 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Neural Architecture Search with Dual Contrastive Learning
Dec 23, 2025Evolutionary Neural Architecture Search (ENAS) has gained attention for automatically designing neural network architectures. Recent studies use a neural predictor to guide the process, but the high computational costs of gathering training data -- since each label requires fully training an architecture -- make achieving a high-precision predictor with { limited compute budget (i.e., a capped number of fully trained architecture-label pairs)} crucial for ENAS success. This paper introduces ENAS with Dual Contrastive Learning (DCL-ENAS), a novel method that employs two stages of contrastive learning to train the neural predictor. In the first stage, contrastive self-supervised learning is used to learn meaningful representations from neural architectures without requiring labels. In the second stage, fine-tuning with contrastive learning is performed to accurately predict the relative performance of different architectures rather than their absolute performance, which is sufficient to guide the evolutionary search. Across NASBench-101 and NASBench-201, DCL-ENAS achieves the highest validation accuracy, surpassing the strongest published baselines by 0.05\% (ImageNet16-120) to 0.39\% (NASBench-101). On a real-world ECG arrhythmia classification task, DCL-ENAS improves performance by approximately 2.5 percentage points over a manually designed, non-NAS model obtained via random search, while requiring only 7.7 GPU-days.
DesignX: Human-Competitive Algorithm Designer for Black-Box Optimization
May 23, 2025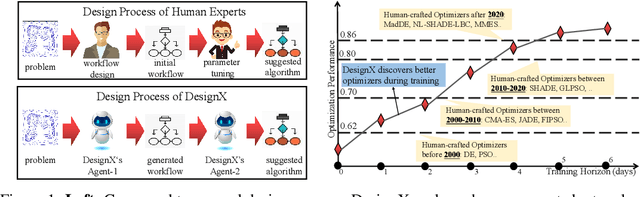
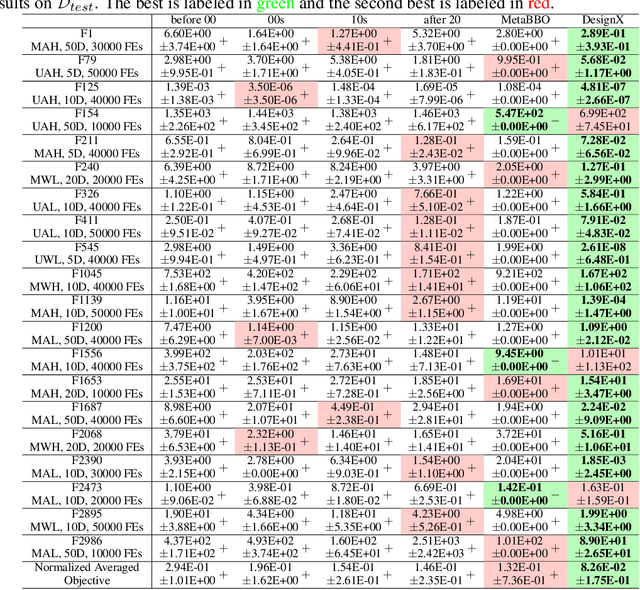
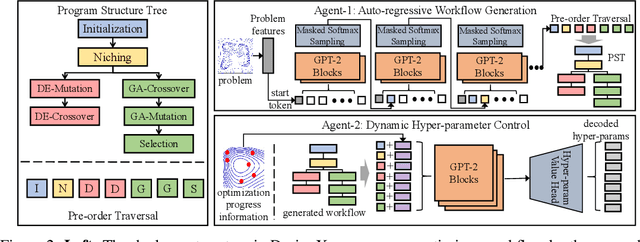
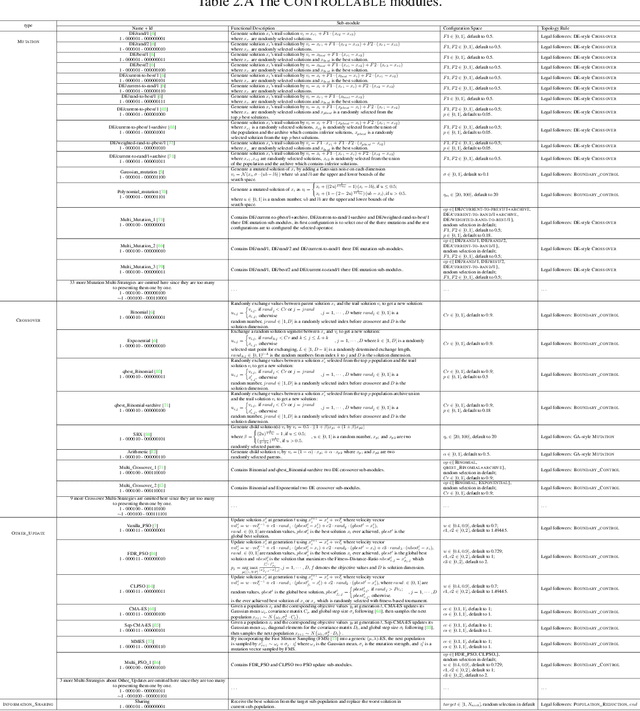
Designing effective black-box optimizers is hampered by limited problem-specific knowledge and manual control that spans months for almost every detail. In this paper, we present DesignX, the first automated algorithm design framework that generates an effective optimizer specific to a given black-box optimization problem within seconds. Rooted in the first principles, we identify two key sub-tasks: 1) algorithm structure generation and 2) hyperparameter control. To enable systematic construction, a comprehensive modular algorithmic space is first built, embracing hundreds of algorithm components collected from decades of research. We then introduce a dual-agent reinforcement learning system that collaborates on structural and parametric design through a novel cooperative training objective, enabling large-scale meta-training across 10k diverse instances. Remarkably, through days of autonomous learning, the DesignX-generated optimizers continuously surpass human-crafted optimizers by orders of magnitude, either on synthetic testbed or on realistic optimization scenarios such as Protein-docking, AutoML and UAV path planning. Further in-depth analysis reveals DesignX's capability to discover non-trivial algorithm patterns beyond expert intuition, which, conversely, provides valuable design insights for the optimization community. We provide DesignX's inference code at https://github.com/MetaEvo/DesignX.
Emergent Crowd Grouping via Heuristic Self-Organization
Jun 30, 2024Modeling crowds has many important applications in games and computer animation. Inspired by the emergent following effect in real-life crowd scenarios, in this work, we develop a method for implicitly grouping moving agents. We achieve this by analyzing local information around each agent and rotating its preferred velocity accordingly. Each agent could automatically form an implicit group with its neighboring agents that have similar directions. In contrast to an explicit group, there are no strict boundaries for an implicit group. If an agent's direction deviates from its group as a result of positional changes, it will autonomously exit the group or join another implicitly formed neighboring group. This implicit grouping is autonomously emergent among agents rather than deliberately controlled by the algorithm. The proposed method is compared with many crowd simulation models, and the experimental results indicate that our approach achieves the lowest congestion levels in some classic scenarios. In addition, we demonstrate that adjusting the preferred velocity of agents can actually reduce the dissimilarity between their actual velocity and the original preferred velocity. Our work is available online.
Distance-aware Attention Reshaping: Enhance Generalization of Neural Solver for Large-scale Vehicle Routing Problems
Jan 13, 2024Neural solvers based on attention mechanism have demonstrated remarkable effectiveness in solving vehicle routing problems. However, in the generalization process from small scale to large scale, we find a phenomenon of the dispersion of attention scores in existing neural solvers, which leads to poor performance. To address this issue, this paper proposes a distance-aware attention reshaping method, assisting neural solvers in solving large-scale vehicle routing problems. Specifically, without the need for additional training, we utilize the Euclidean distance information between current nodes to adjust attention scores. This enables a neural solver trained on small-scale instances to make rational choices when solving a large-scale problem. Experimental results show that the proposed method significantly outperforms existing state-of-the-art neural solvers on the large-scale CVRPLib dataset.
A Survey on Distributed Evolutionary Computation
Apr 12, 2023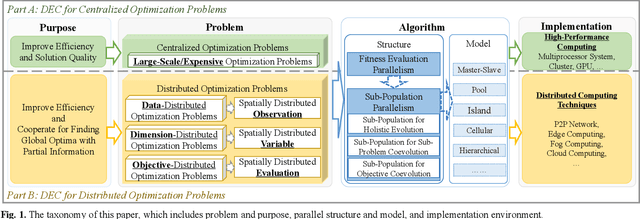
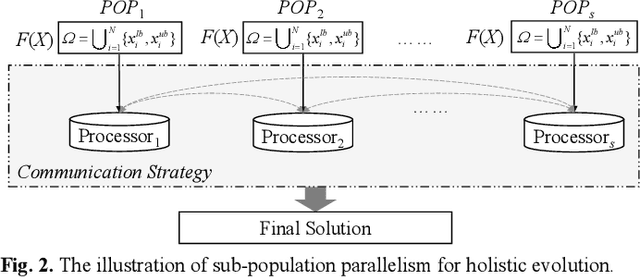
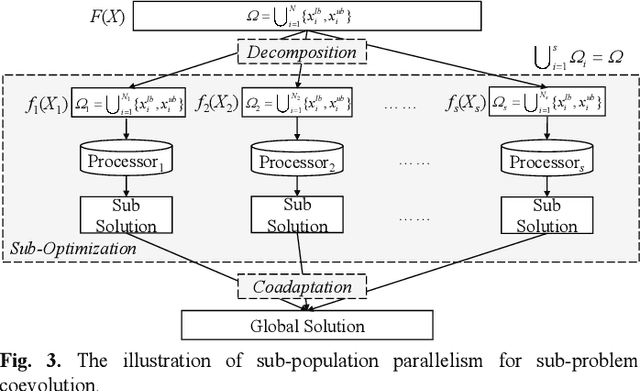
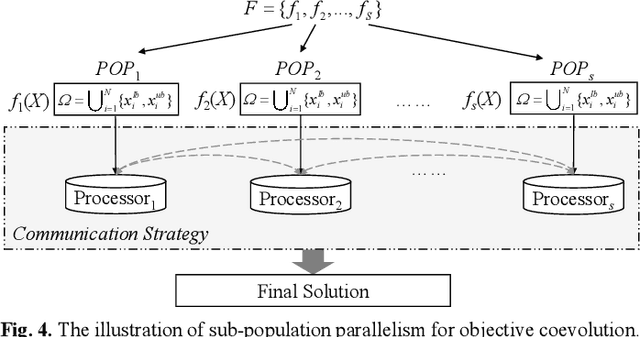
The rapid development of parallel and distributed computing paradigms has brought about great revolution in computing. Thanks to the intrinsic parallelism of evolutionary computation (EC), it is natural to implement EC on parallel and distributed computing systems. On the one hand, the computing power provided by parallel computing systems can significantly improve the efficiency and scalability of EC. On the other hand, data are collected and processed in a distributed manner, which brings a novel development direction and new challenges to EC. In this paper, we intend to give a systematic review on distributed EC (DEC). First, a new taxonomy for DEC is proposed from top design mechanism to bottom implementation mechanism. Based on this taxonomy, existing studies on DEC are reviewed in terms of purpose, parallel structure of the algorithm, parallel model for implementation, and the implementation environment. Second, we clarify two major purposes of DEC, i.e., improving efficiency through parallel processing for centralized optimization and cooperating distributed individuals/sub-populations with partial information to perform distributed optimization. Third, noting that the latter purpose of DEC is an emerging and attractive trend for EC with the booming of spatially distributed paradigms, this paper gives a systematic definition of the distributed optimization and classifies it into dimension distributed-, data distributed-, and objective distributed-optimization problems. Formal formulations for these problems are provided and various DEC studies on these problems are reviewed. We also discuss challenges and potential research directions, aiming to enlighten the design of DEC and pave the way for future developments.
CEC: Crowdsourcing-based Evolutionary Computation for Distributed Optimization
Apr 12, 2023Crowdsourcing is an emerging computing paradigm that takes advantage of the intelligence of a crowd to solve complex problems effectively. Besides collecting and processing data, it is also a great demand for the crowd to conduct optimization. Inspired by this, this paper intends to introduce crowdsourcing into evolutionary computation (EC) to propose a crowdsourcing-based evolutionary computation (CEC) paradigm for distributed optimization. EC is helpful for optimization tasks of crowdsourcing and in turn, crowdsourcing can break the spatial limitation of EC for large-scale distributed optimization. Therefore, this paper firstly introduces the paradigm of crowdsourcing-based distributed optimization. Then, CEC is elaborated. CEC performs optimization based on a server and a group of workers, in which the server dispatches a large task to workers. Workers search for promising solutions through EC optimizers and cooperate with connected neighbors. To eliminate uncertainties brought by the heterogeneity of worker behaviors and devices, the server adopts the competitive ranking and uncertainty detection strategy to guide the cooperation of workers. To illustrate the satisfactory performance of CEC, a crowdsourcing-based swarm optimizer is implemented as an example for extensive experiments. Comparison results on benchmark functions and a distributed clustering optimization problem demonstrate the potential applications of CEC.
When Evolutionary Computation Meets Privacy
Mar 22, 2023



Recently, evolutionary computation (EC) has been promoted by machine learning, distributed computing, and big data technologies, resulting in new research directions of EC like distributed EC and surrogate-assisted EC. These advances have significantly improved the performance and the application scope of EC, but also trigger privacy leakages, such as the leakage of optimal results and surrogate model. Accordingly, evolutionary computation combined with privacy protection is becoming an emerging topic. However, privacy concerns in evolutionary computation lack a systematic exploration, especially for the object, motivation, position, and method of privacy protection. To this end, in this paper, we discuss three typical optimization paradigms (i.e., \textit{centralized optimization, distributed optimization, and data-driven optimization}) to characterize optimization modes of evolutionary computation and propose BOOM to sort out privacy concerns in evolutionary computation. Specifically, the centralized optimization paradigm allows clients to outsource optimization problems to the centralized server and obtain optimization solutions from the server. While the distributed optimization paradigm exploits the storage and computational power of distributed devices to solve optimization problems. Also, the data-driven optimization paradigm utilizes data collected in history to tackle optimization problems lacking explicit objective functions. Particularly, this paper adopts BOOM to characterize the object and motivation of privacy protection in three typical optimization paradigms and discusses potential privacy-preserving technologies balancing optimization performance and privacy guarantees in three typical optimization paradigms. Furthermore, this paper attempts to foresee some new research directions of privacy-preserving evolutionary computation.
Evolution as a Service: A Privacy-Preserving Genetic Algorithm for Combinatorial Optimization
May 27, 2022
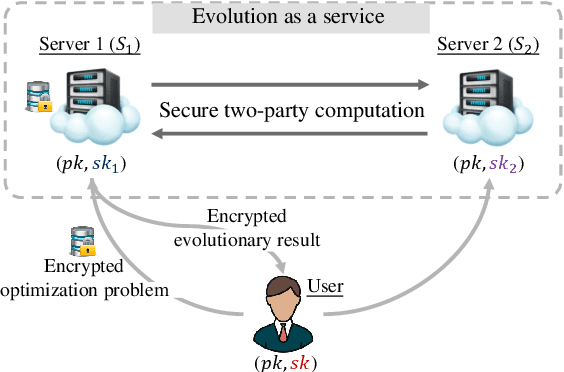
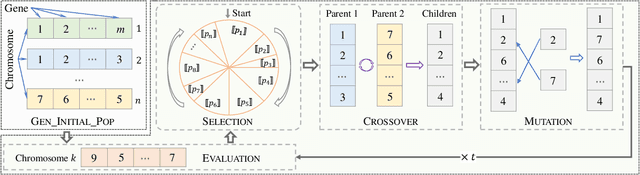
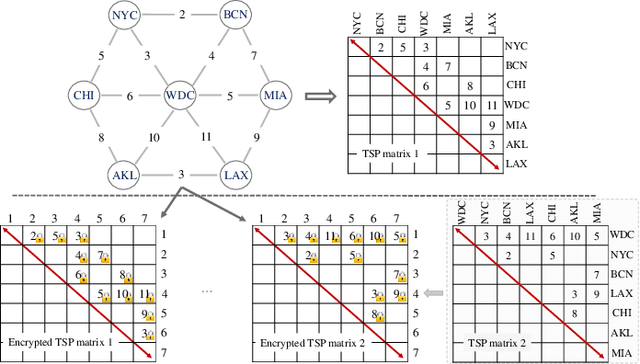
Evolutionary algorithms (EAs), such as the genetic algorithm (GA), offer an elegant way to handle combinatorial optimization problems (COPs). However, limited by expertise and resources, most users do not have enough capability to implement EAs to solve COPs. An intuitive and promising solution is to outsource evolutionary operations to a cloud server, whilst it suffers from privacy concerns. To this end, this paper proposes a novel computing paradigm, evolution as a service (EaaS), where a cloud server renders evolutionary computation services for users without sacrificing users' privacy. Inspired by the idea of EaaS, this paper designs PEGA, a novel privacy-preserving GA for COPs. Specifically, PEGA enables users outsourcing COPs to the cloud server holding a competitive GA and approximating the optimal solution in a privacy-preserving manner. PEGA features the following characteristics. First, any user without expertise and enough resources can solve her COPs. Second, PEGA does not leak contents of optimization problems, i.e., users' privacy. Third, PEGA has the same capability as the conventional GA to approximate the optimal solution. We implements PEGA falling in a twin-server architecture and evaluates it in the traveling salesman problem (TSP, a widely known COP). Particularly, we utilize encryption cryptography to protect users' privacy and carefully design a suit of secure computing protocols to support evolutionary operators of GA on encrypted data. Privacy analysis demonstrates that PEGA does not disclose the contents of the COP to the cloud server. Experimental evaluation results on four TSP datasets show that PEGA is as effective as the conventional GA in approximating the optimal solution.