 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-Guided Adaptable Self-Supervised Learning for Human-Centric Visual Tasks
Jan 19, 2026Human-centric visual analysis plays a pivotal role in diverse applications, including surveillance, healthcare, and human-computer interaction. With the emergence of large-scale unlabeled human image datasets, there is an increasing need for a general unsupervised pre-training model capable of supporting diverse human-centric downstream tasks. To achieve this goal, we propose CLASP (CLIP-guided Adaptable Self-suPervised learning), a novel framework designed for unsupervised pre-training in human-centric visual tasks. CLASP leverages the powerful vision-language model CLIP to generate both low-level (e.g., body parts) and high-level (e.g., attributes) semantic pseudo-labels. These multi-level semantic cues are then integrated into the learned visual representations, enriching their expressiveness and generalizability. Recognizing that different downstream tasks demand varying levels of semantic granularity, CLASP incorporates a Prompt-Controlled Mixture-of-Experts (MoE) module. MoE dynamically adapts feature extraction based on task-specific prompts, mitigating potential feature conflicts and enhancing transferability. Furthermore, CLASP employs a multi-task pre-training strategy, where part- and attribute-level pseudo-labels derived from CLIP guide the representation learning process. Extensive experiments across multiple benchmarks demonstrate that CLASP consistently outperforms existing unsupervised pre-training methods, advancing the field of human-centric visual analysis.
UP-Person: Unified Parameter-Efficient Transfer Learning for Text-based Person Retrieval
Apr 14, 2025Text-based Person Retrieval (TPR) as a multi-modal task, which aims to retrieve the target person from a pool of candidate images given a text description, has recently garnered considerable attention due to the progress of contrastive visual-language pre-trained model. Prior works leverage pre-trained CLIP to extract person visual and textual features and fully fine-tune the entire network, which have shown notable performance improvements compared to uni-modal pre-training models. However, full-tuning a large model is prone to overfitting and hinders the generalization ability. In this paper, we propose a novel Unified Parameter-Efficient Transfer Learning (PETL) method for Text-based Person Retrieval (UP-Person) to thoroughly transfer the multi-modal knowledge from CLIP. Specifically, UP-Person simultaneously integrates three lightweight PETL components including Prefix, LoRA and Adapter, where Prefix and LoRA are devised together to mine local information with task-specific information prompts, and Adapter is designed to adjust global feature representations. Additionally, two vanilla submodules are optimized to adapt to the unified architecture of TPR. For one thing, S-Prefix is proposed to boost attention of prefix and enhance the gradient propagation of prefix tokens, which improves the flexibility and performance of the vanilla prefix. For another thing, L-Adapter is designed in parallel with layer normalization to adjust the overall distribution, which can resolve conflicts caused by overlap and interaction among multiple submodules. Extensive experimental results demonstrate that our UP-Person achieves state-of-the-art results across various person retrieval datasets, including CUHK-PEDES, ICFG-PEDES and RSTPReid while merely fine-tuning 4.7\% parameters. Code is available at https://github.com/Liu-Yating/UP-Person.
DM-Adapter: Domain-Aware Mixture-of-Adapters for Text-Based Person Retrieval
Mar 06, 2025Text-based person retrieval (TPR) has gained significant attention as a fine-grained and challenging task that closely aligns with practical applications. Tailoring CLIP to person domain is now a emerging research topic due to the abundant knowledge of vision-language pretraining, but challenges still remain during fine-tuning: (i) Previous full-model fine-tuning in TPR is computationally expensive and prone to overfitting.(ii) Existing parameter-efficient transfer learning (PETL) for TPR lacks of fine-grained feature extraction. To address these issues, we propose Domain-Aware Mixture-of-Adapters (DM-Adapter), which unifies Mixture-of-Experts (MOE) and PETL to enhance fine-grained feature representations while maintaining efficiency. Specifically, Sparse Mixture-of-Adapters is designed in parallel to MLP layers in both vision and language branches, where different experts specialize in distinct aspects of person knowledge to handle features more finely. To promote the router to exploit domain information effectively and alleviate the routing imbalance, Domain-Aware Router is then developed by building a novel gating function and injecting learnable domain-aware prompts. Extensive experiments show that our DM-Adapter achieves state-of-the-art performance, outperforming previous methods by a significant margin.
Morph: A Motion-free Physics Optimization Framework for Human Motion Generation
Nov 22, 2024Human motion generation plays a vital role in applications such as digital humans and humanoid robot control. However, most existing approaches disregard physics constraints, leading to the frequent production of physically implausible motions with pronounced artifacts such as floating and foot sliding. In this paper, we propose \textbf{Morph}, a \textbf{Mo}tion-f\textbf{r}ee \textbf{ph}ysics optimization framework, comprising a Motion Generator and a Motion Physics Refinement module, for enhancing physical plausibility without relying on costly real-world motion data. Specifically, the Motion Generator is responsible for providing large-scale synthetic motion data, while the Motion Physics Refinement Module utilizes these synthetic data to train a motion imitator within a physics simulator, enforcing physical constraints to project the noisy motions into a physically-plausible space. These physically refined motions, in turn, are used to fine-tune the Motion Generator, further enhancing its capability. Experiments on both text-to-motion and music-to-dance generation tasks demonstrate that our framework achieves state-of-the-art motion generation quality while improving physical plausibility drastically.
M$^3$GPT: An Advanced Multimodal, Multitask Framework for Motion Comprehension and Generation
May 29, 2024This paper presents M$^3$GPT, an advanced $\textbf{M}$ultimodal, $\textbf{M}$ultitask framework for $\textbf{M}$otion comprehension and generation. M$^3$GPT operates on three fundamental principles. The first focuses on creating a unified representation space for various motion-relevant modalities. We employ discrete vector quantization for multimodal control and generation signals, such as text, music and motion/dance, enabling seamless integration into a large language model (LLM) with a single vocabulary. The second involves modeling model generation directly in the raw motion space. This strategy circumvents the information loss associated with discrete tokenizer, resulting in more detailed and comprehensive model generation. Third, M$^3$GPT learns to model the connections and synergies among various motion-relevant tasks. Text, the most familiar and well-understood modality for LLMs, is utilized as a bridge to establish connections between different motion tasks, facilitating mutual reinforcement. To our knowledge, M$^3$GPT is the first model capable of comprehending and generating motions based on multiple signals. Extensive experiments highlight M$^3$GPT's superior performance across various motion-relevant tasks and its powerful zero-shot generalization capabilities for extremely challenging tasks.
Fast Implicit Neural Representation Image Codec in Resource-limited Devices
Jan 23, 2024Displaying high-quality images on edge devices, such as augmented reality devices, is essential for enhancing the user experience. However, these devices often face power consumption and computing resource limitations, making it challenging to apply many deep learning-based image compression algorithms in this field. Implicit Neural Representation (INR) for image compression is an emerging technology that offers two key benefits compared to cutting-edge autoencoder models: low computational complexity and parameter-free decoding. It also outperforms many traditional and early neural compression methods in terms of quality. In this study, we introduce a new Mixed Autoregressive Model (MARM) to significantly reduce the decoding time for the current INR codec, along with a new synthesis network to enhance reconstruction quality. MARM includes our proposed Autoregressive Upsampler (ARU) blocks, which are highly computationally efficient, and ARM from previous work to balance decoding time and reconstruction quality. We also propose enhancing ARU's performance using a checkerboard two-stage decoding strategy. Moreover, the ratio of different modules can be adjusted to maintain a balance between quality and speed. Comprehensive experiments demonstrate that our method significantly improves computational efficiency while preserving image quality. With different parameter settings, our method can outperform popular AE-based codecs in constrained environments in terms of both quality and decoding time, or achieve state-of-the-art reconstruction quality compared to other INR codecs.
CLIP-based Synergistic Knowledge Transfer for Text-based Person Retrieval
Sep 18, 2023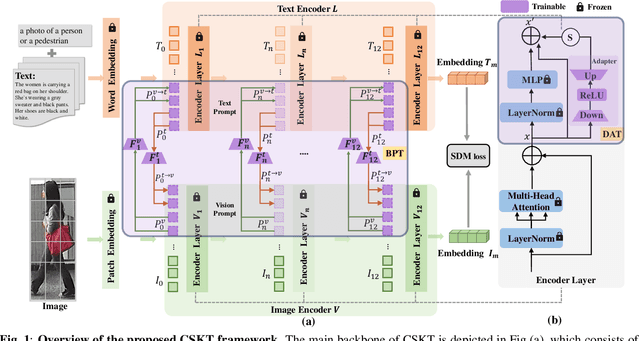
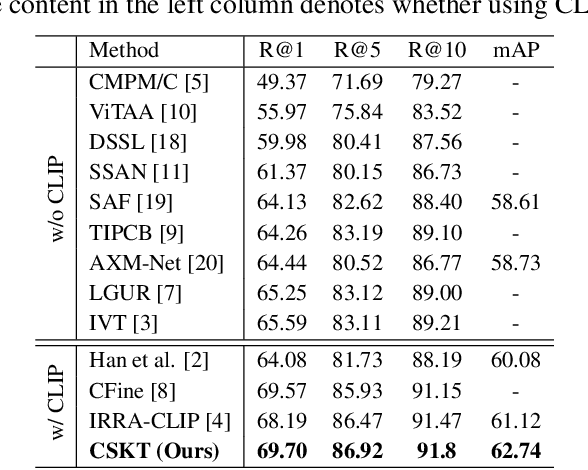
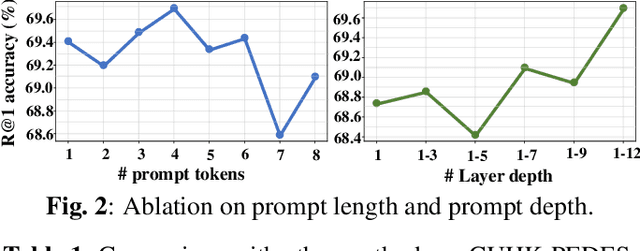

Text-based Person Retrieval aims to retrieve the target person images given a textual query. The primary challenge lies in bridging the substantial gap between vision and language modalities, especially when dealing with limited large-scale datasets. In this paper, we introduce a CLIP-based Synergistic Knowledge Transfer(CSKT) approach for TBPR. Specifically, to explore the CLIP's knowledge on input side, we first propose a Bidirectional Prompts Transferring (BPT) module constructed by text-to-image and image-to-text bidirectional prompts and coupling projections. Secondly, Dual Adapters Transferring (DAT) is designed to transfer knowledge on output side of Multi-Head Self-Attention (MHSA) in vision and language. This synergistic two-way collaborative mechanism promotes the early-stage feature fusion and efficiently exploits the existing knowledge of CLIP. CSKT outperforms the state-of-the-art approaches across three benchmark datasets when the training parameters merely account for 7.4% of the entire model, demonstrating its remarkable efficiency, effectiveness and generalization.
Lifelong Person Re-Identification via Knowledge Refreshing and Consolidation
Nov 29, 2022



Lifelong person re-identification (LReID) is in significant demand for real-world development as a large amount of ReID data is captured from diverse locations over time and cannot be accessed at once inherently. However, a key challenge for LReID is how to incrementally preserve old knowledge and gradually add new capabilities to the system. Unlike most existing LReID methods, which mainly focus on dealing with catastrophic forgetting, our focus is on a more challenging problem, which is, not only trying to reduce the forgetting on old tasks but also aiming to improve the model performance on both new and old tasks during the lifelong learning process. Inspired by the biological process of human cognition where the somatosensory neocortex and the hippocampus work together in memory consolidation, we formulated a model called Knowledge Refreshing and Consolidation (KRC) that achieves both positive forward and backward transfer. More specifically, a knowledge refreshing scheme is incorporated with the knowledge rehearsal mechanism to enable bi-directional knowledge transfer by introducing a dynamic memory model and an adaptive working model. Moreover, a knowledge consolidation scheme operating on the dual space further improves model stability over the long term. Extensive evaluations show KRC's superiority over the state-of-the-art LReID methods on challenging pedestrian benchmarks.
Towards Mitigating the Problem of Insufficient and Ambiguous Supervision in Online Crowdsourcing Annotation
Oct 20, 2022
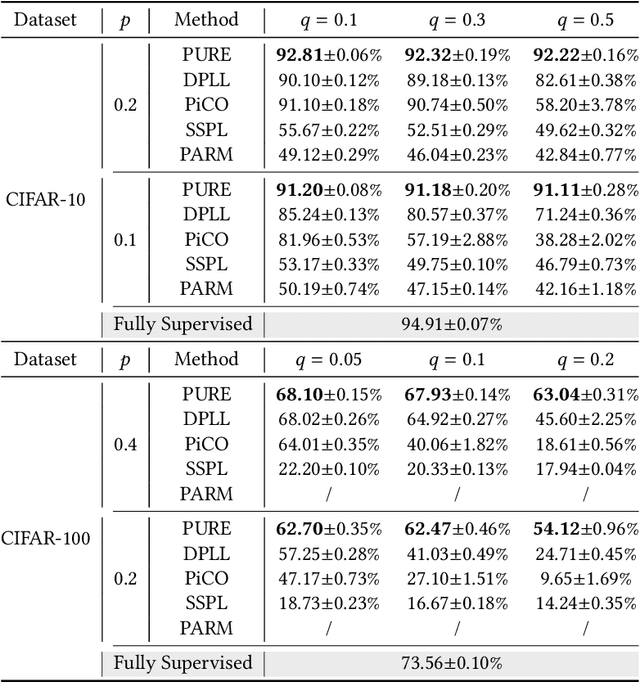

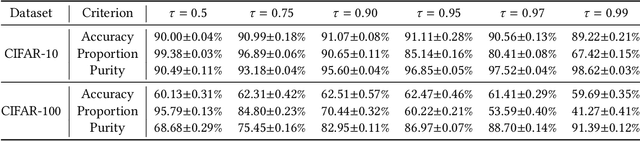
In real-world crowdsourcing annotation systems, due to differences in user knowledge and cultural backgrounds, as well as the high cost of acquiring annotation information, the supervision information we obtain might be insufficient and ambiguous. To mitigate the negative impacts, in this paper, we investigate a more general and broadly applicable learning problem, i.e. \emph{semi-supervised partial label learning}, and propose a novel method based on pseudo-labeling and contrastive learning. Following the key inventing principle, our method facilitate the partial label disambiguation process with unlabeled data and at the same time assign reliable pseudo-labels to weakly supervised examples. Specifically, our method learns from the ambiguous labeling information via partial cross-entropy loss. Meanwhile, high-accuracy pseudo-labels are generated for both partial and unlabeled examples through confidence-based thresholding and contrastive learning is performed in a hybrid unsupervised and supervised manner for more discriminative representations, while its supervision increases curriculumly. The two main components systematically work as a whole and reciprocate each other. In experiments, our method consistently outperforms all comparing methods by a significant margin and set up the first state-of-the-art performance for semi-supervised partial label learning on image benchmarks.
Pose-guided Visible Part Matching for Occluded Person ReID
Apr 01, 2020
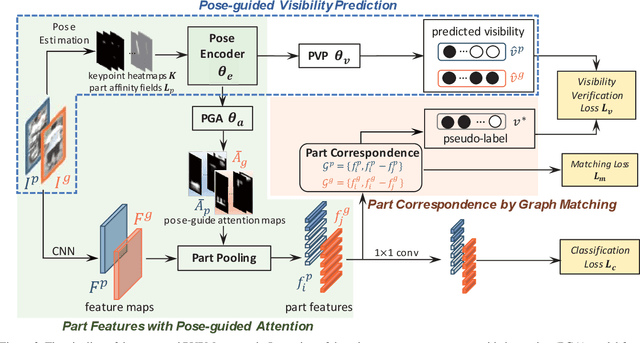
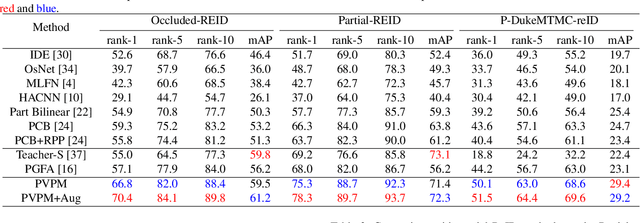
Occluded person re-identification is a challenging task as the appearance varies substantially with various obstacles, especially in the crowd scenario. To address this issue, we propose a Pose-guided Visible Part Matching (PVPM) method that jointly learns the discriminative features with pose-guided attention and self-mines the part visibility in an end-to-end framework. Specifically, the proposed PVPM includes two key components: 1) pose-guided attention (PGA) method for part feature pooling that exploits more discriminative local features; 2) pose-guided visibility predictor (PVP) that estimates whether a part suffers the occlusion or not. As there are no ground truth training annotations for the occluded part, we turn to utilize the characteristic of part correspondence in positive pairs and self-mining the correspondence scores via graph matching. The generated correspondence scores are then utilized as pseudo-labels for visibility predictor (PVP). Experimental results on three reported occluded benchmarks show that the proposed method achieves competitive performance to state-of-the-art methods. The source codes are available at https://github.com/hh23333/PVPM