 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPEC: Test-Time Incremental Prototype Enhancement Classifier for Few-Shot Learning
Jan 16, 2026Metric-based few-shot approaches have gained significant popularity due to their relatively straightforward implementation, high interpret ability, and computational efficiency. However, stemming from the batch-independence assumption during testing, which prevents the model from leveraging valuable knowledge accumulated from previous batches. To address these challenges, we propose a novel test-time method called Incremental Prototype Enhancement Classifier (IPEC), a test-time method that optimizes prototype estimation by leveraging information from previous query samples. IPEC maintains a dynamic auxiliary set by selectively incorporating query samples that are classified with high confidence. To ensure sample quality, we design a robust dual-filtering mechanism that assesses each query sample based on both global prediction confidence and local discriminative ability. By aggregating this auxiliary set with the support set in subsequent tasks, IPEC builds progressively more stable and representative prototypes, effectively reducing its reliance on the initial support set. We ground this approach in a Bayesian interpretation, conceptualizing the support set as a prior and the auxiliary set as a data-driven posterior, which in turn motivates the design of a practical "warm-up and test" two-stage inference protocol. Extensive empirical results validate the superior performance of our proposed method across multiple few-shot classification tasks.
Enhancing Visual In-Context Learning by Multi-Faceted Fusion
Jan 15, 2026Visual In-Context Learning (VICL) has emerged as a powerful paradigm, enabling models to perform novel visual tasks by learning from in-context examples. The dominant "retrieve-then-prompt" approach typically relies on selecting the single best visual prompt, a practice that often discards valuable contextual information from other suitable candidates. While recent work has explored fusing the top-K prompts into a single, enhanced representation, this still simply collapses multiple rich signals into one, limiting the model's reasoning capability. We argue that a more multi-faceted, collaborative fusion is required to unlock the full potential of these diverse contexts. To address this limitation, we introduce a novel framework that moves beyond single-prompt fusion towards an multi-combination collaborative fusion. Instead of collapsing multiple prompts into one, our method generates three contextual representation branches, each formed by integrating information from different combinations of top-quality prompts. These complementary guidance signals are then fed into proposed MULTI-VQGAN architecture, which is designed to jointly interpret and utilize collaborative information from multiple sources. Extensive experiments on diverse tasks, including foreground segmentation, single-object detection, and image colorization, highlight its strong cross-task generalization, effective contextual fusion, and ability to produce more robust and accurate predictions than existing methods.
InfoSculpt: Sculpting the Latent Space for Generalized Category Discovery
Jan 15, 2026Generalized Category Discovery (GCD) aims to classify instances from both known and novel categories within a large-scale unlabeled dataset, a critical yet challenging task for real-world, open-world applications. However, existing methods often rely on pseudo-labeling, or two-stage clustering, which lack a principled mechanism to explicitly disentangle essential, category-defining signals from instance-specific noise. In this paper, we address this fundamental limitation by re-framing GCD from an information-theoretic perspective, grounded in the Information Bottleneck (IB) principle. We introduce InfoSculpt, a novel framework that systematically sculpts the representation space by minimizing a dual Conditional Mutual Information (CMI) objective. InfoSculpt uniquely combines a Category-Level CMI on labeled data to learn compact and discriminative representations for known classes, and a complementary Instance-Level CMI on all data to distill invariant features by compressing augmentation-induced noise. These two objectives work synergistically at different scales to produce a disentangled and robust latent space where categorical information is preserved while noisy, instance-specific details are discarded. Extensive experiments on 8 benchmarks demonstrate that InfoSculpt validating the effectiveness of our information-theoretic approach.
Model Discrepancy Learning: Synthetic Faces Detection Based on Multi-Reconstruction
Apr 10, 2025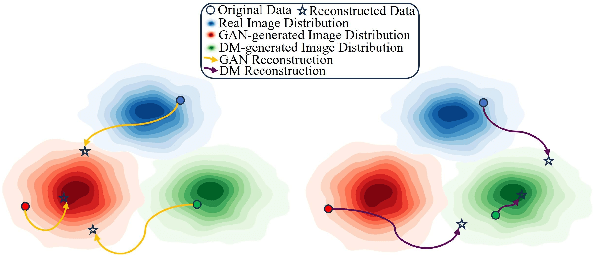

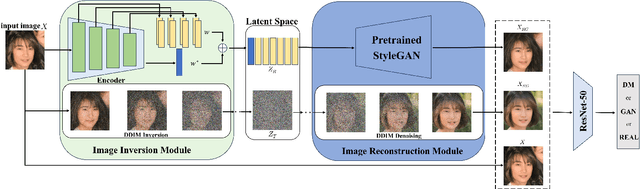

Advances in image generation enable hyper-realistic synthetic faces but also pose risks, thus making synthetic face detection crucial. Previous research focuses on the general differences between generated images and real images, often overlooking the discrepancies among various generative techniques. In this paper, we explore the intrinsic relationship between synthetic images and their corresponding generation technologies. We find that specific images exhibit significant reconstruction discrepancies across different generative methods and that matching generation techniques provide more accurate reconstructions. Based on this insight, we propose a Multi-Reconstruction-based detector. By reversing and reconstructing images using multiple generative models, we analyze the reconstruction differences among real, GAN-generated, and DM-generated images to facilitate effective differentiation. Additionally, we introduce the Asian Synthetic Face Dataset (ASFD), containing synthetic Asian faces generated with various GANs and DMs. This dataset complements existing synthetic face datasets. Experimental results demonstrate that our detector achieves exceptional performance, with strong generalization and robustness.