 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointCG: Self-supervised Point Cloud Learning via Joint Completion and Generation
Paper and Code
Nov 09, 2024


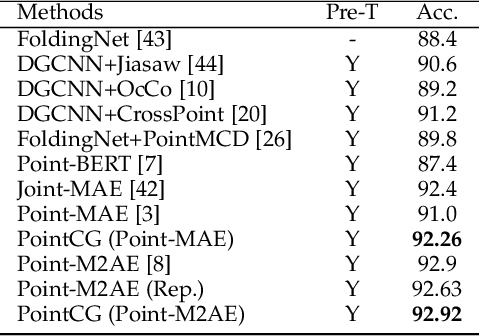
The core of self-supervised point cloud learning lies in setting up appropriate pretext tasks, to construct a pre-training framework that enables the encoder to perceive 3D objects effectively. In this paper, we integrate two prevalent methods, masked point modeling (MPM) and 3D-to-2D generation, as pretext tasks within a pre-training framework. We leverage the spatial awareness and precise supervision offered by these two methods to address their respective limitations: ambiguous supervision signals and insensitivity to geometric information. Specifically, the proposed framework, abbreviated as PointCG, consists of a Hidden Point Completion (HPC) module and an Arbitrary-view Image Generation (AIG) module. We first capture visible points from arbitrary views as inputs by removing hidden points. Then, HPC extracts representations of the inputs with an encoder and completes the entire shape with a decoder, while AIG is used to generate rendered images based on the visible points' representations. Extensive experiments demonstrate the superiority of the proposed method over the baselines in various downstream tasks. Our code will be made available upon acceptance.