 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaBox-v2: A Unified Benchmark Platform for Meta-Black-Box Optimization
May 23, 2025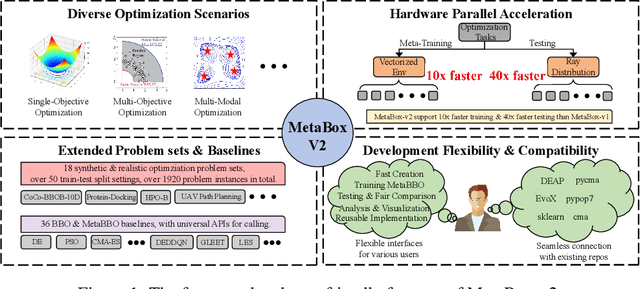
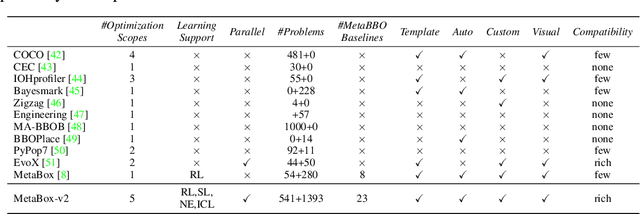
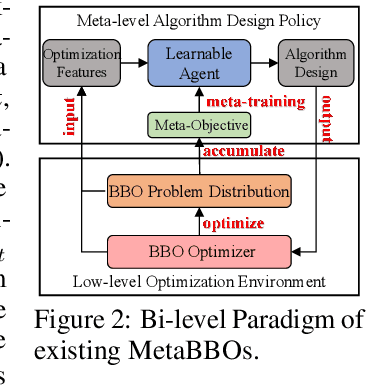
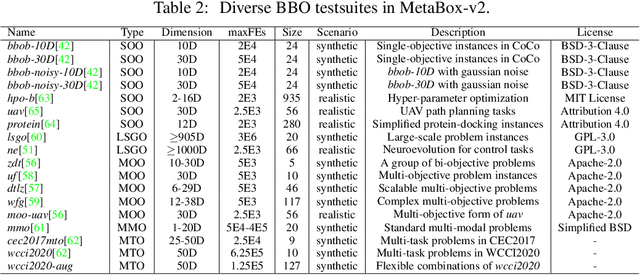
Meta-Black-Box Optimization (MetaBBO) streamlines the automation of optimization algorithm design through meta-learning. It typically employs a bi-level structure: the meta-level policy undergoes meta-training to reduce the manual effort required in developing algorithms for low-level optimization tasks. The original MetaBox (2023) provided the first open-source framework for reinforcement learning-based single-objective MetaBBO. However, its relatively narrow scope no longer keep pace with the swift advancement in this field. In this paper, we introduce MetaBox-v2 (https://github.com/MetaEvo/MetaBox) as a milestone upgrade with four novel features: 1) a unified architecture supporting RL, evolutionary, and gradient-based approaches, by which we reproduce 23 up-to-date baselines; 2) efficient parallelization schemes, which reduce the training/testing time by 10-40x; 3) a comprehensive benchmark suite of 18 synthetic/realistic tasks (1900+ instances) spanning single-objective, multi-objective, multi-model, and multi-task optimization scenarios; 4) plentiful and extensible interfaces for custom analysis/visualization and integrating to external optimization tools/benchmarks. To show the utility of MetaBox-v2, we carry out a systematic case study that evaluates the built-in baselines in terms of the optimization performance, generalization ability and learning efficiency. Valuable insights are concluded from thorough and detailed analysis for practitioners and those new to the field.
$\mathrm{E^{2}CFD}$: Towards Effective and Efficient Cost Function Design for Safe Reinforcement Learning via Large Language Model
Jul 08, 2024Different classes of safe reinforcement learning algorithms have shown satisfactory performance in various types of safety requirement scenarios. However, the existing methods mainly address one or several classes of specific safety requirement scenario problems and cannot be applied to arbitrary safety requirement scenarios. In addition, the optimization objectives of existing reinforcement learning algorithms are misaligned with the task requirements. Based on the need to address these issues, we propose $\mathrm{E^{2}CFD}$, an effective and efficient cost function design framework. $\mathrm{E^{2}CFD}$ leverages the capabilities of a large language model (LLM) to comprehend various safety scenarios and generate corresponding cost functions. It incorporates the \textit{fast performance evaluation (FPE)} method to facilitate rapid and iterative updates to the generated cost function. Through this iterative process, $\mathrm{E^{2}CFD}$ aims to obtain the most suitable cost function for policy training, tailored to the specific tasks within the safety scenario. Experiments have proven that the performance of policies trained using this framework is superior to traditional safe reinforcement learning algorithms and policies trained with carefully designed cost functions.
LLaMoCo: Instruction Tuning of Large Language Models for Optimization Code Generation
Mar 05, 2024
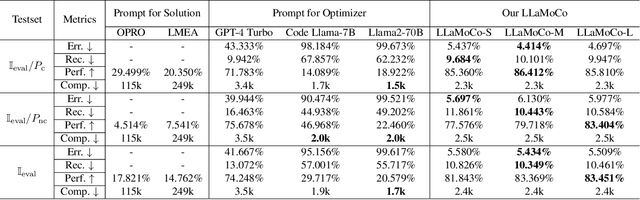
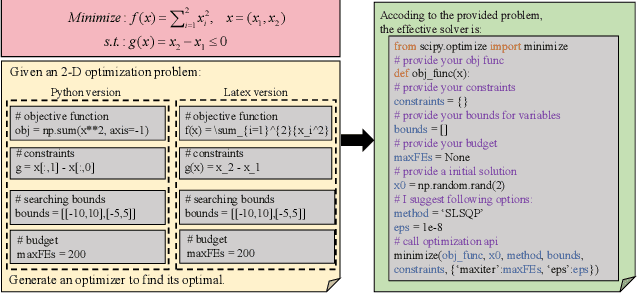
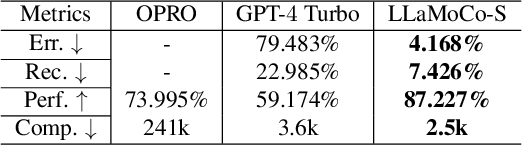
Recent research explores optimization using large language models (LLMs) by either iteratively seeking next-step solutions from LLMs or directly prompting LLMs for an optimizer. However, these approaches exhibit inherent limitations, including low operational efficiency, high sensitivity to prompt design, and a lack of domain-specific knowledge. We introduce LLaMoCo, the first instruction-tuning framework designed to adapt LLMs for solving optimization problems in a code-to-code manner. Specifically, we establish a comprehensive instruction set containing well-described problem prompts and effective optimization codes. We then develop a novel two-phase learning strategy that incorporates a contrastive learning-based warm-up procedure before the instruction-tuning phase to enhance the convergence behavior during model fine-tuning. The experiment results demonstrate that a CodeGen (350M) model fine-tuned by our LLaMoCo achieves superior optimization performance compared to GPT-4 Turbo and the other competitors across both synthetic and realistic problem sets. The fine-tuned model and the usage instructions are available at https://anonymous.4open.science/r/LLaMoCo-722A.
MetaBox: A Benchmark Platform for Meta-Black-Box Optimization with Reinforcement Learning
Oct 27, 2023Recently, Meta-Black-Box Optimization with Reinforcement Learning (MetaBBO-RL) has showcased the power of leveraging RL at the meta-level to mitigate manual fine-tuning of low-level black-box optimizers. However, this field is hindered by the lack of a unified benchmark. To fill this gap, we introduce MetaBox, the first benchmark platform expressly tailored for developing and evaluating MetaBBO-RL methods. MetaBox offers a flexible algorithmic template that allows users to effortlessly implement their unique designs within the platform. Moreover, it provides a broad spectrum of over 300 problem instances, collected from synthetic to realistic scenarios, and an extensive library of 19 baseline methods, including both traditional black-box optimizers and recent MetaBBO-RL methods. Besides, MetaBox introduces three standardized performance metrics, enabling a more thorough assessment of the methods. In a bid to illustrate the utility of MetaBox for facilitating rigorous evaluation and in-depth analysis, we carry out a wide-ranging benchmarking study on existing MetaBBO-RL methods. Our MetaBox is open-source and accessible at: https://github.com/GMC-DRL/MetaBox.