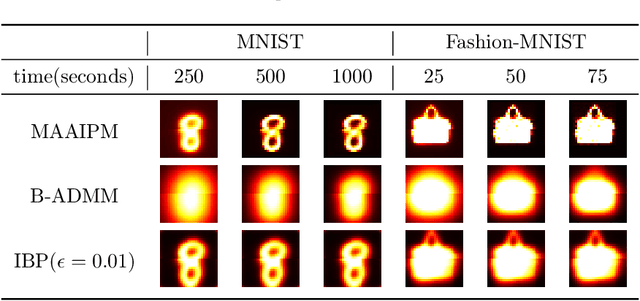
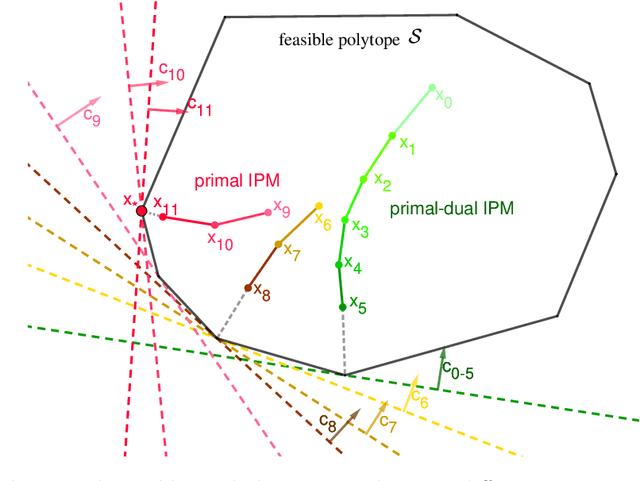
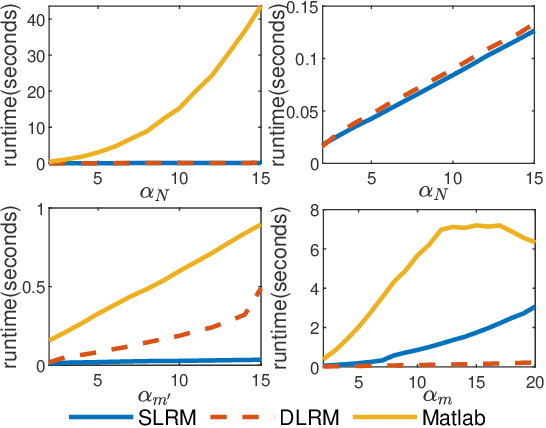
Computing the Wasserstein barycenter of a set of probability measures under the optimal transport metric can quickly become prohibitive for traditional second-order algorithms, such as interior-point methods, as the support size of the measures increases. In this paper, we overcome the difficulty by developing a new adapted interior-point method that fully exploits the problem's special matrix structure to reduce the iteration complexity and speed up the Newton procedure. Different from regularization approaches, our method achieves a well-balanced tradeoff between accuracy and speed. A numerical comparison on various distributions with existing algorithms exhibits the computational advantages of our approach. Moreover, we demonstrate the practicality of our algorithm on image benchmark problems including MNIST and Fashion-MNIST.