 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-guided Prioritized Planning for Lifelong Multi-Agent Path Finding in Warehouse Automation
Mar 25, 2026Lifelong Multi-Agent Path Finding (MAPF) is critical for modern warehouse automation, which requires multiple robots to continuously navigate conflict-free paths to optimize the overall system throughput. However, the complexity of warehouse environments and the long-term dynamics of lifelong MAPF often demand costly adaptations to classical search-based solvers. While machine learning methods have been explored, their superiority over search-based methods remains inconclusive. In this paper, we introduce Reinforcement Learning (RL) guided Rolling Horizon Prioritized Planning (RL-RH-PP), the first framework integrating RL with search-based planning for lifelong MAPF. Specifically, we leverage classical Prioritized Planning (PP) as a backbone for its simplicity and flexibility in integrating with a learning-based priority assignment policy. By formulating dynamic priority assignment as a Partially Observable Markov Decision Process (POMDP), RL-RH-PP exploits the sequential decision-making nature of lifelong planning while delegating complex spatial-temporal interactions among agents to reinforcement learning. An attention-based neural network autoregressively decodes priority orders on-the-fly, enabling efficient sequential single-agent planning by the PP planner. Evaluations in realistic warehouse simulations show that RL-RH-PP achieves the highest total throughput among baselines and generalizes effectively across agent densities, planning horizons, and warehouse layouts. Our interpretive analyses reveal that RL-RH-PP proactively prioritizes congested agents and strategically redirects agents from congestion, easing traffic flow and boosting throughput. These findings highlight the potential of learning-guided approaches to augment traditional heuristics in modern warehouse automation.
RADAR: Learning to Route with Asymmetry-aware DistAnce Representations
Mar 05, 2026Recent neural solvers have achieved strong performance on vehicle routing problems (VRPs), yet they mainly assume symmetric Euclidean distances, restricting applicability to real-world scenarios. A core challenge is encoding the relational features in asymmetric distance matrices of VRPs. Early attempts directly encoded these matrices but often failed to produce compact embeddings and generalized poorly at scale. In this paper, we propose RADAR, a scalable neural framework that augments existing neural VRP solvers with the ability to handle asymmetric inputs. RADAR addresses asymmetry from both static and dynamic perspectives. It leverages Singular Value Decomposition (SVD) on the asymmetric distance matrix to initialize compact and generalizable embeddings that inherently encode the static asymmetry in the inbound and outbound costs of each node. To further model dynamic asymmetry in embedding interactions during encoding, it replaces the standard softmax with Sinkhorn normalization that imposes joint row and column distance awareness in attention weights. Extensive experiments on synthetic and real-world benchmarks across various VRPs show that RADAR outperforms strong baselines on both in-distribution and out-of-distribution instances, demonstrating robust generalization and superior performance in solving asymmetric VRPs.
Towards Efficient Constraint Handling in Neural Solvers for Routing Problems
Feb 17, 2026Neural solvers have achieved impressive progress in addressing simple routing problems, particularly excelling in computational efficiency. However, their advantages under complex constraints remain nascent, for which current constraint-handling schemes via feasibility masking or implicit feasibility awareness can be inefficient or inapplicable for hard constraints. In this paper, we present Construct-and-Refine (CaR), the first general and efficient constraint-handling framework for neural routing solvers based on explicit learning-based feasibility refinement. Unlike prior construction-search hybrids that target reducing optimality gaps through heavy improvements yet still struggle with hard constraints, CaR achieves efficient constraint handling by designing a joint training framework that guides the construction module to generate diverse and high-quality solutions well-suited for a lightweight improvement process, e.g., 10 steps versus 5k steps in prior work. Moreover, CaR presents the first use of construction-improvement-shared representation, enabling potential knowledge sharing across paradigms by unifying the encoder, especially in more complex constrained scenarios. We evaluate CaR on typical hard routing constraints to showcase its broader applicability. Results demonstrate that CaR achieves superior feasibility, solution quality, and efficiency compared to both classical and neural state-of-the-art solvers.
A General Neural Backbone for Mixed-Integer Linear Optimization via Dual Attention
Jan 08, 2026Mixed-integer linear programming (MILP), a widely used modeling framework for combinatorial optimization, are central to many scientific and engineering applications, yet remains computationally challenging at scale. Recent advances in deep learning address this challenge by representing MILP instances as variable-constraint bipartite graphs and applying graph neural networks (GNNs) to extract latent structural patterns and enhance solver efficiency. However, this architecture is inherently limited by the local-oriented mechanism, leading to restricted representation power and hindering neural approaches for MILP. Here we present an attention-driven neural architecture that learns expressive representations beyond the pure graph view. A dual-attention mechanism is designed to perform parallel self- and cross-attention over variables and constraints, enabling global information exchange and deeper representation learning. We apply this general backbone to various downstream tasks at the instance level, element level, and solving state level. Extensive experiments across widely used benchmarks show consistent improvements of our approach over state-of-the-art baselines, highlighting attention-based neural architectures as a powerful foundation for learning-enhanced mixed-integer linear optimization.
SHIELD: Multi-task Multi-distribution Vehicle Routing Solver with Sparsity and Hierarchy
Jun 11, 2025Recent advances toward foundation models for routing problems have shown great potential of a unified deep model for various VRP variants. However, they overlook the complex real-world customer distributions. In this work, we advance the Multi-Task VRP (MTVRP) setting to the more realistic yet challenging Multi-Task Multi-Distribution VRP (MTMDVRP) setting, and introduce SHIELD, a novel model that leverages both sparsity and hierarchy principles. Building on a deeper decoder architecture, we first incorporate the Mixture-of-Depths (MoD) technique to enforce sparsity. This improves both efficiency and generalization by allowing the model to dynamically select nodes to use or skip each decoder layer, providing the needed capacity to adaptively allocate computation for learning the task/distribution specific and shared representations. We also develop a context-based clustering layer that exploits the presence of hierarchical structures in the problems to produce better local representations. These two designs inductively bias the network to identify key features that are common across tasks and distributions, leading to significantly improved generalization on unseen ones. Our empirical results demonstrate the superiority of our approach over existing methods on 9 real-world maps with 16 VRP variants each.
DesignX: Human-Competitive Algorithm Designer for Black-Box Optimization
May 23, 2025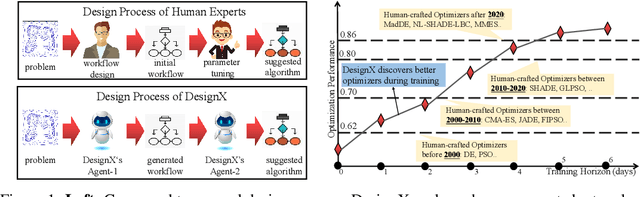
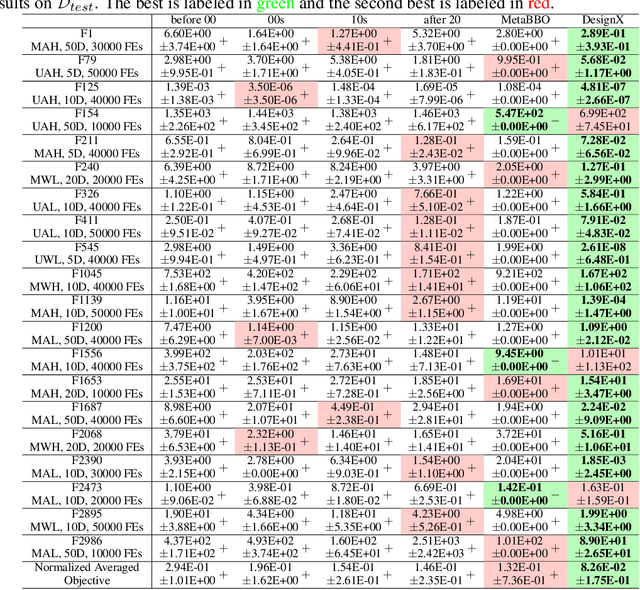
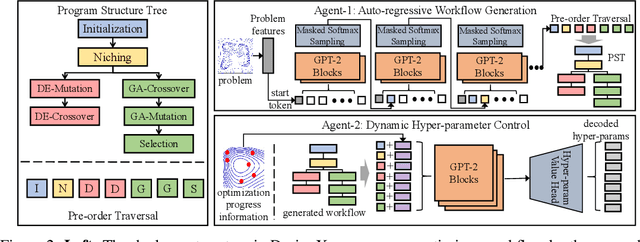
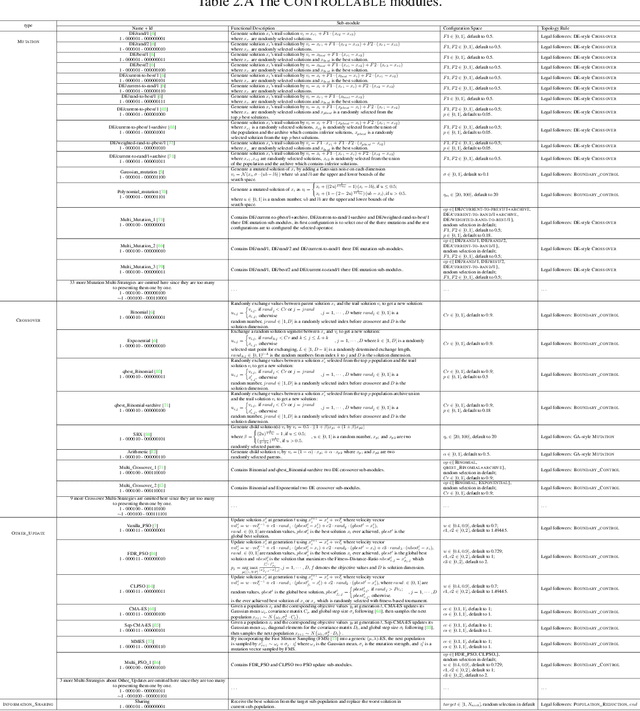
Designing effective black-box optimizers is hampered by limited problem-specific knowledge and manual control that spans months for almost every detail. In this paper, we present DesignX, the first automated algorithm design framework that generates an effective optimizer specific to a given black-box optimization problem within seconds. Rooted in the first principles, we identify two key sub-tasks: 1) algorithm structure generation and 2) hyperparameter control. To enable systematic construction, a comprehensive modular algorithmic space is first built, embracing hundreds of algorithm components collected from decades of research. We then introduce a dual-agent reinforcement learning system that collaborates on structural and parametric design through a novel cooperative training objective, enabling large-scale meta-training across 10k diverse instances. Remarkably, through days of autonomous learning, the DesignX-generated optimizers continuously surpass human-crafted optimizers by orders of magnitude, either on synthetic testbed or on realistic optimization scenarios such as Protein-docking, AutoML and UAV path planning. Further in-depth analysis reveals DesignX's capability to discover non-trivial algorithm patterns beyond expert intuition, which, conversely, provides valuable design insights for the optimization community. We provide DesignX's inference code at https://github.com/MetaEvo/DesignX.
MetaBox-v2: A Unified Benchmark Platform for Meta-Black-Box Optimization
May 23, 2025
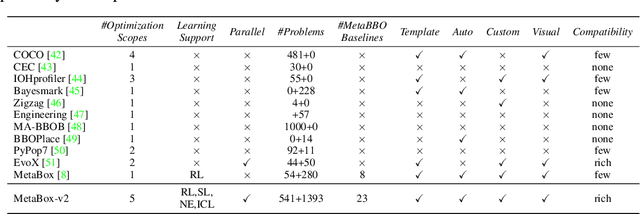
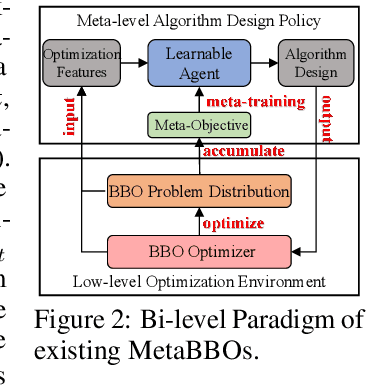
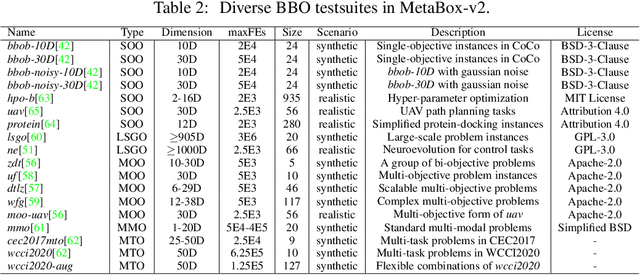
Meta-Black-Box Optimization (MetaBBO) streamlines the automation of optimization algorithm design through meta-learning. It typically employs a bi-level structure: the meta-level policy undergoes meta-training to reduce the manual effort required in developing algorithms for low-level optimization tasks. The original MetaBox (2023) provided the first open-source framework for reinforcement learning-based single-objective MetaBBO. However, its relatively narrow scope no longer keep pace with the swift advancement in this field. In this paper, we introduce MetaBox-v2 (https://github.com/MetaEvo/MetaBox) as a milestone upgrade with four novel features: 1) a unified architecture supporting RL, evolutionary, and gradient-based approaches, by which we reproduce 23 up-to-date baselines; 2) efficient parallelization schemes, which reduce the training/testing time by 10-40x; 3) a comprehensive benchmark suite of 18 synthetic/realistic tasks (1900+ instances) spanning single-objective, multi-objective, multi-model, and multi-task optimization scenarios; 4) plentiful and extensible interfaces for custom analysis/visualization and integrating to external optimization tools/benchmarks. To show the utility of MetaBox-v2, we carry out a systematic case study that evaluates the built-in baselines in terms of the optimization performance, generalization ability and learning efficiency. Valuable insights are concluded from thorough and detailed analysis for practitioners and those new to the field.
Real-world Troublemaker: A 5G Cloud-controlled Track Testing Framework for Automated Driving Systems in Safety-critical Interaction Scenarios
Feb 23, 2025Track testing plays a critical role in the safety evaluation of autonomous driving systems (ADS), as it provides a real-world interaction environment. However, the inflexibility in motion control of object targets and the absence of intelligent interactive testing methods often result in pre-fixed and limited testing scenarios. To address these limitations, we propose a novel 5G cloud-controlled track testing framework, Real-world Troublemaker. This framework overcomes the rigidity of traditional pre-programmed control by leveraging 5G cloud-controlled object targets integrated with the Internet of Things (IoT) and vehicle teleoperation technologies. Unlike conventional testing methods that rely on pre-set conditions, we propose a dynamic game strategy based on a quadratic risk interaction utility function, facilitating intelligent interactions with the vehicle under test (VUT) and creating a more realistic and dynamic interaction environment. The proposed framework has been successfully implemented at the Tongji University Intelligent Connected Vehicle Evaluation Base. Field test results demonstrate that Troublemaker can perform dynamic interactive testing of ADS accurately and effectively. Compared to traditional methods, Troublemaker improves scenario reproduction accuracy by 65.2\%, increases the diversity of interaction strategies by approximately 9.2 times, and enhances exposure frequency of safety-critical scenarios by 3.5 times in unprotected left-turn scenarios.
Learning-Guided Rolling Horizon Optimization for Long-Horizon Flexible Job-Shop Scheduling
Feb 18, 2025

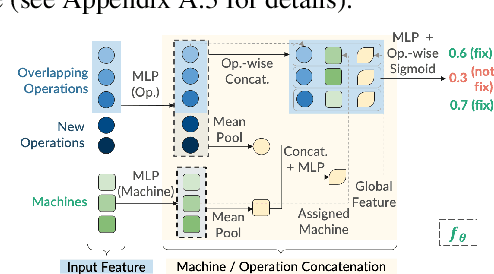
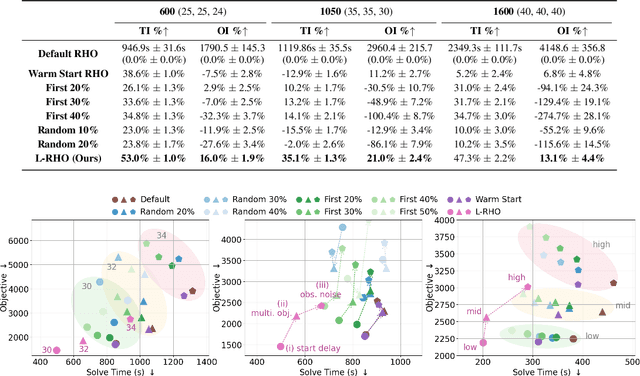
Long-horizon combinatorial optimization problems (COPs), such as the Flexible Job-Shop Scheduling Problem (FJSP), often involve complex, interdependent decisions over extended time frames, posing significant challenges for existing solvers. While Rolling Horizon Optimization (RHO) addresses this by decomposing problems into overlapping shorter-horizon subproblems, such overlap often involves redundant computations. In this paper, we present L-RHO, the first learning-guided RHO framework for COPs. L-RHO employs a neural network to intelligently fix variables that in hindsight did not need to be re-optimized, resulting in smaller and thus easier-to-solve subproblems. For FJSP, this means identifying operations with unchanged machine assignments between consecutive subproblems. Applied to FJSP, L-RHO accelerates RHO by up to 54% while significantly improving solution quality, outperforming other heuristic and learning-based baselines. We also provide in-depth discussions and verify the desirable adaptability and generalization of L-RHO across numerous FJSP variates, distributions, online scenarios and benchmark instances. Moreover, we provide a theoretical analysis to elucidate the conditions under which learning is beneficial.
Diversity Optimization for Travelling Salesman Problem via Deep Reinforcement Learning
Jan 01, 2025Existing neural methods for the Travelling Salesman Problem (TSP) mostly aim at finding a single optimal solution. To discover diverse yet high-quality solutions for Multi-Solution TSP (MSTSP), we propose a novel deep reinforcement learning based neural solver, which is primarily featured by an encoder-decoder structured policy. Concretely, on the one hand, a Relativization Filter (RF) is designed to enhance the robustness of the encoder to affine transformations of the instances, so as to potentially improve the quality of the found solutions. On the other hand, a Multi-Attentive Adaptive Active Search (MA3S) is tailored to allow the decoders to strike a balance between the optimality and diversity. Experimental evaluations on benchmark instances demonstrate the superiority of our method over recent neural baselines across different metrics, and its competitive performance against state-of-the-art traditional heuristics with significantly reduced computational time, ranging from $1.3\times$ to $15\times$ faster. Furthermore, we demonstrate that our method can also be applied to the Capacitated Vehicle Routing Problem (CVRP).