 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePocketGS: On-Device Training of 3D Gaussian Splatting for High Perceptual Modeling
Jan 24, 2026Efficient and high-fidelity 3D scene modeling is a long-standing pursuit in computer graphics. While recent 3D Gaussian Splatting (3DGS) methods achieve impressive real-time modeling performance, they rely on resource-unconstrained training assumptions that fail on mobile devices, which are limited by minute-scale training budgets and hardware-available peak-memory. We present PocketGS, a mobile scene modeling paradigm that enables on-device 3DGS training under these tightly coupled constraints while preserving high perceptual fidelity. Our method resolves the fundamental contradictions of standard 3DGS through three co-designed operators: G builds geometry-faithful point-cloud priors; I injects local surface statistics to seed anisotropic Gaussians, thereby reducing early conditioning gaps; and T unrolls alpha compositing with cached intermediates and index-mapped gradient scattering for stable mobile backpropagation. Collectively, these operators satisfy the competing requirements of training efficiency, memory compactness, and modeling fidelity. Extensive experiments demonstrate that PocketGS is able to outperform the powerful mainstream workstation 3DGS baseline to deliver high-quality reconstructions, enabling a fully on-device, practical capture-to-rendering workflow.
VILTA: A VLM-in-the-Loop Adversary for Enhancing Driving Policy Robustness
Jan 19, 2026The safe deployment of autonomous driving (AD) systems is fundamentally hindered by the long-tail problem, where rare yet critical driving scenarios are severely underrepresented in real-world data. Existing solutions including safety-critical scenario generation and closed-loop learning often rely on rule-based heuristics, resampling methods and generative models learned from offline datasets, limiting their ability to produce diverse and novel challenges. While recent works leverage Vision Language Models (VLMs) to produce scene descriptions that guide a separate, downstream model in generating hazardous trajectories for agents, such two-stage framework constrains the generative potential of VLMs, as the diversity of the final trajectories is ultimately limited by the generalization ceiling of the downstream algorithm. To overcome these limitations, we introduce VILTA (VLM-In-the-Loop Trajectory Adversary), a novel framework that integrates a VLM into the closed-loop training of AD agents. Unlike prior works, VILTA actively participates in the training loop by comprehending the dynamic driving environment and strategically generating challenging scenarios through direct, fine-grained editing of surrounding agents' future trajectories. This direct-editing approach fully leverages the VLM's powerful generalization capabilities to create a diverse curriculum of plausible yet challenging scenarios that extend beyond the scope of traditional methods. We demonstrate that our approach substantially enhances the safety and robustness of the resulting AD policy, particularly in its ability to navigate critical long-tail events.
Distribution-Aligned Sequence Distillation for Superior Long-CoT Reasoning
Jan 14, 2026In this report, we introduce DASD-4B-Thinking, a lightweight yet highly capable, fully open-source reasoning model. It achieves SOTA performance among open-source models of comparable scale across challenging benchmarks in mathematics, scientific reasoning, and code generation -- even outperforming several larger models. We begin by critically reexamining a widely adopted distillation paradigm in the community: SFT on teacher-generated responses, also known as sequence-level distillation. Although a series of recent works following this scheme have demonstrated remarkable efficiency and strong empirical performance, they are primarily grounded in the SFT perspective. Consequently, these approaches focus predominantly on designing heuristic rules for SFT data filtering, while largely overlooking the core principle of distillation itself -- enabling the student model to learn the teacher's full output distribution so as to inherit its generalization capability. Specifically, we identify three critical limitations in current practice: i) Inadequate representation of the teacher's sequence-level distribution; ii) Misalignment between the teacher's output distribution and the student's learning capacity; and iii) Exposure bias arising from teacher-forced training versus autoregressive inference. In summary, these shortcomings reflect a systemic absence of explicit teacher-student interaction throughout the distillation process, leaving the essence of distillation underexploited. To address these issues, we propose several methodological innovations that collectively form an enhanced sequence-level distillation training pipeline. Remarkably, DASD-4B-Thinking obtains competitive results using only 448K training samples -- an order of magnitude fewer than those employed by most existing open-source efforts. To support community research, we publicly release our models and the training dataset.
ParkGaussian: Surround-view 3D Gaussian Splatting for Autonomous Parking
Jan 04, 2026Parking is a critical task for autonomous driving systems (ADS), with unique challenges in crowded parking slots and GPS-denied environments. However, existing works focus on 2D parking slot perception, mapping, and localization, 3D reconstruction remains underexplored, which is crucial for capturing complex spatial geometry in parking scenarios. Naively improving the visual quality of reconstructed parking scenes does not directly benefit autonomous parking, as the key entry point for parking is the slots perception module. To address these limitations, we curate the first benchmark named ParkRecon3D, specifically designed for parking scene reconstruction. It includes sensor data from four surround-view fisheye cameras with calibrated extrinsics and dense parking slot annotations. We then propose ParkGaussian, the first framework that integrates 3D Gaussian Splatting (3DGS) for parking scene reconstruction. To further improve the alignment between reconstruction and downstream parking slot detection, we introduce a slot-aware reconstruction strategy that leverages existing parking perception methods to enhance the synthesis quality of slot regions. Experiments on ParkRecon3D demonstrate that ParkGaussian achieves state-of-the-art reconstruction quality and better preserves perception consistency for downstream tasks. The code and dataset will be released at: https://github.com/wm-research/ParkGaussian
DriveLaW:Unifying Planning and Video Generation in a Latent Driving World
Dec 31, 2025World models have become crucial for autonomous driving, as they learn how scenarios evolve over time to address the long-tail challenges of the real world. However, current approaches relegate world models to limited roles: they operate within ostensibly unified architectures that still keep world prediction and motion planning as decoupled processes. To bridge this gap, we propose DriveLaW, a novel paradigm that unifies video generation and motion planning. By directly injecting the latent representation from its video generator into the planner, DriveLaW ensures inherent consistency between high-fidelity future generation and reliable trajectory planning. Specifically, DriveLaW consists of two core components: DriveLaW-Video, our powerful world model that generates high-fidelity forecasting with expressive latent representations, and DriveLaW-Act, a diffusion planner that generates consistent and reliable trajectories from the latent of DriveLaW-Video, with both components optimized by a three-stage progressive training strategy. The power of our unified paradigm is demonstrated by new state-of-the-art results across both tasks. DriveLaW not only advances video prediction significantly, surpassing best-performing work by 33.3% in FID and 1.8% in FVD, but also achieves a new record on the NAVSIM planning benchmark.
Mirage: One-Step Video Diffusion for Photorealistic and Coherent Asset Editing in Driving Scenes
Dec 30, 2025Vision-centric autonomous driving systems rely on diverse and scalable training data to achieve robust performance. While video object editing offers a promising path for data augmentation, existing methods often struggle to maintain both high visual fidelity and temporal coherence. In this work, we propose \textbf{Mirage}, a one-step video diffusion model for photorealistic and coherent asset editing in driving scenes. Mirage builds upon a text-to-video diffusion prior to ensure temporal consistency across frames. However, 3D causal variational autoencoders often suffer from degraded spatial fidelity due to compression, and directly passing 3D encoder features to decoder layers breaks temporal causality. To address this, we inject temporally agnostic latents from a pretrained 2D encoder into the 3D decoder to restore detail while preserving causal structures. Furthermore, because scene objects and inserted assets are optimized under different objectives, their Gaussians exhibit a distribution mismatch that leads to pose misalignment. To mitigate this, we introduce a two-stage data alignment strategy combining coarse 3D alignment and fine 2D refinement, thereby improving alignment and providing cleaner supervision. Extensive experiments demonstrate that Mirage achieves high realism and temporal consistency across diverse editing scenarios. Beyond asset editing, Mirage can also generalize to other video-to-video translation tasks, serving as a reliable baseline for future research. Our code is available at https://github.com/wm-research/mirage.
Where Did This Sentence Come From? Tracing Provenance in LLM Reasoning Distillation
Dec 24, 2025Reasoning distillation has attracted increasing attention. It typically leverages a large teacher model to generate reasoning paths, which are then used to fine-tune a student model so that it mimics the teacher's behavior in training contexts. However, previous approaches have lacked a detailed analysis of the origins of the distilled model's capabilities. It remains unclear whether the student can maintain consistent behaviors with the teacher in novel test-time contexts, or whether it regresses to its original output patterns, raising concerns about the generalization of distillation models. To analyse this question, we introduce a cross-model Reasoning Distillation Provenance Tracing framework. For each action (e.g., a sentence) produced by the distilled model, we obtain the predictive probabilities assigned by the teacher, the original student, and the distilled model under the same context. By comparing these probabilities, we classify each action into different categories. By systematically disentangling the provenance of each action, we experimentally demonstrate that, in test-time contexts, the distilled model can indeed generate teacher-originated actions, which correlate with and plausibly explain observed performance on distilled model. Building on this analysis, we further propose a teacher-guided data selection method. Unlike prior approach that rely on heuristics, our method directly compares teacher-student divergences on the training data, providing a principled selection criterion. We validate the effectiveness of our approach across multiple representative teacher models and diverse student models. The results highlight the utility of our provenance-tracing framework and underscore its promise for reasoning distillation. We hope to share Reasoning Distillation Provenance Tracing and our insights into reasoning distillation with the community.
MindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning
Dec 16, 2025


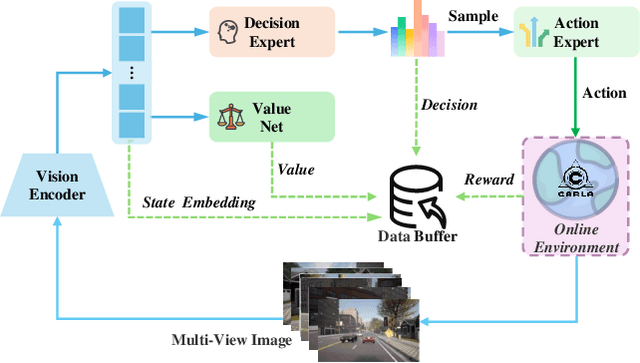
Current Vision-Language-Action (VLA) paradigms in autonomous driving primarily rely on Imitation Learning (IL), which introduces inherent challenges such as distribution shift and causal confusion. Online Reinforcement Learning offers a promising pathway to address these issues through trial-and-error learning. However, applying online reinforcement learning to VLA models in autonomous driving is hindered by inefficient exploration in continuous action spaces. To overcome this limitation, we propose MindDrive, a VLA framework comprising a large language model (LLM) with two distinct sets of LoRA parameters. The one LLM serves as a Decision Expert for scenario reasoning and driving decision-making, while the other acts as an Action Expert that dynamically maps linguistic decisions into feasible trajectories. By feeding trajectory-level rewards back into the reasoning space, MindDrive enables trial-and-error learning over a finite set of discrete linguistic driving decisions, instead of operating directly in a continuous action space. This approach effectively balances optimal decision-making in complex scenarios, human-like driving behavior, and efficient exploration in online reinforcement learning. Using the lightweight Qwen-0.5B LLM, MindDrive achieves Driving Score (DS) of 78.04 and Success Rate (SR) of 55.09% on the challenging Bench2Drive benchmark. To the best of our knowledge, this is the first work to demonstrate the effectiveness of online reinforcement learning for the VLA model in autonomous driving.
Enhancing Multimodal Misinformation Detection by Replaying the Whole Story from Image Modality Perspective
Nov 09, 2025
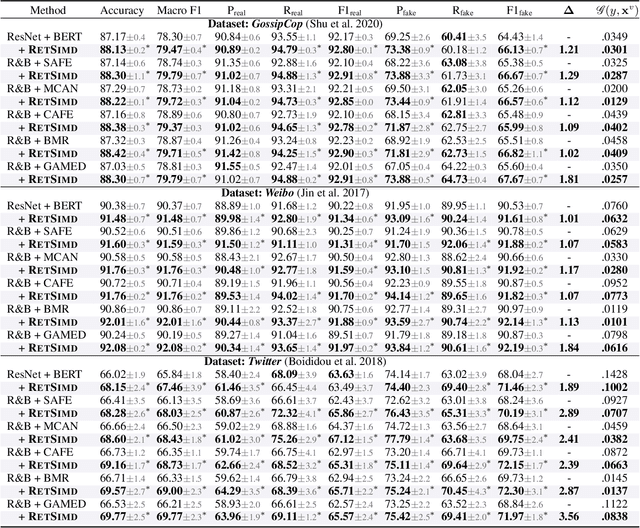
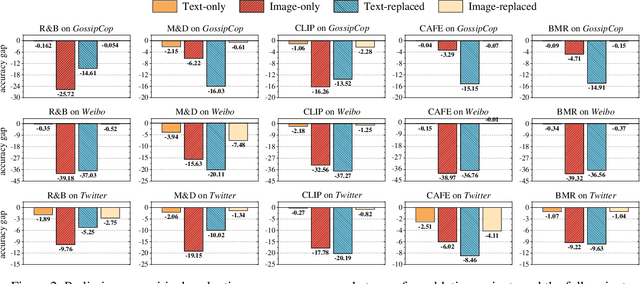
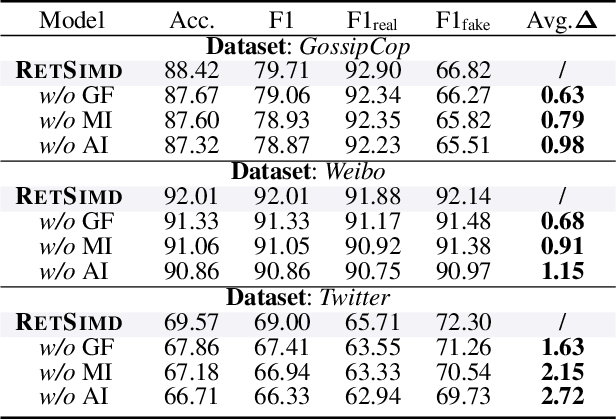
Multimodal Misinformation Detection (MMD) refers to the task of detecting social media posts involving misinformation, where the post often contains text and image modalities. However, by observing the MMD posts, we hold that the text modality may be much more informative than the image modality because the text generally describes the whole event/story of the current post but the image often presents partial scenes only. Our preliminary empirical results indicate that the image modality exactly contributes less to MMD. Upon this idea, we propose a new MMD method named RETSIMD. Specifically, we suppose that each text can be divided into several segments, and each text segment describes a partial scene that can be presented by an image. Accordingly, we split the text into a sequence of segments, and feed these segments into a pre-trained text-to-image generator to augment a sequence of images. We further incorporate two auxiliary objectives concerning text-image and image-label mutual information, and further post-train the generator over an auxiliary text-to-image generation benchmark dataset. Additionally, we propose a graph structure by defining three heuristic relationships between images, and use a graph neural network to generate the fused features. Extensive empirical results validate the effectiveness of RETSIMD.
LiveStar: Live Streaming Assistant for Real-World Online Video Understanding
Nov 07, 2025Despite significant progress in Video Large Language Models (Video-LLMs) for offline video understanding, existing online Video-LLMs typically struggle to simultaneously process continuous frame-by-frame inputs and determine optimal response timing, often compromising real-time responsiveness and narrative coherence. To address these limitations, we introduce LiveStar, a pioneering live streaming assistant that achieves always-on proactive responses through adaptive streaming decoding. Specifically, LiveStar incorporates: (1) a training strategy enabling incremental video-language alignment for variable-length video streams, preserving temporal consistency across dynamically evolving frame sequences; (2) a response-silence decoding framework that determines optimal proactive response timing via a single forward pass verification; (3) memory-aware acceleration via peak-end memory compression for online inference on 10+ minute videos, combined with streaming key-value cache to achieve 1.53x faster inference. We also construct an OmniStar dataset, a comprehensive dataset for training and benchmarking that encompasses 15 diverse real-world scenarios and 5 evaluation tasks for online video understanding. Extensive experiments across three benchmarks demonstrate LiveStar's state-of-the-art performance, achieving an average 19.5% improvement in semantic correctness with 18.1% reduced timing difference compared to existing online Video-LLMs, while improving FPS by 12.0% across all five OmniStar tasks. Our model and dataset can be accessed at https://github.com/yzy-bupt/LiveStar.