 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToonComposer: Streamlining Cartoon Production with Generative Post-Keyframing
Aug 14, 2025
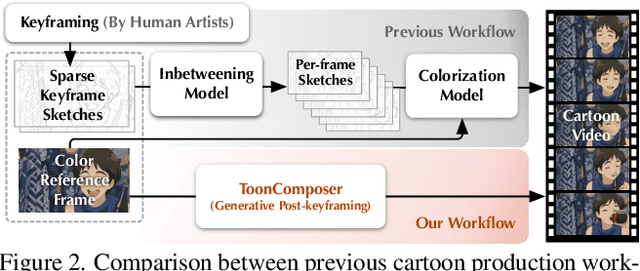
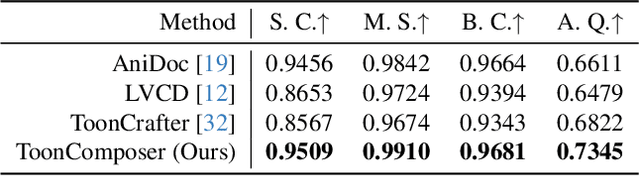
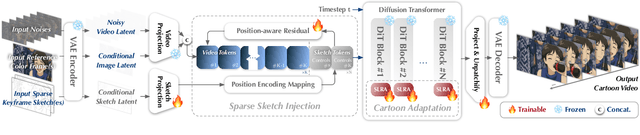
Traditional cartoon and anime production involves keyframing, inbetweening, and colorization stages, which require intensive manual effort. Despite recent advances in AI, existing methods often handle these stages separately, leading to error accumulation and artifacts. For instance, inbetweening approaches struggle with large motions, while colorization methods require dense per-frame sketches. To address this, we introduce ToonComposer, a generative model that unifies inbetweening and colorization into a single post-keyframing stage. ToonComposer employs a sparse sketch injection mechanism to provide precise control using keyframe sketches. Additionally, it uses a cartoon adaptation method with the spatial low-rank adapter to tailor a modern video foundation model to the cartoon domain while keeping its temporal prior intact. Requiring as few as a single sketch and a colored reference frame, ToonComposer excels with sparse inputs, while also supporting multiple sketches at any temporal location for more precise motion control. This dual capability reduces manual workload and improves flexibility, empowering artists in real-world scenarios. To evaluate our model, we further created PKBench, a benchmark featuring human-drawn sketches that simulate real-world use cases. Our evaluation demonstrates that ToonComposer outperforms existing methods in visual quality, motion consistency, and production efficiency, offering a superior and more flexible solution for AI-assisted cartoon production.
IC-Custom: Diverse Image Customization via In-Context Learning
Jul 02, 2025Image customization, a crucial technique for industrial media production, aims to generate content that is consistent with reference images. However, current approaches conventionally separate image customization into position-aware and position-free customization paradigms and lack a universal framework for diverse customization, limiting their applications across various scenarios. To overcome these limitations, we propose IC-Custom, a unified framework that seamlessly integrates position-aware and position-free image customization through in-context learning. IC-Custom concatenates reference images with target images to a polyptych, leveraging DiT's multi-modal attention mechanism for fine-grained token-level interactions. We introduce the In-context Multi-Modal Attention (ICMA) mechanism with learnable task-oriented register tokens and boundary-aware positional embeddings to enable the model to correctly handle different task types and distinguish various inputs in polyptych configurations. To bridge the data gap, we carefully curated a high-quality dataset of 12k identity-consistent samples with 8k from real-world sources and 4k from high-quality synthetic data, avoiding the overly glossy and over-saturated synthetic appearance. IC-Custom supports various industrial applications, including try-on, accessory placement, furniture arrangement, and creative IP customization. Extensive evaluations on our proposed ProductBench and the publicly available DreamBench demonstrate that IC-Custom significantly outperforms community workflows, closed-source models, and state-of-the-art open-source approaches. IC-Custom achieves approximately 73% higher human preference across identity consistency, harmonicity, and text alignment metrics, while training only 0.4% of the original model parameters. Project page: https://liyaowei-stu.github.io/project/IC_Custom
UP-Person: Unified Parameter-Efficient Transfer Learning for Text-based Person Retrieval
Apr 14, 2025Text-based Person Retrieval (TPR) as a multi-modal task, which aims to retrieve the target person from a pool of candidate images given a text description, has recently garnered considerable attention due to the progress of contrastive visual-language pre-trained model. Prior works leverage pre-trained CLIP to extract person visual and textual features and fully fine-tune the entire network, which have shown notable performance improvements compared to uni-modal pre-training models. However, full-tuning a large model is prone to overfitting and hinders the generalization ability. In this paper, we propose a novel Unified Parameter-Efficient Transfer Learning (PETL) method for Text-based Person Retrieval (UP-Person) to thoroughly transfer the multi-modal knowledge from CLIP. Specifically, UP-Person simultaneously integrates three lightweight PETL components including Prefix, LoRA and Adapter, where Prefix and LoRA are devised together to mine local information with task-specific information prompts, and Adapter is designed to adjust global feature representations. Additionally, two vanilla submodules are optimized to adapt to the unified architecture of TPR. For one thing, S-Prefix is proposed to boost attention of prefix and enhance the gradient propagation of prefix tokens, which improves the flexibility and performance of the vanilla prefix. For another thing, L-Adapter is designed in parallel with layer normalization to adjust the overall distribution, which can resolve conflicts caused by overlap and interaction among multiple submodules. Extensive experimental results demonstrate that our UP-Person achieves state-of-the-art results across various person retrieval datasets, including CUHK-PEDES, ICFG-PEDES and RSTPReid while merely fine-tuning 4.7\% parameters. Code is available at https://github.com/Liu-Yating/UP-Person.
BlobCtrl: A Unified and Flexible Framework for Element-level Image Generation and Editing
Mar 17, 2025Element-level visual manipulation is essential in digital content creation, but current diffusion-based methods lack the precision and flexibility of traditional tools. In this work, we introduce BlobCtrl, a framework that unifies element-level generation and editing using a probabilistic blob-based representation. By employing blobs as visual primitives, our approach effectively decouples and represents spatial location, semantic content, and identity information, enabling precise element-level manipulation. Our key contributions include: 1) a dual-branch diffusion architecture with hierarchical feature fusion for seamless foreground-background integration; 2) a self-supervised training paradigm with tailored data augmentation and score functions; and 3) controllable dropout strategies to balance fidelity and diversity. To support further research, we introduce BlobData for large-scale training and BlobBench for systematic evaluation. Experiments show that BlobCtrl excels in various element-level manipulation tasks while maintaining computational efficiency, offering a practical solution for precise and flexible visual content creation. Project page: https://liyaowei-stu.github.io/project/BlobCtrl/
DM-Adapter: Domain-Aware Mixture-of-Adapters for Text-Based Person Retrieval
Mar 06, 2025Text-based person retrieval (TPR) has gained significant attention as a fine-grained and challenging task that closely aligns with practical applications. Tailoring CLIP to person domain is now a emerging research topic due to the abundant knowledge of vision-language pretraining, but challenges still remain during fine-tuning: (i) Previous full-model fine-tuning in TPR is computationally expensive and prone to overfitting.(ii) Existing parameter-efficient transfer learning (PETL) for TPR lacks of fine-grained feature extraction. To address these issues, we propose Domain-Aware Mixture-of-Adapters (DM-Adapter), which unifies Mixture-of-Experts (MOE) and PETL to enhance fine-grained feature representations while maintaining efficiency. Specifically, Sparse Mixture-of-Adapters is designed in parallel to MLP layers in both vision and language branches, where different experts specialize in distinct aspects of person knowledge to handle features more finely. To promote the router to exploit domain information effectively and alleviate the routing imbalance, Domain-Aware Router is then developed by building a novel gating function and injecting learnable domain-aware prompts. Extensive experiments show that our DM-Adapter achieves state-of-the-art performance, outperforming previous methods by a significant margin.
DisPose: Disentangling Pose Guidance for Controllable Human Image Animation
Dec 13, 2024
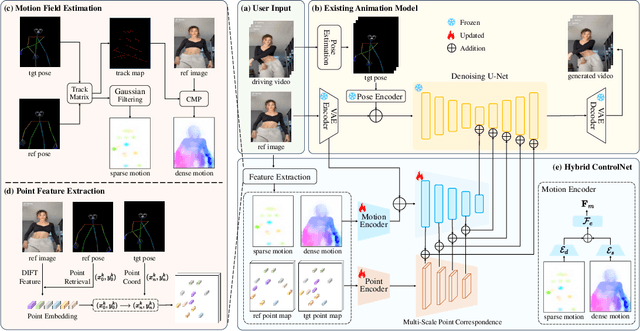
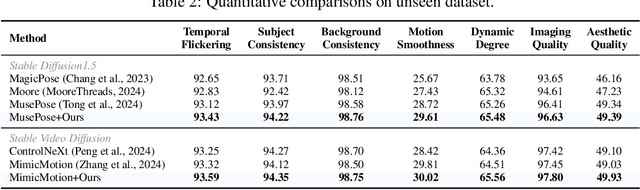

Controllable human image animation aims to generate videos from reference images using driving videos. Due to the limited control signals provided by sparse guidance (e.g., skeleton pose), recent works have attempted to introduce additional dense conditions (e.g., depth map) to ensure motion alignment. However, such strict dense guidance impairs the quality of the generated video when the body shape of the reference character differs significantly from that of the driving video. In this paper, we present DisPose to mine more generalizable and effective control signals without additional dense input, which disentangles the sparse skeleton pose in human image animation into motion field guidance and keypoint correspondence. Specifically, we generate a dense motion field from a sparse motion field and the reference image, which provides region-level dense guidance while maintaining the generalization of the sparse pose control. We also extract diffusion features corresponding to pose keypoints from the reference image, and then these point features are transferred to the target pose to provide distinct identity information. To seamlessly integrate into existing models, we propose a plug-and-play hybrid ControlNet that improves the quality and consistency of generated videos while freezing the existing model parameters. Extensive qualitative and quantitative experiments demonstrate the superiority of DisPose compared to current methods. Code: \href{https://github.com/lihxxx/DisPose}{https://github.com/lihxxx/DisPose}.
BrushEdit: All-In-One Image Inpainting and Editing
Dec 13, 2024



Image editing has advanced significantly with the development of diffusion models using both inversion-based and instruction-based methods. However, current inversion-based approaches struggle with big modifications (e.g., adding or removing objects) due to the structured nature of inversion noise, which hinders substantial changes. Meanwhile, instruction-based methods often constrain users to black-box operations, limiting direct interaction for specifying editing regions and intensity. To address these limitations, we propose BrushEdit, a novel inpainting-based instruction-guided image editing paradigm, which leverages multimodal large language models (MLLMs) and image inpainting models to enable autonomous, user-friendly, and interactive free-form instruction editing. Specifically, we devise a system enabling free-form instruction editing by integrating MLLMs and a dual-branch image inpainting model in an agent-cooperative framework to perform editing category classification, main object identification, mask acquisition, and editing area inpainting. Extensive experiments show that our framework effectively combines MLLMs and inpainting models, achieving superior performance across seven metrics including mask region preservation and editing effect coherence.
NVComposer: Boosting Generative Novel View Synthesis with Multiple Sparse and Unposed Images
Dec 04, 2024



Recent advancements in generative models have significantly improved novel view synthesis (NVS) from multi-view data. However, existing methods depend on external multi-view alignment processes, such as explicit pose estimation or pre-reconstruction, which limits their flexibility and accessibility, especially when alignment is unstable due to insufficient overlap or occlusions between views. In this paper, we propose NVComposer, a novel approach that eliminates the need for explicit external alignment. NVComposer enables the generative model to implicitly infer spatial and geometric relationships between multiple conditional views by introducing two key components: 1) an image-pose dual-stream diffusion model that simultaneously generates target novel views and condition camera poses, and 2) a geometry-aware feature alignment module that distills geometric priors from dense stereo models during training. Extensive experiments demonstrate that NVComposer achieves state-of-the-art performance in generative multi-view NVS tasks, removing the reliance on external alignment and thus improving model accessibility. Our approach shows substantial improvements in synthesis quality as the number of unposed input views increases, highlighting its potential for more flexible and accessible generative NVS systems.
Image Conductor: Precision Control for Interactive Video Synthesis
Jun 21, 2024Filmmaking and animation production often require sophisticated techniques for coordinating camera transitions and object movements, typically involving labor-intensive real-world capturing. Despite advancements in generative AI for video creation, achieving precise control over motion for interactive video asset generation remains challenging. To this end, we propose Image Conductor, a method for precise control of camera transitions and object movements to generate video assets from a single image. An well-cultivated training strategy is proposed to separate distinct camera and object motion by camera LoRA weights and object LoRA weights. To further address cinematographic variations from ill-posed trajectories, we introduce a camera-free guidance technique during inference, enhancing object movements while eliminating camera transitions. Additionally, we develop a trajectory-oriented video motion data curation pipeline for training. Quantitative and qualitative experiments demonstrate our method's precision and fine-grained control in generating motion-controllable videos from images, advancing the practical application of interactive video synthesis. Project webpage available at https://liyaowei-stu.github.io/project/ImageConductor/
Vision-Language Models Meet Meteorology: Developing Models for Extreme Weather Events Detection with Heatmaps
Jun 14, 2024

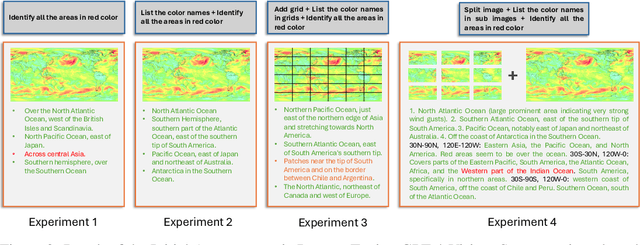

Real-time detection and prediction of extreme weather protect human lives and infrastructure. Traditional methods rely on numerical threshold setting and manual interpretation of weather heatmaps with Geographic Information Systems (GIS), which can be slow and error-prone. Our research redefines Extreme Weather Events Detection (EWED) by framing it as a Visual Question Answering (VQA) problem, thereby introducing a more precise and automated solution. Leveraging Vision-Language Models (VLM) to simultaneously process visual and textual data, we offer an effective aid to enhance the analysis process of weather heatmaps. Our initial assessment of general-purpose VLMs (e.g., GPT-4-Vision) on EWED revealed poor performance, characterized by low accuracy and frequent hallucinations due to inadequate color differentiation and insufficient meteorological knowledge. To address these challenges, we introduce ClimateIQA, the first meteorological VQA dataset, which includes 8,760 wind gust heatmaps and 254,040 question-answer pairs covering four question types, both generated from the latest climate reanalysis data. We also propose Sparse Position and Outline Tracking (SPOT), an innovative technique that leverages OpenCV and K-Means clustering to capture and depict color contours in heatmaps, providing ClimateIQA with more accurate color spatial location information. Finally, we present Climate-Zoo, the first meteorological VLM collection, which adapts VLMs to meteorological applications using the ClimateIQA dataset. Experiment results demonstrate that models from Climate-Zoo substantially outperform state-of-the-art general VLMs, achieving an accuracy increase from 0% to over 90% in EWED verification. The datasets and models in this study are publicly available for future climate science research: https://github.com/AlexJJJChen/Climate-Zoo.