 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-based Synergistic Knowledge Transfer for Text-based Person Retrieval
Paper and Code
Sep 18, 2023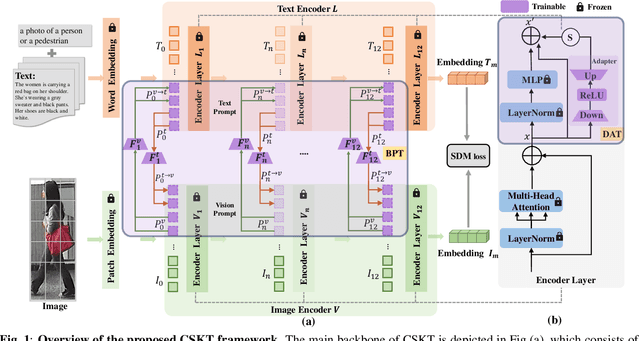
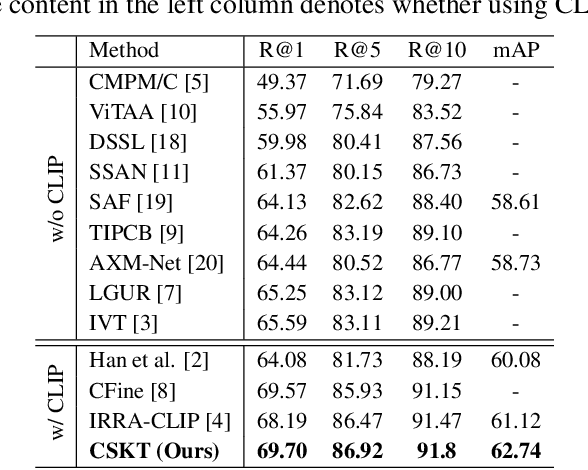
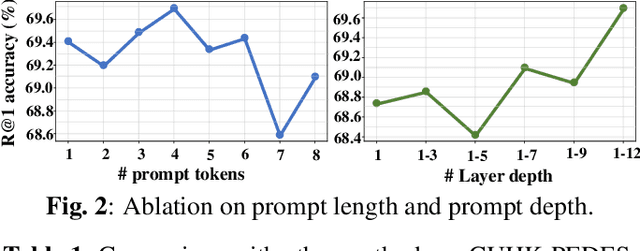

Text-based Person Retrieval aims to retrieve the target person images given a textual query. The primary challenge lies in bridging the substantial gap between vision and language modalities, especially when dealing with limited large-scale datasets. In this paper, we introduce a CLIP-based Synergistic Knowledge Transfer(CSKT) approach for TBPR. Specifically, to explore the CLIP's knowledge on input side, we first propose a Bidirectional Prompts Transferring (BPT) module constructed by text-to-image and image-to-text bidirectional prompts and coupling projections. Secondly, Dual Adapters Transferring (DAT) is designed to transfer knowledge on output side of Multi-Head Self-Attention (MHSA) in vision and language. This synergistic two-way collaborative mechanism promotes the early-stage feature fusion and efficiently exploits the existing knowledge of CLIP. CSKT outperforms the state-of-the-art approaches across three benchmark datasets when the training parameters merely account for 7.4% of the entire model, demonstrating its remarkable efficiency, effectiveness and generalization.