 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicit Uncertainty Modeling for Active CLIP Adaptation with Dual Prompt Tuning
Feb 04, 2026Pre-trained vision-language models such as CLIP exhibit strong transferability, yet adapting them to downstream image classification tasks under limited annotation budgets remains challenging. In active learning settings, the model must select the most informative samples for annotation from a large pool of unlabeled data. Existing approaches typically estimate uncertainty via entropy-based criteria or representation clustering, without explicitly modeling uncertainty from the model perspective. In this work, we propose a robust uncertainty modeling framework for active CLIP adaptation based on dual-prompt tuning. We introduce two learnable prompts in the textual branch of CLIP. The positive prompt enhances the discriminability of task-specific textual embeddings corresponding to light-weight tuned visual embeddings, improving classification reliability. Meanwhile, the negative prompt is trained in an reversed manner to explicitly model the probability that the predicted label is correct, providing a principled uncertainty signal for guiding active sample selection. Extensive experiments across different fine-tuning paradigms demonstrate that our method consistently outperforms existing active learning methods under the same annotation budget.
Fine-tuning Pre-trained Vision-Language Models in a Human-Annotation-Free Manner
Feb 04, 2026Large-scale vision-language models (VLMs) such as CLIP exhibit strong zero-shot generalization, but adapting them to downstream tasks typically requires costly labeled data. Existing unsupervised self-training methods rely on pseudo-labeling, yet often suffer from unreliable confidence filtering, confirmation bias, and underutilization of low-confidence samples. We propose Collaborative Fine-Tuning (CoFT), an unsupervised adaptation framework that leverages unlabeled data through a dual-model, cross-modal collaboration mechanism. CoFT introduces a dual-prompt learning strategy with positive and negative textual prompts to explicitly model pseudo-label cleanliness in a sample-dependent manner, removing the need for hand-crafted thresholds or noise assumptions. The negative prompt also regularizes lightweight visual adaptation modules, improving robustness under noisy supervision. CoFT employs a two-phase training scheme, transitioning from parameter-efficient fine-tuning on high-confidence samples to full fine-tuning guided by collaboratively filtered pseudo-labels. Building on CoFT, CoFT+ further enhances adaptation via iterative fine-tuning, momentum contrastive learning, and LLM-generated prompts. Extensive experiments demonstrate consistent gains over existing unsupervised methods and even few-shot supervised baselines.
Delving into Identify-Emphasize Paradigm for Combating Unknown Bias
Feb 22, 2023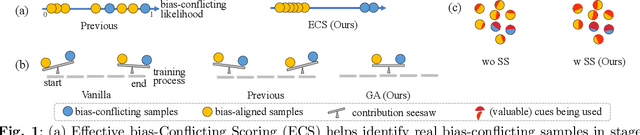

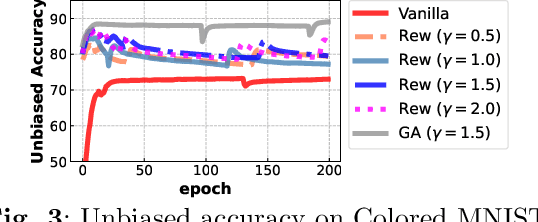

Dataset biases are notoriously detrimental to model robustness and generalization. The identify-emphasize paradigm appears to be effective in dealing with unknown biases. However, we discover that it is still plagued by two challenges: A, the quality of the identified bias-conflicting samples is far from satisfactory; B, the emphasizing strategies only produce suboptimal performance. In this paper, for challenge A, we propose an effective bias-conflicting scoring method (ECS) to boost the identification accuracy, along with two practical strategies -- peer-picking and epoch-ensemble. For challenge B, we point out that the gradient contribution statistics can be a reliable indicator to inspect whether the optimization is dominated by bias-aligned samples. Then, we propose gradient alignment (GA), which employs gradient statistics to balance the contributions of the mined bias-aligned and bias-conflicting samples dynamically throughout the learning process, forcing models to leverage intrinsic features to make fair decisions. Furthermore, we incorporate self-supervised (SS) pretext tasks into training, which enable models to exploit richer features rather than the simple shortcuts, resulting in more robust models. Experiments are conducted on multiple datasets in various settings, demonstrating that the proposed solution can mitigate the impact of unknown biases and achieve state-of-the-art performance.
Towards Mitigating the Problem of Insufficient and Ambiguous Supervision in Online Crowdsourcing Annotation
Oct 20, 2022
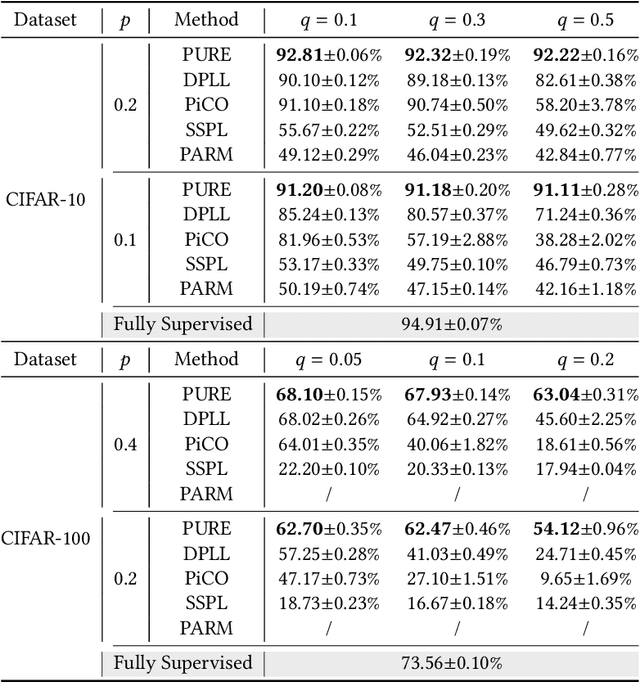

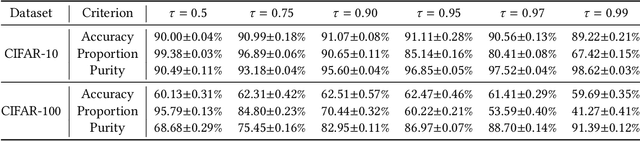
In real-world crowdsourcing annotation systems, due to differences in user knowledge and cultural backgrounds, as well as the high cost of acquiring annotation information, the supervision information we obtain might be insufficient and ambiguous. To mitigate the negative impacts, in this paper, we investigate a more general and broadly applicable learning problem, i.e. \emph{semi-supervised partial label learning}, and propose a novel method based on pseudo-labeling and contrastive learning. Following the key inventing principle, our method facilitate the partial label disambiguation process with unlabeled data and at the same time assign reliable pseudo-labels to weakly supervised examples. Specifically, our method learns from the ambiguous labeling information via partial cross-entropy loss. Meanwhile, high-accuracy pseudo-labels are generated for both partial and unlabeled examples through confidence-based thresholding and contrastive learning is performed in a hybrid unsupervised and supervised manner for more discriminative representations, while its supervision increases curriculumly. The two main components systematically work as a whole and reciprocate each other. In experiments, our method consistently outperforms all comparing methods by a significant margin and set up the first state-of-the-art performance for semi-supervised partial label learning on image benchmarks.