 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJMed48k: A Multi-Profession Japanese Medical Licensing Benchmark for Vision-Language Model Evaluation
May 21, 2026We introduce JMed48k, a multi-profession Japanese healthcare licensing benchmark for evaluating vision-language models. Built from official PDF materials released by the Japanese Ministry of Health, Labour and Welfare, JMed48k contains 48,862 exam questions and 20,142 images from 11 national licensing examinations between 2005 and 2025, with visual content annotated under an 8-type taxonomy. From this corpus, we derive JMed48k-Eval, a recent five-year evaluation subset with 12,484 scored questions, including 9,905 text-only questions and 2,579 questions with images. We evaluate 21 proprietary, open-source, and medical-specific models, reporting text-only and with-image performance separately. Because these subsets contain different questions, we further introduce a paired image-removal audit that evaluates questions with images before and after removing visual content to explore four answer-transition states. The audit shows that proprietary and open source models gain substantially from images, whereas medical-specific systems show limited observable use of visual evidence, with many correct answers persisting after image removal. Even among proprietary models, the net image-removal effect varies sevenfold across professions, from +5.7 points on Physician questions to +39.8 points on Public Health Nurse questions. We release JMed48k to support reproducible, profession-stratified evaluation of vision-language models in medical licensing settings.
Memento-Skills: Let Agents Design Agents
Mar 19, 2026We introduce \emph{Memento-Skills}, a generalist, continually-learnable LLM agent system that functions as an \emph{agent-designing agent}: it autonomously constructs, adapts, and improves task-specific agents through experience. The system is built on a memory-based reinforcement learning framework with \emph{stateful prompts}, where reusable skills (stored as structured markdown files) serve as persistent, evolving memory. These skills encode both behaviour and context, enabling the agent to carry forward knowledge across interactions. Starting from simple elementary skills (like Web search and terminal operations), the agent continually improves via the \emph{Read--Write Reflective Learning} mechanism introduced in \emph{Memento~2}~\cite{wang2025memento2}. In the \emph{read} phase, a behaviour-trainable skill router selects the most relevant skill conditioned on the current stateful prompt; in the \emph{write} phase, the agent updates and expands its skill library based on new experience. This closed-loop design enables \emph{continual learning without updating LLM parameters}, as all adaptation is realised through the evolution of externalised skills and prompts. Unlike prior approaches that rely on human-designed agents, Memento-Skills enables a generalist agent to \emph{design agents end-to-end} for new tasks. Through iterative skill generation and refinement, the system progressively improves its own capabilities. Experiments on the \emph{General AI Assistants} benchmark and \emph{Humanity's Last Exam} demonstrate sustained gains, achieving 26.2\% and 116.2\% relative improvements in overall accuracy, respectively. Code is available at https://github.com/Memento-Teams/Memento-Skills.
Pura: An Efficient Privacy-Preserving Solution for Face Recognition
May 21, 2025



Face recognition is an effective technology for identifying a target person by facial images. However, sensitive facial images raises privacy concerns. Although privacy-preserving face recognition is one of potential solutions, this solution neither fully addresses the privacy concerns nor is efficient enough. To this end, we propose an efficient privacy-preserving solution for face recognition, named Pura, which sufficiently protects facial privacy and supports face recognition over encrypted data efficiently. Specifically, we propose a privacy-preserving and non-interactive architecture for face recognition through the threshold Paillier cryptosystem. Additionally, we carefully design a suite of underlying secure computing protocols to enable efficient operations of face recognition over encrypted data directly. Furthermore, we introduce a parallel computing mechanism to enhance the performance of the proposed secure computing protocols. Privacy analysis demonstrates that Pura fully safeguards personal facial privacy. Experimental evaluations demonstrate that Pura achieves recognition speeds up to 16 times faster than the state-of-the-art.
CT2C-QA: Multimodal Question Answering over Chinese Text, Table and Chart
Oct 28, 2024Multimodal Question Answering (MMQA) is crucial as it enables comprehensive understanding and accurate responses by integrating insights from diverse data representations such as tables, charts, and text. Most existing researches in MMQA only focus on two modalities such as image-text QA, table-text QA and chart-text QA, and there remains a notable scarcity in studies that investigate the joint analysis of text, tables, and charts. In this paper, we present C$\text{T}^2$C-QA, a pioneering Chinese reasoning-based QA dataset that includes an extensive collection of text, tables, and charts, meticulously compiled from 200 selectively sourced webpages. Our dataset simulates real webpages and serves as a great test for the capability of the model to analyze and reason with multimodal data, because the answer to a question could appear in various modalities, or even potentially not exist at all. Additionally, we present AED (\textbf{A}llocating, \textbf{E}xpert and \textbf{D}esicion), a multi-agent system implemented through collaborative deployment, information interaction, and collective decision-making among different agents. Specifically, the Assignment Agent is in charge of selecting and activating expert agents, including those proficient in text, tables, and charts. The Decision Agent bears the responsibility of delivering the final verdict, drawing upon the analytical insights provided by these expert agents. We execute a comprehensive analysis, comparing AED with various state-of-the-art models in MMQA, including GPT-4. The experimental outcomes demonstrate that current methodologies, including GPT-4, are yet to meet the benchmarks set by our dataset.
Can Vision Language Models Learn from Visual Demonstrations of Ambiguous Spatial Reasoning?
Sep 25, 2024

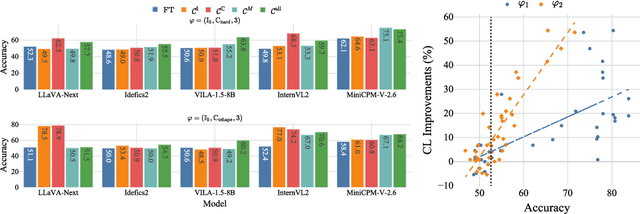

Large vision-language models (VLMs) have become state-of-the-art for many computer vision tasks, with in-context learning (ICL) as a popular adaptation strategy for new ones. But can VLMs learn novel concepts purely from visual demonstrations, or are they limited to adapting to the output format of ICL examples? We propose a new benchmark we call Spatial Visual Ambiguity Tasks (SVAT) that challenges state-of-the-art VLMs to learn new visuospatial tasks in-context. We find that VLMs fail to do this zero-shot, and sometimes continue to fail after finetuning. However, adding simpler data to the training by curriculum learning leads to improved ICL performance.
Set the Clock: Temporal Alignment of Pretrained Language Models
Feb 26, 2024Language models (LMs) are trained on web text originating from many points in time and, in general, without any explicit temporal grounding. This work investigates the temporal chaos of pretrained LMs and explores various methods to align their internal knowledge to a target time, which we call "temporal alignment." To do this, we first automatically construct a dataset containing 20K time-sensitive questions and their answers for each year from 2000 to 2023. Based on this dataset, we empirically show that pretrained LMs (e.g., LLaMa2), despite having a recent pretraining cutoff (e.g., 2022), mostly answer questions using earlier knowledge (e.g., in 2019). We then develop several methods, from prompting to finetuning, to align LMs to use their most recent knowledge when answering questions, and investigate various factors in this alignment. Our experiments show that aligning LLaMa2 to the year 2022 can boost its performance by up to 62% relatively as measured by that year, even without mentioning time information explicitly, indicating the possibility of aligning models' internal sense of time after pretraining. Finally, we find that alignment to a historical time is also possible, with up to 2.8$\times$ the performance of the unaligned LM in 2010 if finetuning models to that year. These findings hint at the sophistication of LMs' internal knowledge organization and the necessity of tuning them properly.
APT: Adaptive Pruning and Tuning Pretrained Language Models for Efficient Training and Inference
Jan 22, 2024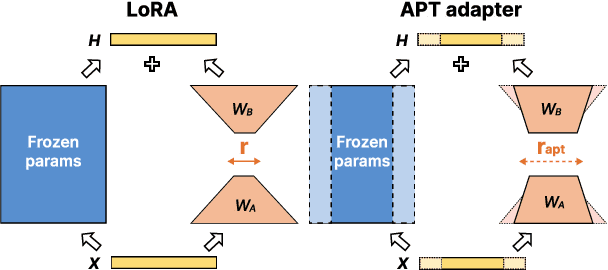
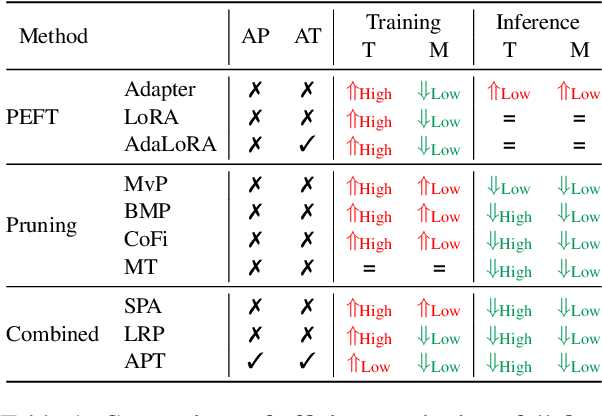
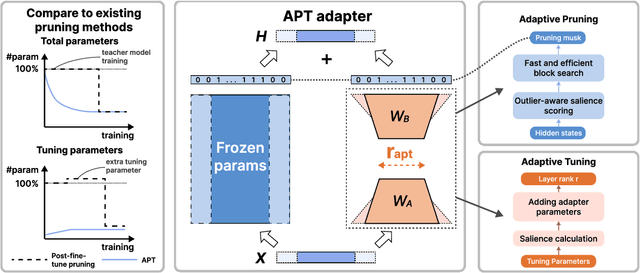

Fine-tuning and inference with large Language Models (LM) are generally known to be expensive. Parameter-efficient fine-tuning over pretrained LMs reduces training memory by updating a small number of LM parameters but does not improve inference efficiency. Structured pruning improves LM inference efficiency by removing consistent parameter blocks, yet often increases training memory and time. To improve both training and inference efficiency, we introduce APT that adaptively prunes and tunes parameters for the LMs. At the early stage of fine-tuning, APT dynamically adds salient tuning parameters for fast and accurate convergence while discarding unimportant parameters for efficiency. Compared to baselines, our experiments show that APT maintains up to 98% task performance when pruning RoBERTa and T5 models with 40% parameters left while keeping 86.4% LLaMA models' performance with 70% parameters remained. Furthermore, APT speeds up LMs fine-tuning by up to 8x and reduces large LMs memory training footprint by up to 70%.
Large Language Models are Complex Table Parsers
Dec 13, 2023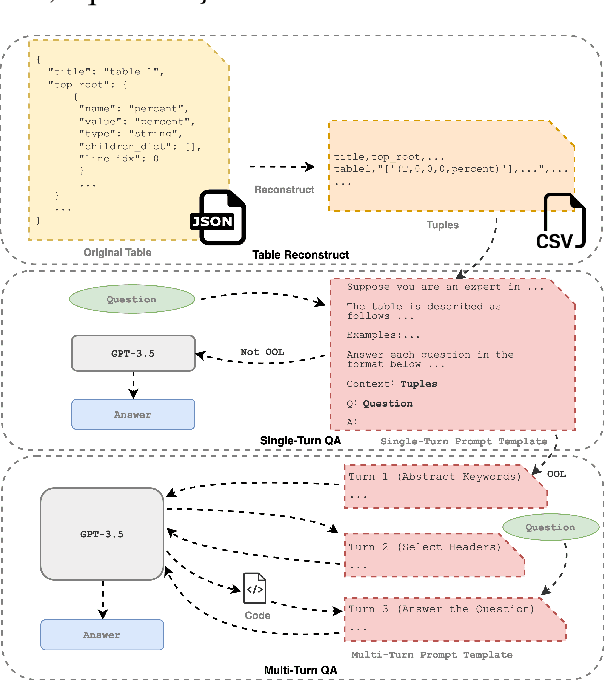
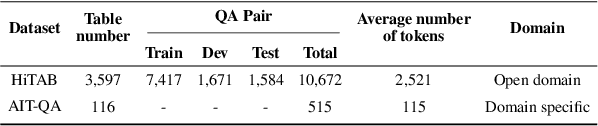
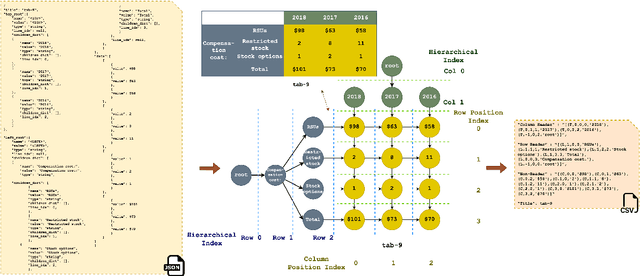

With the Generative Pre-trained Transformer 3.5 (GPT-3.5) exhibiting remarkable reasoning and comprehension abilities in Natural Language Processing (NLP), most Question Answering (QA) research has primarily centered around general QA tasks based on GPT, neglecting the specific challenges posed by Complex Table QA. In this paper, we propose to incorporate GPT-3.5 to address such challenges, in which complex tables are reconstructed into tuples and specific prompt designs are employed for dialogues. Specifically, we encode each cell's hierarchical structure, position information, and content as a tuple. By enhancing the prompt template with an explanatory description of the meaning of each tuple and the logical reasoning process of the task, we effectively improve the hierarchical structure awareness capability of GPT-3.5 to better parse the complex tables. Extensive experiments and results on Complex Table QA datasets, i.e., the open-domain dataset HiTAB and the aviation domain dataset AIT-QA show that our approach significantly outperforms previous work on both datasets, leading to state-of-the-art (SOTA) performance.
Neural Impostor: Editing Neural Radiance Fields with Explicit Shape Manipulation
Oct 09, 2023Neural Radiance Fields (NeRF) have significantly advanced the generation of highly realistic and expressive 3D scenes. However, the task of editing NeRF, particularly in terms of geometry modification, poses a significant challenge. This issue has obstructed NeRF's wider adoption across various applications. To tackle the problem of efficiently editing neural implicit fields, we introduce Neural Impostor, a hybrid representation incorporating an explicit tetrahedral mesh alongside a multigrid implicit field designated for each tetrahedron within the explicit mesh. Our framework bridges the explicit shape manipulation and the geometric editing of implicit fields by utilizing multigrid barycentric coordinate encoding, thus offering a pragmatic solution to deform, composite, and generate neural implicit fields while maintaining a complex volumetric appearance. Furthermore, we propose a comprehensive pipeline for editing neural implicit fields based on a set of explicit geometric editing operations. We show the robustness and adaptability of our system through diverse examples and experiments, including the editing of both synthetic objects and real captured data. Finally, we demonstrate the authoring process of a hybrid synthetic-captured object utilizing a variety of editing operations, underlining the transformative potential of Neural Impostor in the field of 3D content creation and manipulation.
CEC: Crowdsourcing-based Evolutionary Computation for Distributed Optimization
Apr 12, 2023Crowdsourcing is an emerging computing paradigm that takes advantage of the intelligence of a crowd to solve complex problems effectively. Besides collecting and processing data, it is also a great demand for the crowd to conduct optimization. Inspired by this, this paper intends to introduce crowdsourcing into evolutionary computation (EC) to propose a crowdsourcing-based evolutionary computation (CEC) paradigm for distributed optimization. EC is helpful for optimization tasks of crowdsourcing and in turn, crowdsourcing can break the spatial limitation of EC for large-scale distributed optimization. Therefore, this paper firstly introduces the paradigm of crowdsourcing-based distributed optimization. Then, CEC is elaborated. CEC performs optimization based on a server and a group of workers, in which the server dispatches a large task to workers. Workers search for promising solutions through EC optimizers and cooperate with connected neighbors. To eliminate uncertainties brought by the heterogeneity of worker behaviors and devices, the server adopts the competitive ranking and uncertainty detection strategy to guide the cooperation of workers. To illustrate the satisfactory performance of CEC, a crowdsourcing-based swarm optimizer is implemented as an example for extensive experiments. Comparison results on benchmark functions and a distributed clustering optimization problem demonstrate the potential applications of CEC.