 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into Identify-Emphasize Paradigm for Combating Unknown Bias
Paper and Code
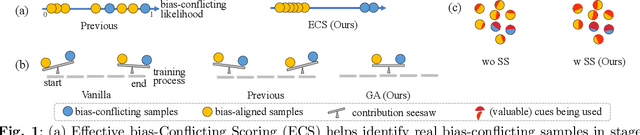

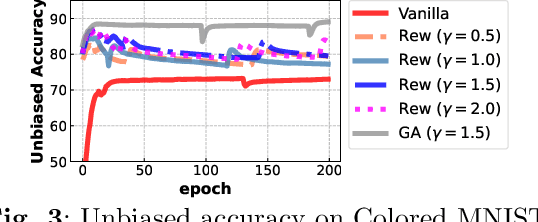

Dataset biases are notoriously detrimental to model robustness and generalization. The identify-emphasize paradigm appears to be effective in dealing with unknown biases. However, we discover that it is still plagued by two challenges: A, the quality of the identified bias-conflicting samples is far from satisfactory; B, the emphasizing strategies only produce suboptimal performance. In this paper, for challenge A, we propose an effective bias-conflicting scoring method (ECS) to boost the identification accuracy, along with two practical strategies -- peer-picking and epoch-ensemble. For challenge B, we point out that the gradient contribution statistics can be a reliable indicator to inspect whether the optimization is dominated by bias-aligned samples. Then, we propose gradient alignment (GA), which employs gradient statistics to balance the contributions of the mined bias-aligned and bias-conflicting samples dynamically throughout the learning process, forcing models to leverage intrinsic features to make fair decisions. Furthermore, we incorporate self-supervised (SS) pretext tasks into training, which enable models to exploit richer features rather than the simple shortcuts, resulting in more robust models. Experiments are conducted on multiple datasets in various settings, demonstrating that the proposed solution can mitigate the impact of unknown biases and achieve state-of-the-art performance.