 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPEC: Test-Time Incremental Prototype Enhancement Classifier for Few-Shot Learning
Jan 16, 2026Metric-based few-shot approaches have gained significant popularity due to their relatively straightforward implementation, high interpret ability, and computational efficiency. However, stemming from the batch-independence assumption during testing, which prevents the model from leveraging valuable knowledge accumulated from previous batches. To address these challenges, we propose a novel test-time method called Incremental Prototype Enhancement Classifier (IPEC), a test-time method that optimizes prototype estimation by leveraging information from previous query samples. IPEC maintains a dynamic auxiliary set by selectively incorporating query samples that are classified with high confidence. To ensure sample quality, we design a robust dual-filtering mechanism that assesses each query sample based on both global prediction confidence and local discriminative ability. By aggregating this auxiliary set with the support set in subsequent tasks, IPEC builds progressively more stable and representative prototypes, effectively reducing its reliance on the initial support set. We ground this approach in a Bayesian interpretation, conceptualizing the support set as a prior and the auxiliary set as a data-driven posterior, which in turn motivates the design of a practical "warm-up and test" two-stage inference protocol. Extensive empirical results validate the superior performance of our proposed method across multiple few-shot classification tasks.
DA2Diff: Exploring Degradation-aware Adaptive Diffusion Priors for All-in-One Weather Restoration
Apr 07, 2025



Image restoration under adverse weather conditions is a critical task for many vision-based applications. Recent all-in-one frameworks that handle multiple weather degradations within a unified model have shown potential. However, the diversity of degradation patterns across different weather conditions, as well as the complex and varied nature of real-world degradations, pose significant challenges for multiple weather removal. To address these challenges, we propose an innovative diffusion paradigm with degradation-aware adaptive priors for all-in-one weather restoration, termed DA2Diff. It is a new exploration that applies CLIP to perceive degradation-aware properties for better multi-weather restoration. Specifically, we deploy a set of learnable prompts to capture degradation-aware representations by the prompt-image similarity constraints in the CLIP space. By aligning the snowy/hazy/rainy images with snow/haze/rain prompts, each prompt contributes to different weather degradation characteristics. The learned prompts are then integrated into the diffusion model via the designed weather specific prompt guidance module, making it possible to restore multiple weather types. To further improve the adaptiveness to complex weather degradations, we propose a dynamic expert selection modulator that employs a dynamic weather-aware router to flexibly dispatch varying numbers of restoration experts for each weather-distorted image, allowing the diffusion model to restore diverse degradations adaptively. Experimental results substantiate the favorable performance of DA2Diff over state-of-the-arts in quantitative and qualitative evaluation. Source code will be available after acceptance.
CrossTracker: Robust Multi-modal 3D Multi-Object Tracking via Cross Correction
Nov 28, 2024



The fusion of camera- and LiDAR-based detections offers a promising solution to mitigate tracking failures in 3D multi-object tracking (MOT). However, existing methods predominantly exploit camera detections to correct tracking failures caused by potential LiDAR detection problems, neglecting the reciprocal benefit of refining camera detections using LiDAR data. This limitation is rooted in their single-stage architecture, akin to single-stage object detectors, lacking a dedicated trajectory refinement module to fully exploit the complementary multi-modal information. To this end, we introduce CrossTracker, a novel two-stage paradigm for online multi-modal 3D MOT. CrossTracker operates in a coarse-to-fine manner, initially generating coarse trajectories and subsequently refining them through an independent refinement process. Specifically, CrossTracker incorporates three essential modules: i) a multi-modal modeling (M^3) module that, by fusing multi-modal information (images, point clouds, and even plane geometry extracted from images), provides a robust metric for subsequent trajectory generation. ii) a coarse trajectory generation (C-TG) module that generates initial coarse dual-stream trajectories, and iii) a trajectory refinement (TR) module that refines coarse trajectories through cross correction between camera and LiDAR streams. Comprehensive experiments demonstrate the superior performance of our CrossTracker over its eighteen competitors, underscoring its effectiveness in harnessing the synergistic benefits of camera and LiDAR sensors for robust multi-modal 3D MOT.
PointCG: Self-supervised Point Cloud Learning via Joint Completion and Generation
Nov 09, 2024


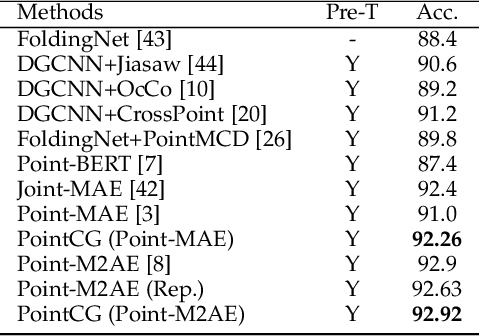
The core of self-supervised point cloud learning lies in setting up appropriate pretext tasks, to construct a pre-training framework that enables the encoder to perceive 3D objects effectively. In this paper, we integrate two prevalent methods, masked point modeling (MPM) and 3D-to-2D generation, as pretext tasks within a pre-training framework. We leverage the spatial awareness and precise supervision offered by these two methods to address their respective limitations: ambiguous supervision signals and insensitivity to geometric information. Specifically, the proposed framework, abbreviated as PointCG, consists of a Hidden Point Completion (HPC) module and an Arbitrary-view Image Generation (AIG) module. We first capture visible points from arbitrary views as inputs by removing hidden points. Then, HPC extracts representations of the inputs with an encoder and completes the entire shape with a decoder, while AIG is used to generate rendered images based on the visible points' representations. Extensive experiments demonstrate the superiority of the proposed method over the baselines in various downstream tasks. Our code will be made available upon acceptance.
YOLOO: You Only Learn from Others Once
Sep 01, 2024



Multi-modal 3D multi-object tracking (MOT) typically necessitates extensive computational costs of deep neural networks (DNNs) to extract multi-modal representations. In this paper, we propose an intriguing question: May we learn from multiple modalities only during training to avoid multi-modal input in the inference phase? To answer it, we propose \textbf{YOLOO}, a novel multi-modal 3D MOT paradigm: You Only Learn from Others Once. YOLOO empowers the point cloud encoder to learn a unified tri-modal representation (UTR) from point clouds and other modalities, such as images and textual cues, all at once. Leveraging this UTR, YOLOO achieves efficient tracking solely using the point cloud encoder without compromising its performance, fundamentally obviating the need for computationally intensive DNNs. Specifically, YOLOO includes two core components: a unified tri-modal encoder (UTEnc) and a flexible geometric constraint (F-GC) module. UTEnc integrates a point cloud encoder with image and text encoders adapted from pre-trained CLIP. It seamlessly fuses point cloud information with rich visual-textual knowledge from CLIP into the point cloud encoder, yielding highly discriminative UTRs that facilitate the association between trajectories and detections. Additionally, F-GC filters out mismatched associations with similar representations but significant positional discrepancies. It further enhances the robustness of UTRs without requiring any scene-specific tuning, addressing a key limitation of customized geometric constraints (e.g., 3D IoU). Lastly, high-quality 3D trajectories are generated by a traditional data association component. By integrating these advancements into a multi-modal 3D MOT scheme, our YOLOO achieves substantial gains in both robustness and efficiency.
RSHazeDiff: A Unified Fourier-aware Diffusion Model for Remote Sensing Image Dehazing
May 15, 2024



Haze severely degrades the visual quality of remote sensing images and hampers the performance of automotive navigation, intelligent monitoring, and urban management. The emerging denoising diffusion probabilistic model (DDPM) exhibits the significant potential for dense haze removal with its strong generation ability. Since remote sensing images contain extensive small-scale texture structures, it is important to effectively restore image details from hazy images. However, current wisdom of DDPM fails to preserve image details and color fidelity well, limiting its dehazing capacity for remote sensing images. In this paper, we propose a novel unified Fourier-aware diffusion model for remote sensing image dehazing, termed RSHazeDiff. From a new perspective, RSHazeDiff explores the conditional DDPM to improve image quality in dense hazy scenarios, and it makes three key contributions. First, RSHazeDiff refines the training phase of diffusion process by performing noise estimation and reconstruction constraints in a coarse-to-fine fashion. Thus, it remedies the unpleasing results caused by the simple noise estimation constraint in DDPM. Second, by taking the frequency information as important prior knowledge during iterative sampling steps, RSHazeDiff can preserve more texture details and color fidelity in dehazed images. Third, we design a global compensated learning module to utilize the Fourier transform to capture the global dependency features of input images, which can effectively mitigate the effects of boundary artifacts when processing fixed-size patches. Experiments on both synthetic and real-world benchmarks validate the favorable performance of RSHazeDiff over multiple state-of-the-art methods. Source code will be released at https://github.com/jm-xiong/RSHazeDiff.
PointeNet: A Lightweight Framework for Effective and Efficient Point Cloud Analysis
Dec 20, 2023



Current methodologies in point cloud analysis predominantly explore 3D geometries, often achieved through the introduction of intricate learnable geometric extractors in the encoder or by deepening networks with repeated blocks. However, these approaches inevitably lead to a significant number of learnable parameters, resulting in substantial computational costs and imposing memory burdens on CPU/GPU. Additionally, the existing strategies are primarily tailored for object-level point cloud classification and segmentation tasks, with limited extensions to crucial scene-level applications, such as autonomous driving. In response to these limitations, we introduce PointeNet, an efficient network designed specifically for point cloud analysis. PointeNet distinguishes itself with its lightweight architecture, low training cost, and plug-and-play capability, effectively capturing representative features. The network consists of a Multivariate Geometric Encoding (MGE) module and an optional Distance-aware Semantic Enhancement (DSE) module. The MGE module employs operations of sampling, grouping, and multivariate geometric aggregation to lightweightly capture and adaptively aggregate multivariate geometric features, providing a comprehensive depiction of 3D geometries. The DSE module, designed for real-world autonomous driving scenarios, enhances the semantic perception of point clouds, particularly for distant points. Our method demonstrates flexibility by seamlessly integrating with a classification/segmentation head or embedding into off-the-shelf 3D object detection networks, achieving notable performance improvements at a minimal cost. Extensive experiments on object-level datasets, including ModelNet40, ScanObjectNN, ShapeNetPart, and the scene-level dataset KITTI, demonstrate the superior performance of PointeNet over state-of-the-art methods in point cloud analysis.
Uncertainty-Driven Multi-Scale Feature Fusion Network for Real-time Image Deraining
Jul 19, 2023
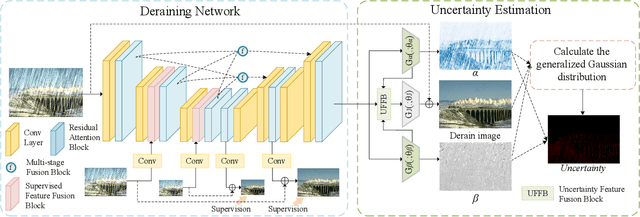
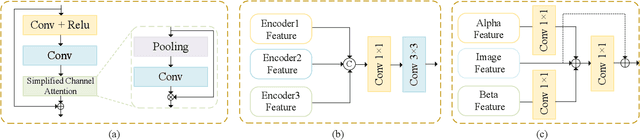
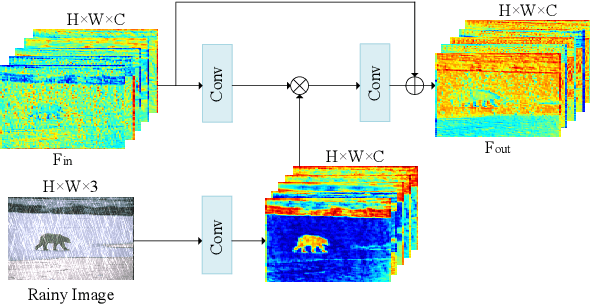
Visual-based measurement systems are frequently affected by rainy weather due to the degradation caused by rain streaks in captured images, and existing imaging devices struggle to address this issue in real-time. While most efforts leverage deep networks for image deraining and have made progress, their large parameter sizes hinder deployment on resource-constrained devices. Additionally, these data-driven models often produce deterministic results, without considering their inherent epistemic uncertainty, which can lead to undesired reconstruction errors. Well-calibrated uncertainty can help alleviate prediction errors and assist measurement devices in mitigating risks and improving usability. Therefore, we propose an Uncertainty-Driven Multi-Scale Feature Fusion Network (UMFFNet) that learns the probability mapping distribution between paired images to estimate uncertainty. Specifically, we introduce an uncertainty feature fusion block (UFFB) that utilizes uncertainty information to dynamically enhance acquired features and focus on blurry regions obscured by rain streaks, reducing prediction errors. In addition, to further boost the performance of UMFFNet, we fused feature information from multiple scales to guide the network for efficient collaborative rain removal. Extensive experiments demonstrate that UMFFNet achieves significant performance improvements with few parameters, surpassing state-of-the-art image deraining methods.
Joint Depth Estimation and Mixture of Rain Removal From a Single Image
Mar 31, 2023



Rainy weather significantly deteriorates the visibility of scene objects, particularly when images are captured through outdoor camera lenses or windshields. Through careful observation of numerous rainy photos, we have found that the images are generally affected by various rainwater artifacts such as raindrops, rain streaks, and rainy haze, which impact the image quality from both near and far distances, resulting in a complex and intertwined process of image degradation. However, current deraining techniques are limited in their ability to address only one or two types of rainwater, which poses a challenge in removing the mixture of rain (MOR). In this study, we propose an effective image deraining paradigm for Mixture of rain REmoval, called DEMore-Net, which takes full account of the MOR effect. Going beyond the existing deraining wisdom, DEMore-Net is a joint learning paradigm that integrates depth estimation and MOR removal tasks to achieve superior rain removal. The depth information can offer additional meaningful guidance information based on distance, thus better helping DEMore-Net remove different types of rainwater. Moreover, this study explores normalization approaches in image deraining tasks and introduces a new Hybrid Normalization Block (HNB) to enhance the deraining performance of DEMore-Net. Extensive experiments conducted on synthetic datasets and real-world MOR photos fully validate the superiority of the proposed DEMore-Net. Code is available at https://github.com/yz-wang/DEMore-Net.
PointGame: Geometrically and Adaptively Masked Auto-Encoder on Point Clouds
Mar 23, 2023



Self-supervised learning is attracting large attention in point cloud understanding. However, exploring discriminative and transferable features still remains challenging due to their nature of irregularity and sparsity. We propose a geometrically and adaptively masked auto-encoder for self-supervised learning on point clouds, termed \textit{PointGame}. PointGame contains two core components: GATE and EAT. GATE stands for the geometrical and adaptive token embedding module; it not only absorbs the conventional wisdom of geometric descriptors that captures the surface shape effectively, but also exploits adaptive saliency to focus on the salient part of a point cloud. EAT stands for the external attention-based Transformer encoder with linear computational complexity, which increases the efficiency of the whole pipeline. Unlike cutting-edge unsupervised learning models, PointGame leverages geometric descriptors to perceive surface shapes and adaptively mines discriminative features from training data. PointGame showcases clear advantages over its competitors on various downstream tasks under both global and local fine-tuning strategies. The code and pre-trained models will be publicly available.