 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerseCrafter: Dynamic Realistic Video World Model with 4D Geometric Control
Jan 08, 2026Video world models aim to simulate dynamic, real-world environments, yet existing methods struggle to provide unified and precise control over camera and multi-object motion, as videos inherently operate dynamics in the projected 2D image plane. To bridge this gap, we introduce VerseCrafter, a 4D-aware video world model that enables explicit and coherent control over both camera and object dynamics within a unified 4D geometric world state. Our approach is centered on a novel 4D Geometric Control representation, which encodes the world state through a static background point cloud and per-object 3D Gaussian trajectories. This representation captures not only an object's path but also its probabilistic 3D occupancy over time, offering a flexible, category-agnostic alternative to rigid bounding boxes or parametric models. These 4D controls are rendered into conditioning signals for a pretrained video diffusion model, enabling the generation of high-fidelity, view-consistent videos that precisely adhere to the specified dynamics. Unfortunately, another major challenge lies in the scarcity of large-scale training data with explicit 4D annotations. We address this by developing an automatic data engine that extracts the required 4D controls from in-the-wild videos, allowing us to train our model on a massive and diverse dataset.
MMSI-Video-Bench: A Holistic Benchmark for Video-Based Spatial Intelligence
Dec 11, 2025Spatial understanding over continuous visual input is crucial for MLLMs to evolve into general-purpose assistants in physical environments. Yet there is still no comprehensive benchmark that holistically assesses the progress toward this goal. In this work, we introduce MMSI-Video-Bench, a fully human-annotated benchmark for video-based spatial intelligence in MLLMs. It operationalizes a four-level framework, Perception, Planning, Prediction, and Cross-Video Reasoning, through 1,106 questions grounded in 1,278 clips from 25 datasets and in-house videos. Each item is carefully designed and reviewed by 3DV experts with explanatory rationales to ensure precise, unambiguous grounding. Leveraging its diverse data sources and holistic task coverage, MMSI-Video-Bench also supports three domain-oriented sub-benchmarks (Indoor Scene Perception Bench, Robot Bench and Grounding Bench) for targeted capability assessment. We evaluate 25 strong open-source and proprietary MLLMs, revealing a striking human--AI gap: many models perform near chance, and the best reasoning model lags humans by nearly 60%. We further find that spatially fine-tuned models still fail to generalize effectively on our benchmark. Fine-grained error analysis exposes systematic failures in geometric reasoning, motion grounding, long-horizon prediction, and cross-video correspondence. We also show that typical frame-sampling strategies transfer poorly to our reasoning-intensive benchmark, and that neither 3D spatial cues nor chain-of-thought prompting yields meaningful gains. We expect our benchmark to establish a solid testbed for advancing video-based spatial intelligence.
Bridging the Gap Between Bayesian Deep Learning and Ensemble Weather Forecasts
Nov 18, 2025Weather forecasting is fundamentally challenged by the chaotic nature of the atmosphere, necessitating probabilistic approaches to quantify uncertainty. While traditional ensemble prediction (EPS) addresses this through computationally intensive simulations, recent advances in Bayesian Deep Learning (BDL) offer a promising but often disconnected alternative. We bridge these paradigms through a unified hybrid Bayesian Deep Learning framework for ensemble weather forecasting that explicitly decomposes predictive uncertainty into epistemic and aleatoric components, learned via variational inference and a physics-informed stochastic perturbation scheme modeling flow-dependent atmospheric dynamics, respectively. We further establish a unified theoretical framework that rigorously connects BDL and EPS, providing formal theorems that decompose total predictive uncertainty into epistemic and aleatoric components under the hybrid BDL framework. We validate our framework on the large-scale 40-year ERA5 reanalysis dataset (1979-2019) with 0.25° spatial resolution. Experimental results show that our method not only improves forecast accuracy and yields better-calibrated uncertainty quantification but also achieves superior computational efficiency compared to state-of-the-art probabilistic diffusion models. We commit to making our code open-source upon acceptance of this paper.
Interleaving Reasoning for Better Text-to-Image Generation
Sep 09, 2025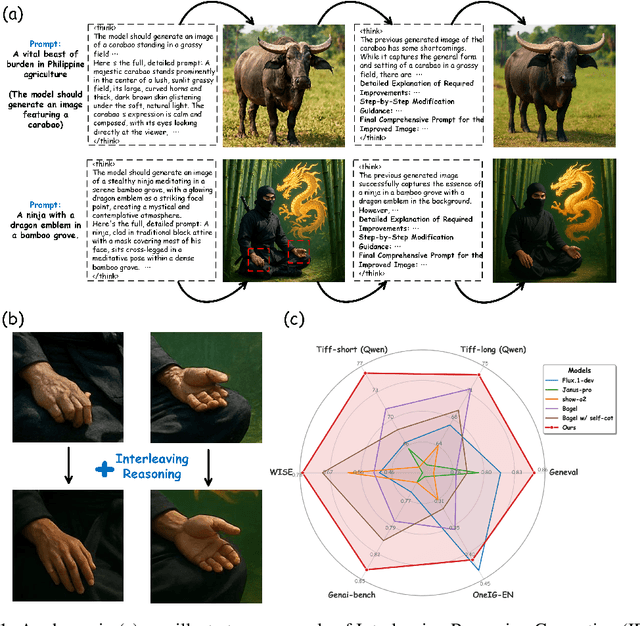

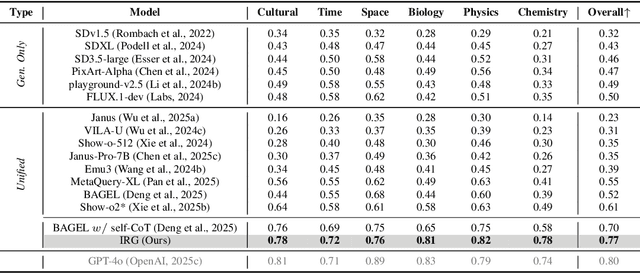
Unified multimodal understanding and generation models recently have achieve significant improvement in image generation capability, yet a large gap remains in instruction following and detail preservation compared to systems that tightly couple comprehension with generation such as GPT-4o. Motivated by recent advances in interleaving reasoning, we explore whether such reasoning can further improve Text-to-Image (T2I) generation. We introduce Interleaving Reasoning Generation (IRG), a framework that alternates between text-based thinking and image synthesis: the model first produces a text-based thinking to guide an initial image, then reflects on the result to refine fine-grained details, visual quality, and aesthetics while preserving semantics. To train IRG effectively, we propose Interleaving Reasoning Generation Learning (IRGL), which targets two sub-goals: (1) strengthening the initial think-and-generate stage to establish core content and base quality, and (2) enabling high-quality textual reflection and faithful implementation of those refinements in a subsequent image. We curate IRGL-300K, a dataset organized into six decomposed learning modes that jointly cover learning text-based thinking, and full thinking-image trajectories. Starting from a unified foundation model that natively emits interleaved text-image outputs, our two-stage training first builds robust thinking and reflection, then efficiently tunes the IRG pipeline in the full thinking-image trajectory data. Extensive experiments show SoTA performance, yielding absolute gains of 5-10 points on GenEval, WISE, TIIF, GenAI-Bench, and OneIG-EN, alongside substantial improvements in visual quality and fine-grained fidelity. The code, model weights and datasets will be released in: https://github.com/Osilly/Interleaving-Reasoning-Generation .
IC-Custom: Diverse Image Customization via In-Context Learning
Jul 02, 2025Image customization, a crucial technique for industrial media production, aims to generate content that is consistent with reference images. However, current approaches conventionally separate image customization into position-aware and position-free customization paradigms and lack a universal framework for diverse customization, limiting their applications across various scenarios. To overcome these limitations, we propose IC-Custom, a unified framework that seamlessly integrates position-aware and position-free image customization through in-context learning. IC-Custom concatenates reference images with target images to a polyptych, leveraging DiT's multi-modal attention mechanism for fine-grained token-level interactions. We introduce the In-context Multi-Modal Attention (ICMA) mechanism with learnable task-oriented register tokens and boundary-aware positional embeddings to enable the model to correctly handle different task types and distinguish various inputs in polyptych configurations. To bridge the data gap, we carefully curated a high-quality dataset of 12k identity-consistent samples with 8k from real-world sources and 4k from high-quality synthetic data, avoiding the overly glossy and over-saturated synthetic appearance. IC-Custom supports various industrial applications, including try-on, accessory placement, furniture arrangement, and creative IP customization. Extensive evaluations on our proposed ProductBench and the publicly available DreamBench demonstrate that IC-Custom significantly outperforms community workflows, closed-source models, and state-of-the-art open-source approaches. IC-Custom achieves approximately 73% higher human preference across identity consistency, harmonicity, and text alignment metrics, while training only 0.4% of the original model parameters. Project page: https://liyaowei-stu.github.io/project/IC_Custom
Understanding and Benchmarking the Trustworthiness in Multimodal LLMs for Video Understanding
Jun 14, 2025Recent advancements in multimodal large language models for video understanding (videoLLMs) have improved their ability to process dynamic multimodal data. However, trustworthiness challenges factual inaccuracies, harmful content, biases, hallucinations, and privacy risks, undermine reliability due to video data's spatiotemporal complexities. This study introduces Trust-videoLLMs, a comprehensive benchmark evaluating videoLLMs across five dimensions: truthfulness, safety, robustness, fairness, and privacy. Comprising 30 tasks with adapted, synthetic, and annotated videos, the framework assesses dynamic visual scenarios, cross-modal interactions, and real-world safety concerns. Our evaluation of 23 state-of-the-art videoLLMs (5 commercial,18 open-source) reveals significant limitations in dynamic visual scene understanding and cross-modal perturbation resilience. Open-source videoLLMs show occasional truthfulness advantages but inferior overall credibility compared to commercial models, with data diversity outperforming scale effects. These findings highlight the need for advanced safety alignment to enhance capabilities. Trust-videoLLMs provides a publicly available, extensible toolbox for standardized trustworthiness assessments, bridging the gap between accuracy-focused benchmarks and critical demands for robustness, safety, fairness, and privacy.
3DLLM-Mem: Long-Term Spatial-Temporal Memory for Embodied 3D Large Language Model
May 28, 2025Humans excel at performing complex tasks by leveraging long-term memory across temporal and spatial experiences. In contrast, current Large Language Models (LLMs) struggle to effectively plan and act in dynamic, multi-room 3D environments. We posit that part of this limitation is due to the lack of proper 3D spatial-temporal memory modeling in LLMs. To address this, we first introduce 3DMem-Bench, a comprehensive benchmark comprising over 26,000 trajectories and 2,892 embodied tasks, question-answering and captioning, designed to evaluate an agent's ability to reason over long-term memory in 3D environments. Second, we propose 3DLLM-Mem, a novel dynamic memory management and fusion model for embodied spatial-temporal reasoning and actions in LLMs. Our model uses working memory tokens, which represents current observations, as queries to selectively attend to and fuse the most useful spatial and temporal features from episodic memory, which stores past observations and interactions. Our approach allows the agent to focus on task-relevant information while maintaining memory efficiency in complex, long-horizon environments. Experimental results demonstrate that 3DLLM-Mem achieves state-of-the-art performance across various tasks, outperforming the strongest baselines by 16.5% in success rate on 3DMem-Bench's most challenging in-the-wild embodied tasks.
NormalCrafter: Learning Temporally Consistent Normals from Video Diffusion Priors
Apr 15, 2025



Surface normal estimation serves as a cornerstone for a spectrum of computer vision applications. While numerous efforts have been devoted to static image scenarios, ensuring temporal coherence in video-based normal estimation remains a formidable challenge. Instead of merely augmenting existing methods with temporal components, we present NormalCrafter to leverage the inherent temporal priors of video diffusion models. To secure high-fidelity normal estimation across sequences, we propose Semantic Feature Regularization (SFR), which aligns diffusion features with semantic cues, encouraging the model to concentrate on the intrinsic semantics of the scene. Moreover, we introduce a two-stage training protocol that leverages both latent and pixel space learning to preserve spatial accuracy while maintaining long temporal context. Extensive evaluations demonstrate the efficacy of our method, showcasing a superior performance in generating temporally consistent normal sequences with intricate details from diverse videos.
GeometryCrafter: Consistent Geometry Estimation for Open-world Videos with Diffusion Priors
Apr 01, 2025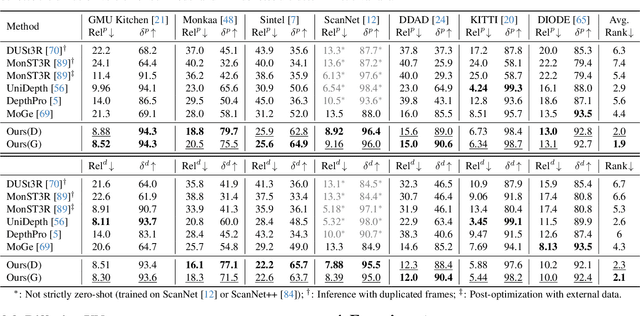
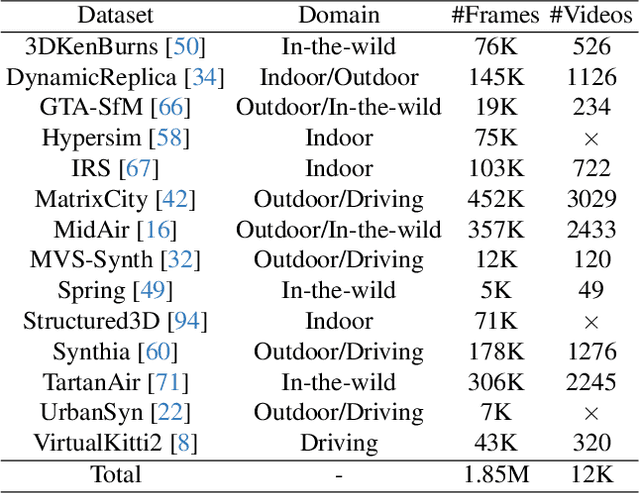


Despite remarkable advancements in video depth estimation, existing methods exhibit inherent limitations in achieving geometric fidelity through the affine-invariant predictions, limiting their applicability in reconstruction and other metrically grounded downstream tasks. We propose GeometryCrafter, a novel framework that recovers high-fidelity point map sequences with temporal coherence from open-world videos, enabling accurate 3D/4D reconstruction, camera parameter estimation, and other depth-based applications. At the core of our approach lies a point map Variational Autoencoder (VAE) that learns a latent space agnostic to video latent distributions for effective point map encoding and decoding. Leveraging the VAE, we train a video diffusion model to model the distribution of point map sequences conditioned on the input videos. Extensive evaluations on diverse datasets demonstrate that GeometryCrafter achieves state-of-the-art 3D accuracy, temporal consistency, and generalization capability.
A Concise Survey on Lane Topology Reasoning for HD Mapping
Mar 31, 2025



Lane topology reasoning techniques play a crucial role in high-definition (HD) mapping and autonomous driving applications. While recent years have witnessed significant advances in this field, there has been limited effort to consolidate these works into a comprehensive overview. This survey systematically reviews the evolution and current state of lane topology reasoning methods, categorizing them into three major paradigms: procedural modeling-based methods, aerial imagery-based methods, and onboard sensors-based methods. We analyze the progression from early rule-based approaches to modern learning-based solutions utilizing transformers, graph neural networks (GNNs), and other deep learning architectures. The paper examines standardized evaluation metrics, including road-level measures (APLS and TLTS score), and lane-level metrics (DET and TOP score), along with performance comparisons on benchmark datasets such as OpenLane-V2. We identify key technical challenges, including dataset availability and model efficiency, and outline promising directions for future research. This comprehensive review provides researchers and practitioners with insights into the theoretical frameworks, practical implementations, and emerging trends in lane topology reasoning for HD mapping applications.