 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticNVS: Improving Semantic Scene Understanding in Generative Novel View Synthesis
Feb 23, 2026We present SemanticNVS, a camera-conditioned multi-view diffusion model for novel view synthesis (NVS), which improves generation quality and consistency by integrating pre-trained semantic feature extractors. Existing NVS methods perform well for views near the input view, however, they tend to generate semantically implausible and distorted images under long-range camera motion, revealing severe degradation. We speculate that this degradation is due to current models failing to fully understand their conditioning or intermediate generated scene content. Here, we propose to integrate pre-trained semantic feature extractors to incorporate stronger scene semantics as conditioning to achieve high-quality generation even at distant viewpoints. We investigate two different strategies, (1) warped semantic features and (2) an alternating scheme of understanding and generation at each denoising step. Experimental results on multiple datasets demonstrate the clear qualitative and quantitative (4.69%-15.26% in FID) improvement over state-of-the-art alternatives.
ScenDi: 3D-to-2D Scene Diffusion Cascades for Urban Generation
Jan 21, 2026Recent advancements in 3D object generation using diffusion models have achieved remarkable success, but generating realistic 3D urban scenes remains challenging. Existing methods relying solely on 3D diffusion models tend to suffer a degradation in appearance details, while those utilizing only 2D diffusion models typically compromise camera controllability. To overcome this limitation, we propose ScenDi, a method for urban scene generation that integrates both 3D and 2D diffusion models. We first train a 3D latent diffusion model to generate 3D Gaussians, enabling the rendering of images at a relatively low resolution. To enable controllable synthesis, this 3DGS generation process can be optionally conditioned by specifying inputs such as 3d bounding boxes, road maps, or text prompts. Then, we train a 2D video diffusion model to enhance appearance details conditioned on rendered images from the 3D Gaussians. By leveraging the coarse 3D scene as guidance for 2D video diffusion, ScenDi generates desired scenes based on input conditions and successfully adheres to accurate camera trajectories. Experiments on two challenging real-world datasets, Waymo and KITTI-360, demonstrate the effectiveness of our approach.
NormalCrafter: Learning Temporally Consistent Normals from Video Diffusion Priors
Apr 15, 2025



Surface normal estimation serves as a cornerstone for a spectrum of computer vision applications. While numerous efforts have been devoted to static image scenarios, ensuring temporal coherence in video-based normal estimation remains a formidable challenge. Instead of merely augmenting existing methods with temporal components, we present NormalCrafter to leverage the inherent temporal priors of video diffusion models. To secure high-fidelity normal estimation across sequences, we propose Semantic Feature Regularization (SFR), which aligns diffusion features with semantic cues, encouraging the model to concentrate on the intrinsic semantics of the scene. Moreover, we introduce a two-stage training protocol that leverages both latent and pixel space learning to preserve spatial accuracy while maintaining long temporal context. Extensive evaluations demonstrate the efficacy of our method, showcasing a superior performance in generating temporally consistent normal sequences with intricate details from diverse videos.
Learning 3D-Aware GANs from Unposed Images with Template Feature Field
Apr 08, 2024



Collecting accurate camera poses of training images has been shown to well serve the learning of 3D-aware generative adversarial networks (GANs) yet can be quite expensive in practice. This work targets learning 3D-aware GANs from unposed images, for which we propose to perform on-the-fly pose estimation of training images with a learned template feature field (TeFF). Concretely, in addition to a generative radiance field as in previous approaches, we ask the generator to also learn a field from 2D semantic features while sharing the density from the radiance field. Such a framework allows us to acquire a canonical 3D feature template leveraging the dataset mean discovered by the generative model, and further efficiently estimate the pose parameters on real data. Experimental results on various challenging datasets demonstrate the superiority of our approach over state-of-the-art alternatives from both the qualitative and the quantitative perspectives.
VeRi3D: Generative Vertex-based Radiance Fields for 3D Controllable Human Image Synthesis
Sep 09, 2023



Unsupervised learning of 3D-aware generative adversarial networks has lately made much progress. Some recent work demonstrates promising results of learning human generative models using neural articulated radiance fields, yet their generalization ability and controllability lag behind parametric human models, i.e., they do not perform well when generalizing to novel pose/shape and are not part controllable. To solve these problems, we propose VeRi3D, a generative human vertex-based radiance field parameterized by vertices of the parametric human template, SMPL. We map each 3D point to the local coordinate system defined on its neighboring vertices, and use the corresponding vertex feature and local coordinates for mapping it to color and density values. We demonstrate that our simple approach allows for generating photorealistic human images with free control over camera pose, human pose, shape, as well as enabling part-level editing.
Adversarial Semantic Data Augmentation for Human Pose Estimation
Aug 03, 2020
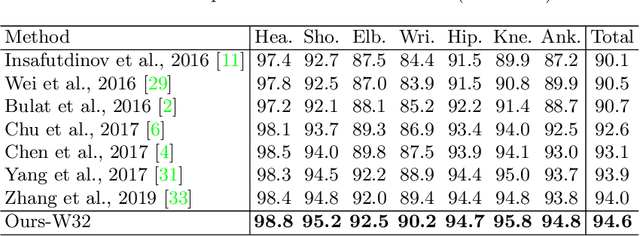
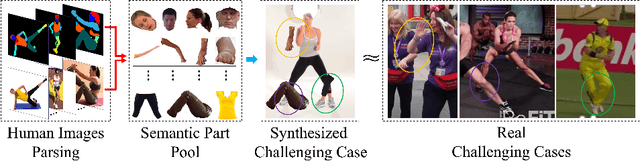
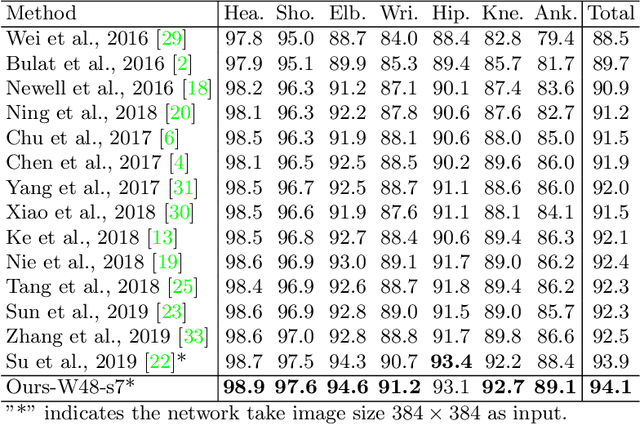
Human pose estimation is the task of localizing body keypoints from still images. The state-of-the-art methods suffer from insufficient examples of challenging cases such as symmetric appearance, heavy occlusion and nearby person. To enlarge the amounts of challenging cases, previous methods augmented images by cropping and pasting image patches with weak semantics, which leads to unrealistic appearance and limited diversity. We instead propose Semantic Data Augmentation (SDA), a method that augments images by pasting segmented body parts with various semantic granularity. Furthermore, we propose Adversarial Semantic Data Augmentation (ASDA), which exploits a generative network to dynamiclly predict tailored pasting configuration. Given off-the-shelf pose estimation network as discriminator, the generator seeks the most confusing transformation to increase the loss of the discriminator while the discriminator takes the generated sample as input and learns from it. The whole pipeline is optimized in an adversarial manner. State-of-the-art results are achieved on challenging benchmarks.
Relevant Region Prediction for Crowd Counting
May 20, 2020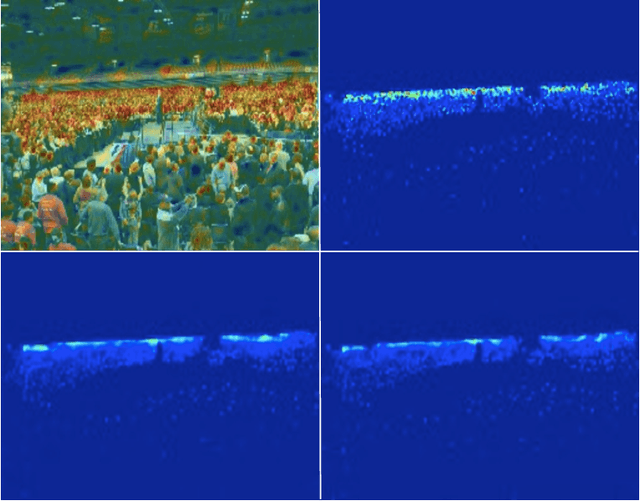
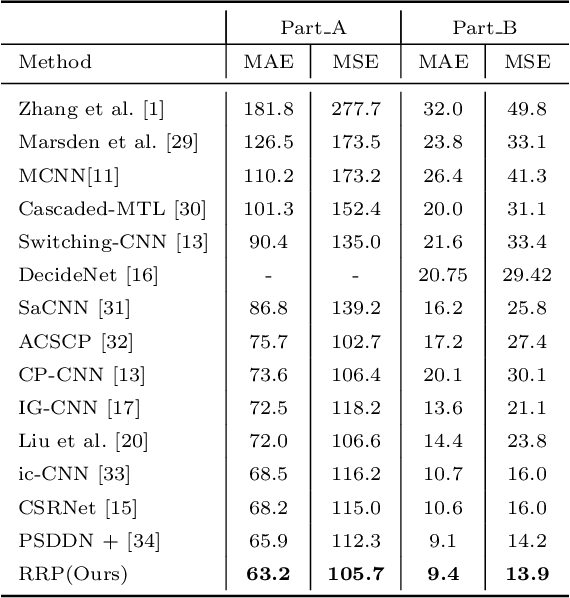
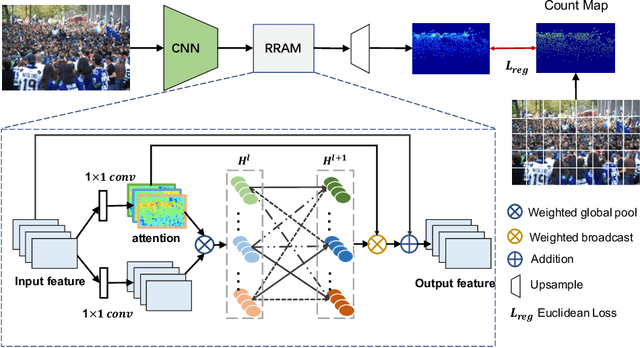
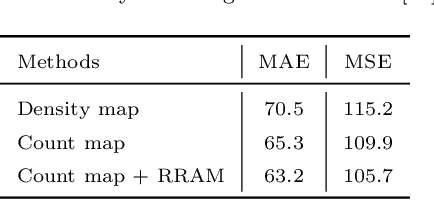
Crowd counting is a concerned and challenging task in computer vision. Existing density map based methods excessively focus on the individuals' localization which harms the crowd counting performance in highly congested scenes. In addition, the dependency between the regions of different density is also ignored. In this paper, we propose Relevant Region Prediction (RRP) for crowd counting, which consists of the Count Map and the Region Relation-Aware Module (RRAM). Each pixel in the count map represents the number of heads falling into the corresponding local area in the input image, which discards the detailed spatial information and forces the network pay more attention to counting rather than localizing individuals. Based on the Graph Convolutional Network (GCN), Region Relation-Aware Module is proposed to capture and exploit the important region dependency. The module builds a fully connected directed graph between the regions of different density where each node (region) is represented by weighted global pooled feature, and GCN is learned to map this region graph to a set of relation-aware regions representations. Experimental results on three datasets show that our method obviously outperforms other existing state-of-the-art methods.
Expression Conditional GAN for Facial Expression-to-Expression Translation
May 14, 2019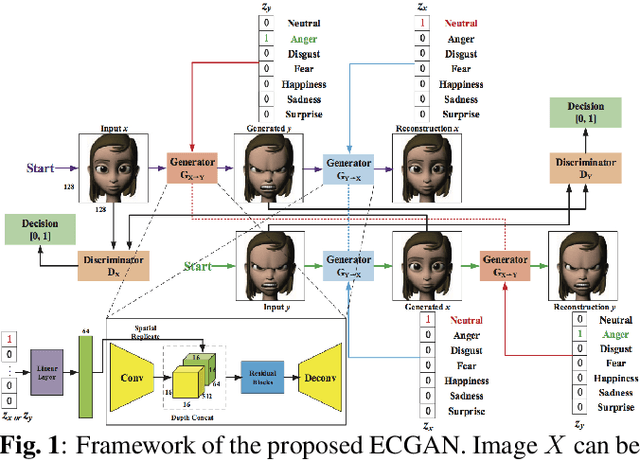

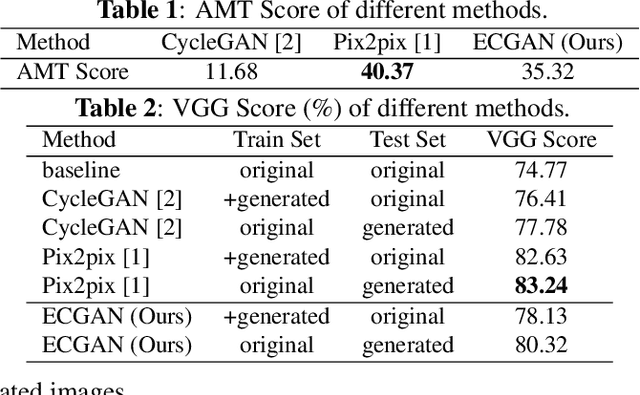

In this paper, we focus on the facial expression translation task and propose a novel Expression Conditional GAN (ECGAN) which can learn the mapping from one image domain to another one based on an additional expression attribute. The proposed ECGAN is a generic framework and is applicable to different expression generation tasks where specific facial expression can be easily controlled by the conditional attribute label. Besides, we introduce a novel face mask loss to reduce the influence of background changing. Moreover, we propose an entire framework for facial expression generation and recognition in the wild, which consists of two modules, i.e., generation and recognition. Finally, we evaluate our framework on several public face datasets in which the subjects have different races, illumination, occlusion, pose, color, content and background conditions. Even though these datasets are very diverse, both the qualitative and quantitative results demonstrate that our approach is able to generate facial expressions accurately and robustly.
Attribute-Guided Sketch Generation
Jan 28, 2019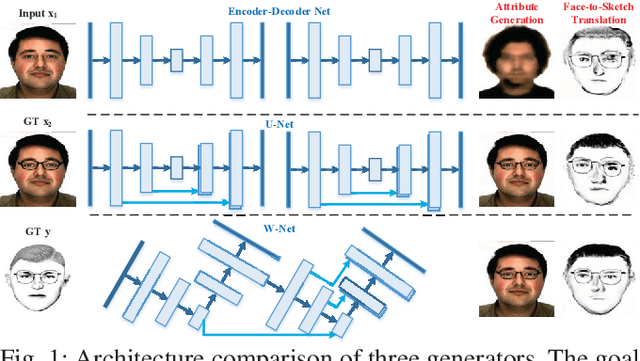
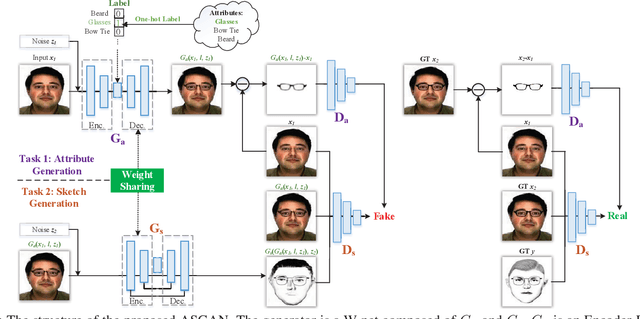


Facial attributes are important since they provide a detailed description and determine the visual appearance of human faces. In this paper, we aim at converting a face image to a sketch while simultaneously generating facial attributes. To this end, we propose a novel Attribute-Guided Sketch Generative Adversarial Network (ASGAN) which is an end-to-end framework and contains two pairs of generators and discriminators, one of which is used to generate faces with attributes while the other one is employed for image-to-sketch translation. The two generators form a W-shaped network (W-net) and they are trained jointly with a weight-sharing constraint. Additionally, we also propose two novel discriminators, the residual one focusing on attribute generation and the triplex one helping to generate realistic looking sketches. To validate our model, we have created a new large dataset with 8,804 images, named the Attribute Face Photo & Sketch (AFPS) dataset which is the first dataset containing attributes associated to face sketch images. The experimental results demonstrate that the proposed network (i) generates more photo-realistic faces with sharper facial attributes than baselines and (ii) has good generalization capability on different generative tasks.