 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurrogate Ensemble in Expensive Multi-Objective Optimization via Deep Q-Learning
Jan 31, 2026Surrogate-assisted Evolutionary Algorithms~(SAEAs) have shown promising robustness in solving expensive optimization problems. A key aspect that impacts SAEAs' effectiveness is surrogate model selection, which in existing works is predominantly decided by human developer. Such human-made design choice introduces strong bias into SAEAs and may hurt their expected performance on out-of-scope tasks. In this paper, we propose a reinforcement learning-assisted ensemble framework, termed as SEEMOO, which is capable of scheduling different surrogate models within a single optimization process, hence boosting the overall optimization performance in a cooperative paradigm. Specifically, we focus on expensive multi-objective optimization problems, where multiple objective functions shape a compositional landscape and hence challenge surrogate selection. SEEMOO comprises following core designs: 1) A pre-collected model pool that maintains different surrogate models; 2) An attention-based state-extractor supports universal optimization state representation of problems with varied objective numbers; 3) a deep Q-network serves as dynamic surrogate selector: Given the optimization state, it selects desired surrogate model for current-step evaluation. SEEMOO is trained to maximize the overall optimization performance under a training problem distribution. Extensive benchmark results demonstrate SEEMOO's surrogate ensemble paradigm boosts the optimization performance of single-surrogate baselines. Further ablation studies underscore the importance of SEEMOO's design components.
Reinforcement Learning-assisted Constraint Relaxation for Constrained Expensive Optimization
Jan 31, 2026Constraint handling plays a key role in solving realistic complex optimization problems. Though intensively discussed in the last few decades, existing constraint handling techniques predominantly rely on human experts' designs, which more or less fall short in utility towards general cases. Motivated by recent progress in Meta-Black-Box Optimization where automated algorithm design can be learned to boost optimization performance, in this paper, we propose learning effective, adaptive and generalizable constraint handling policy through reinforcement learning. Specifically, a tailored Markov Decision Process is first formulated, where given optimization dynamics features, a deep Q-network-based policy controls the constraint relaxation level along the underlying optimization process. Such adaptive constraint handling provides flexible tradeoff between objective-oriented exploitation and feasible-region-oriented exploration, and hence leads to promising optimization performance. We train our approach on CEC 2017 Constrained Optimization benchmark with limited evaluation budget condition (expensive cases) and compare the trained constraint handling policy to strong baselines such as recent winners in CEC/GECCO competitions. Extensive experimental results show that our approach performs competitively or even surpasses the compared baselines under either Leave-one-out cross-validation or ordinary train-test split validation. Further analysis and ablation studies reveal key insights in our designs.
Detect and Act: Automated Dynamic Optimizer through Meta-Black-Box Optimization
Jan 30, 2026Dynamic Optimization Problems (DOPs) are challenging to address due to their complex nature, i.e., dynamic environment variation. Evolutionary Computation methods are generally advantaged in solving DOPs since they resemble dynamic biological evolution. However, existing evolutionary dynamic optimization methods rely heavily on human-crafted adaptive strategy to detect environment variation in DOPs, and then adapt the searching strategy accordingly. These hand-crafted strategies may perform ineffectively at out-of-box scenarios. In this paper, we propose a reinforcement learning-assisted approach to enable automated variation detection and self-adaption in evolutionary algorithms. This is achieved by borrowing the bi-level learning-to-optimize idea from recent Meta-Black-Box Optimization works. We use a deep Q-network as optimization dynamics detector and searching strategy adapter: It is fed as input with current-step optimization state and then dictates desired control parameters to underlying evolutionary algorithms for next-step optimization. The learning objective is to maximize the expected performance gain across a problem distribution. Once trained, our approach could generalize toward unseen DOPs with automated environment variation detection and self-adaption. To facilitate comprehensive validation, we further construct an easy-to-difficult DOPs testbed with diverse synthetic instances. Extensive benchmark results demonstrate flexible searching behavior and superior performance of our approach in solving DOPs, compared to state-of-the-art baselines.
COBRA++: Enhanced COBRA Optimizer with Augmented Surrogate Pool and Reinforced Surrogate Selection
Jan 30, 2026The optimization problems in realistic world present significant challenges onto optimization algorithms, such as the expensive evaluation issue and complex constraint conditions. COBRA optimizer (including its up-to-date variants) is a representative and effective tool for addressing such optimization problems, which introduces 1) RBF surrogate to reduce online evaluation and 2) bi-stage optimization process to alternate search for feasible solution and optimal solution. Though promising, its design space, i.e., surrogate model pool and selection standard, is still manually decided by human expert, resulting in labor-intensive fine-tuning for novel tasks. In this paper, we propose a learning-based adaptive strategy (COBRA++) that enhances COBRA in two aspects: 1) An augmented surrogate pool to break the tie with RBF-like surrogate and hence enhances model diversity and approximation capability; 2) A reinforcement learning-based online model selection policy that empowers efficient and accurate optimization process. The model selection policy is trained to maximize overall performance of COBRA++ across a distribution of constrained optimization problems with diverse properties. We have conducted multi-dimensional validation experiments and demonstrate that COBRA++ achieves substantial performance improvement against vanilla COBRA and its adaptive variant. Ablation studies are provided to support correctness of each design component in COBRA++.
READY: Reward Discovery for Meta-Black-Box Optimization
Jan 29, 2026Meta-Black-Box Optimization (MetaBBO) is an emerging avenue within Optimization community, where algorithm design policy could be meta-learned by reinforcement learning to enhance optimization performance. So far, the reward functions in existing MetaBBO works are designed by human experts, introducing certain design bias and risks of reward hacking. In this paper, we use Large Language Model~(LLM) as an automated reward discovery tool for MetaBBO. Specifically, we consider both effectiveness and efficiency sides. On effectiveness side, we borrow the idea of evolution of heuristics, introducing tailored evolution paradigm in the iterative LLM-based program search process, which ensures continuous improvement. On efficiency side, we additionally introduce multi-task evolution architecture to support parallel reward discovery for diverse MetaBBO approaches. Such parallel process also benefits from knowledge sharing across tasks to accelerate convergence. Empirical results demonstrate that the reward functions discovered by our approach could be helpful for boosting existing MetaBBO works, underscoring the importance of reward design in MetaBBO. We provide READY's project at https://anonymous.4open.science/r/ICML_READY-747F.
Evolution of Benchmark: Black-Box Optimization Benchmark Design through Large Language Model
Jan 29, 2026Benchmark Design in Black-Box Optimization (BBO) is a fundamental yet open-ended topic. Early BBO benchmarks are predominantly human-crafted, introducing expert bias and constraining diversity. Automating this design process can relieve the human-in-the-loop burden while enhancing diversity and objectivity. We propose Evolution of Benchmark (EoB), an automated BBO benchmark designer empowered by the large language model (LLM) and its program evolution capability. Specifically, we formulate benchmark design as a bi-objective optimization problem towards maximizing (i) landscape diversity and (ii) algorithm-differentiation ability across a portfolio of BBO solvers. Under this paradigm, EoB iteratively prompts LLM to evolve a population of benchmark programs and employs a reflection-based scheme to co-evolve the landscape and its corresponding program. Comprehensive experiments validate our EoB is a competitive candidate in multi-dimensional usages: 1) Benchmarking BBO algorithms; 2) Training and testing learning-assisted BBO algorithms; 3) Extending proxy for expensive real-world problems.
Offline Multi-Task Multi-Objective Data-Driven Evolutionary Algorithm with Language Surrogate Model and Implicit Q-Learning
Dec 17, 2025Data-driven evolutionary algorithms has shown surprising results in addressing expensive optimization problems through robust surrogate modeling. Though promising, existing surrogate modeling schemes may encounter limitations in complex optimization problems with many sub-objectives, which rely on repeated and tedious approximation. To address such technical gap, we propose Q-MetaSur as a plug-and-play surrogate modeling scheme capable of providing unified and generalized surrogate learning. Specifically, we consider multi-task-multi-objective optimization~(MTMOO) in offline setting. Several key designs are proposed: 1) we transform objective approximation into sequence-to-sequence modeling where MTMOO problem can be represented by tenxual tokenization. To operate under such auto-regressive modeling, we introduce a Large Language Model-based surrogate model that first encodes a MTMOO instance and then decodes objective values of unseen decision variables. To ensure stability in training the proposed model, we propose a two-stage offline training strategy that operates as a synergy of supervised tuning and RL fine-tuning, which first exploits offline dataset to fit existing knowledge and then leverages RL to enhance model's generalization performance. Extensive empirical results on the CEC2019 benchmark demonstrate that Q-MetaSur not only outperforms representative surrogate baselines in objective approximation accuracy, but also helps underlying evolutionary algorithms achieve both desired optimization convergence and improved pareto optimality.
Learning Where, What and How to Transfer: A Multi-Role Reinforcement Learning Approach for Evolutionary Multitasking
Nov 19, 2025Evolutionary multitasking (EMT) algorithms typically require tailored designs for knowledge transfer, in order to assure convergence and optimality in multitask optimization. In this paper, we explore designing a systematic and generalizable knowledge transfer policy through Reinforcement Learning. We first identify three major challenges: determining the task to transfer (where), the knowledge to be transferred (what) and the mechanism for the transfer (how). To address these challenges, we formulate a multi-role RL system where three (groups of) policy networks act as specialized agents: a task routing agent incorporates an attention-based similarity recognition module to determine source-target transfer pairs via attention scores; a knowledge control agent determines the proportion of elite solutions to transfer; and a group of strategy adaptation agents control transfer strength by dynamically controlling hyper-parameters in the underlying EMT framework. Through pre-training all network modules end-to-end over an augmented multitask problem distribution, a generalizable meta-policy is obtained. Comprehensive validation experiments show state-of-the-art performance of our method against representative baselines. Further in-depth analysis not only reveals the rationale behind our proposal but also provide insightful interpretations on what the system have learned.
Instance Generation for Meta-Black-Box Optimization through Latent Space Reverse Engineering
Sep 19, 2025To relieve intensive human-expertise required to design optimization algorithms, recent Meta-Black-Box Optimization (MetaBBO) researches leverage generalization strength of meta-learning to train neural network-based algorithm design policies over a predefined training problem set, which automates the adaptability of the low-level optimizers on unseen problem instances. Currently, a common training problem set choice in existing MetaBBOs is well-known benchmark suites CoCo-BBOB. Although such choice facilitates the MetaBBO's development, problem instances in CoCo-BBOB are more or less limited in diversity, raising the risk of overfitting of MetaBBOs, which might further results in poor generalization. In this paper, we propose an instance generation approach, termed as \textbf{LSRE}, which could generate diverse training problem instances for MetaBBOs to learn more generalizable policies. LSRE first trains an autoencoder which maps high-dimensional problem features into a 2-dimensional latent space. Uniform-grid sampling in this latent space leads to hidden representations of problem instances with sufficient diversity. By leveraging a genetic-programming approach to search function formulas with minimal L2-distance to these hidden representations, LSRE reverse engineers a diversified problem set, termed as \textbf{Diverse-BBO}. We validate the effectiveness of LSRE by training various MetaBBOs on Diverse-BBO and observe their generalization performances on either synthetic or realistic scenarios. Extensive experimental results underscore the superiority of Diverse-BBO to existing training set choices in MetaBBOs. Further ablation studies not only demonstrate the effectiveness of design choices in LSRE, but also reveal interesting insights on instance diversity and MetaBBO's generalization.
MetaBox-v2: A Unified Benchmark Platform for Meta-Black-Box Optimization
May 23, 2025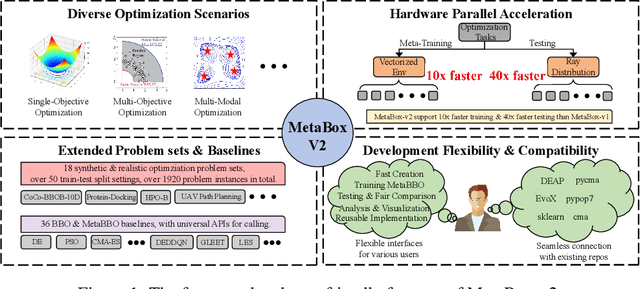
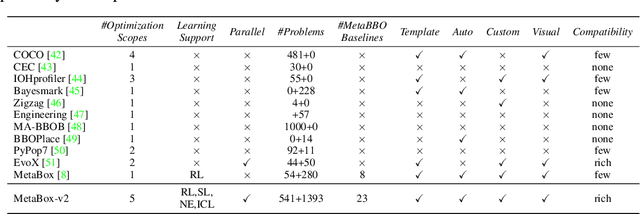
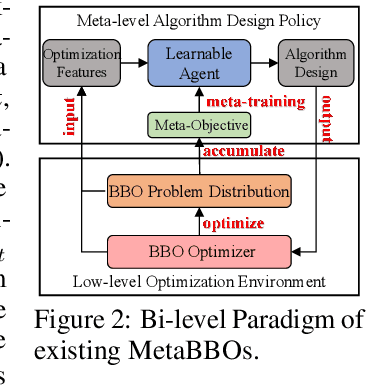
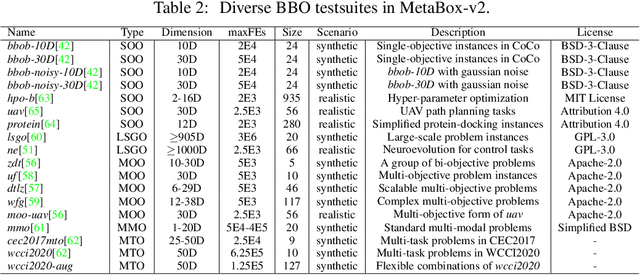
Meta-Black-Box Optimization (MetaBBO) streamlines the automation of optimization algorithm design through meta-learning. It typically employs a bi-level structure: the meta-level policy undergoes meta-training to reduce the manual effort required in developing algorithms for low-level optimization tasks. The original MetaBox (2023) provided the first open-source framework for reinforcement learning-based single-objective MetaBBO. However, its relatively narrow scope no longer keep pace with the swift advancement in this field. In this paper, we introduce MetaBox-v2 (https://github.com/MetaEvo/MetaBox) as a milestone upgrade with four novel features: 1) a unified architecture supporting RL, evolutionary, and gradient-based approaches, by which we reproduce 23 up-to-date baselines; 2) efficient parallelization schemes, which reduce the training/testing time by 10-40x; 3) a comprehensive benchmark suite of 18 synthetic/realistic tasks (1900+ instances) spanning single-objective, multi-objective, multi-model, and multi-task optimization scenarios; 4) plentiful and extensible interfaces for custom analysis/visualization and integrating to external optimization tools/benchmarks. To show the utility of MetaBox-v2, we carry out a systematic case study that evaluates the built-in baselines in terms of the optimization performance, generalization ability and learning efficiency. Valuable insights are concluded from thorough and detailed analysis for practitioners and those new to the field.