 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll Vehicles Can Lie: Efficient Adversarial Defense in Fully Untrusted-Vehicle Collaborative Perception via Pseudo-Random Bayesian Inference
Mar 09, 2026Collaborative perception (CP) enables multiple vehicles to augment their individual perception capacities through the exchange of feature-level sensory data. However, this fusion mechanism is inherently vulnerable to adversarial attacks, especially in fully untrusted-vehicle environments. Existing defense approaches often assume a trusted ego vehicle as a reference or incorporate additional binary classifiers. These assumptions limit their practicality in real-world deployments due to the questionable trustworthiness of ego vehicles, the requirement for real-time detection, and the need for generalizability across diverse scenarios. To address these challenges, we propose a novel Pseudo-Random Bayesian Inference (PRBI) framework, a first efficient defense method tailored for fully untrusted-vehicle CP. PRBI detects adversarial behavior by leveraging temporal perceptual discrepancies, using the reliable perception from the preceding frame as a dynamic reference. Additionally, it employs a pseudo-random grouping strategy that requires only two verifications per frame, while applying Bayesian inference to estimate both the number and identities of malicious vehicles. Theoretical analysis has proven the convergence and stability of the proposed PRBI framework. Extensive experiments show that PRBI requires only 2.5 verifications per frame on average, outperforming existing methods significantly, and restores detection precision to between 79.4% and 86.9% of pre-attack levels.
Send Less, Perceive More: Masked Quantized Point Cloud Communication for Loss-Tolerant Collaborative Perception
Feb 25, 2026Collaborative perception allows connected vehicles to overcome occlusions and limited viewpoints by sharing sensory information. However, existing approaches struggle to achieve high accuracy under strict bandwidth constraints and remain highly vulnerable to random transmission packet loss. We introduce QPoint2Comm, a quantized point-cloud communication framework that dramatically reduces bandwidth while preserving high-fidelity 3D information. Instead of transmitting intermediate features, QPoint2Comm directly communicates quantized point-cloud indices using a shared codebook, enabling efficient reconstruction with lower bandwidth than feature-based methods. To ensure robustness to possible communication packet loss, we employ a masked training strategy that simulates random packet loss, allowing the model to maintain strong performance even under severe transmission failures. In addition, a cascade attention fusion module is proposed to enhance multi-vehicle information integration. Extensive experiments on both simulated and real-world datasets demonstrate that QPoint2Comm sets a new state of the art in accuracy, communication efficiency, and resilience to packet loss.
Agentic Memory: Learning Unified Long-Term and Short-Term Memory Management for Large Language Model Agents
Jan 05, 2026Large language model (LLM) agents face fundamental limitations in long-horizon reasoning due to finite context windows, making effective memory management critical. Existing methods typically handle long-term memory (LTM) and short-term memory (STM) as separate components, relying on heuristics or auxiliary controllers, which limits adaptability and end-to-end optimization. In this paper, we propose Agentic Memory (AgeMem), a unified framework that integrates LTM and STM management directly into the agent's policy. AgeMem exposes memory operations as tool-based actions, enabling the LLM agent to autonomously decide what and when to store, retrieve, update, summarize, or discard information. To train such unified behaviors, we propose a three-stage progressive reinforcement learning strategy and design a step-wise GRPO to address sparse and discontinuous rewards induced by memory operations. Experiments on five long-horizon benchmarks demonstrate that AgeMem consistently outperforms strong memory-augmented baselines across multiple LLM backbones, achieving improved task performance, higher-quality long-term memory, and more efficient context usage.
A Structure-Agnostic Co-Tuning Framework for LLMs and SLMs in Cloud-Edge Systems
Nov 12, 2025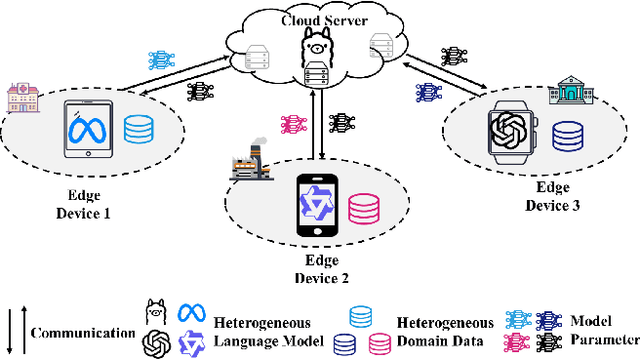
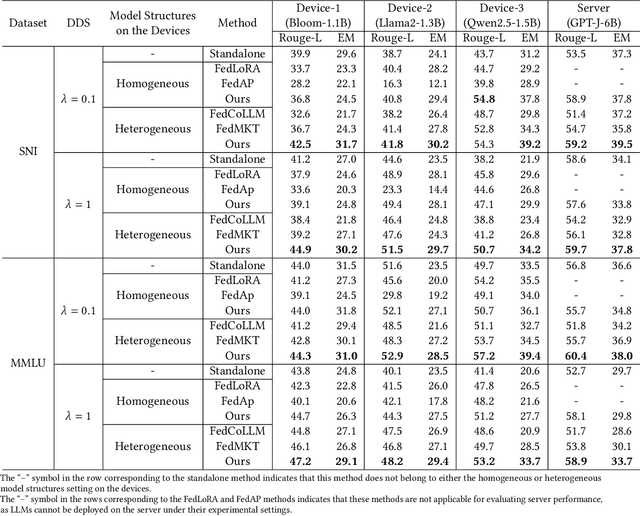
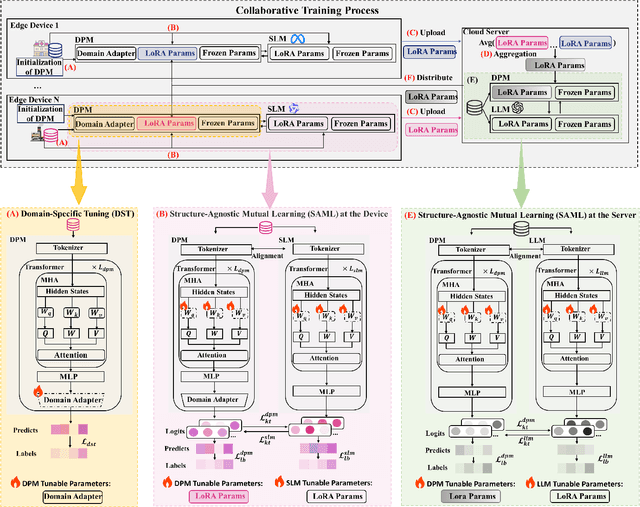
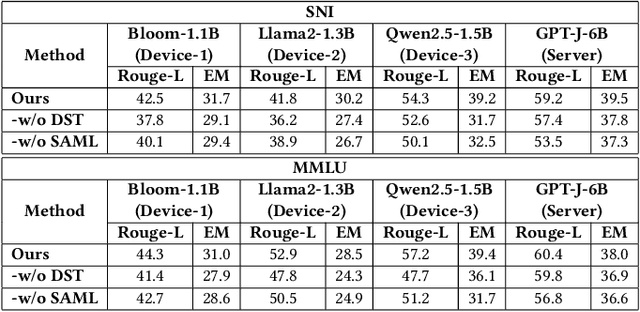
The surge in intelligent applications driven by large language models (LLMs) has made it increasingly difficult for bandwidth-limited cloud servers to process extensive LLM workloads in real time without compromising user data privacy. To solve these problems, recent research has focused on constructing cloud-edge consortia that integrate server-based LLM with small language models (SLMs) on mobile edge devices. Furthermore, designing collaborative training mechanisms within such consortia to enhance inference performance has emerged as a promising research direction. However, the cross-domain deployment of SLMs, coupled with structural heterogeneity in SLMs architectures, poses significant challenges to enhancing model performance. To this end, we propose Co-PLMs, a novel co-tuning framework for collaborative training of large and small language models, which integrates the process of structure-agnostic mutual learning to realize knowledge exchange between the heterogeneous language models. This framework employs distilled proxy models (DPMs) as bridges to enable collaborative training between the heterogeneous server-based LLM and on-device SLMs, while preserving the domain-specific insights of each device. The experimental results show that Co-PLMs outperform state-of-the-art methods, achieving average increases of 5.38% in Rouge-L and 4.88% in EM.
mmCooper: A Multi-agent Multi-stage Communication-efficient and Collaboration-robust Cooperative Perception Framework
Jan 21, 2025Collaborative perception significantly enhances individual vehicle perception performance through the exchange of sensory information among agents. However, real-world deployment faces challenges due to bandwidth constraints and inevitable calibration errors during information exchange. To address these issues, we propose mmCooper, a novel multi-agent, multi-stage, communication-efficient, and collaboration-robust cooperative perception framework. Our framework leverages a multi-stage collaboration strategy that dynamically and adaptively balances intermediate- and late-stage information to share among agents, enhancing perceptual performance while maintaining communication efficiency. To support robust collaboration despite potential misalignments and calibration errors, our framework captures multi-scale contextual information for robust fusion in the intermediate stage and calibrates the received detection results to improve accuracy in the late stage. We validate the effectiveness of mmCooper through extensive experiments on real-world and simulated datasets. The results demonstrate the superiority of our proposed framework and the effectiveness of each component.
$\mathrm{E^{2}CFD}$: Towards Effective and Efficient Cost Function Design for Safe Reinforcement Learning via Large Language Model
Jul 08, 2024Different classes of safe reinforcement learning algorithms have shown satisfactory performance in various types of safety requirement scenarios. However, the existing methods mainly address one or several classes of specific safety requirement scenario problems and cannot be applied to arbitrary safety requirement scenarios. In addition, the optimization objectives of existing reinforcement learning algorithms are misaligned with the task requirements. Based on the need to address these issues, we propose $\mathrm{E^{2}CFD}$, an effective and efficient cost function design framework. $\mathrm{E^{2}CFD}$ leverages the capabilities of a large language model (LLM) to comprehend various safety scenarios and generate corresponding cost functions. It incorporates the \textit{fast performance evaluation (FPE)} method to facilitate rapid and iterative updates to the generated cost function. Through this iterative process, $\mathrm{E^{2}CFD}$ aims to obtain the most suitable cost function for policy training, tailored to the specific tasks within the safety scenario. Experiments have proven that the performance of policies trained using this framework is superior to traditional safe reinforcement learning algorithms and policies trained with carefully designed cost functions.
Detecting Backdoors During the Inference Stage Based on Corruption Robustness Consistency
Mar 27, 2023



Deep neural networks are proven to be vulnerable to backdoor attacks. Detecting the trigger samples during the inference stage, i.e., the test-time trigger sample detection, can prevent the backdoor from being triggered. However, existing detection methods often require the defenders to have high accessibility to victim models, extra clean data, or knowledge about the appearance of backdoor triggers, limiting their practicality. In this paper, we propose the test-time corruption robustness consistency evaluation (TeCo), a novel test-time trigger sample detection method that only needs the hard-label outputs of the victim models without any extra information. Our journey begins with the intriguing observation that the backdoor-infected models have similar performance across different image corruptions for the clean images, but perform discrepantly for the trigger samples. Based on this phenomenon, we design TeCo to evaluate test-time robustness consistency by calculating the deviation of severity that leads to predictions' transition across different corruptions. Extensive experiments demonstrate that compared with state-of-the-art defenses, which even require either certain information about the trigger types or accessibility of clean data, TeCo outperforms them on different backdoor attacks, datasets, and model architectures, enjoying a higher AUROC by 10% and 5 times of stability.
Completing point cloud from few points by Wasserstein GAN and Transformers
Nov 23, 2022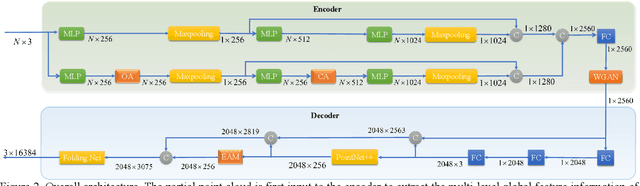
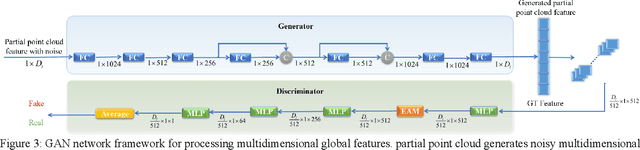
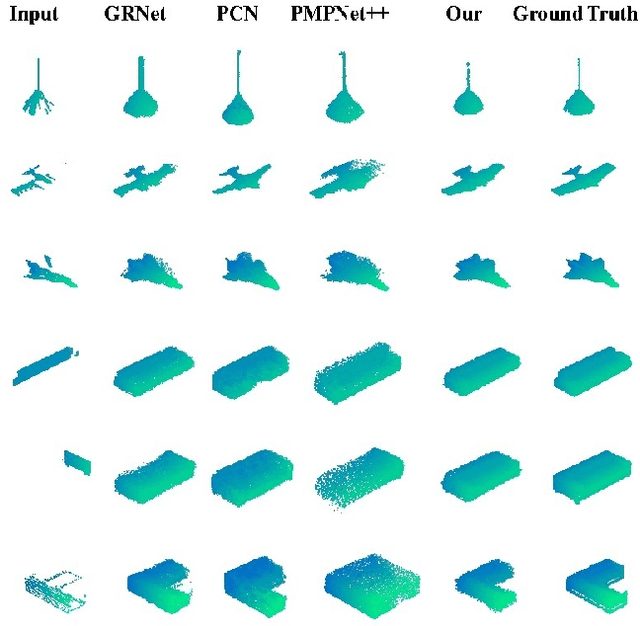
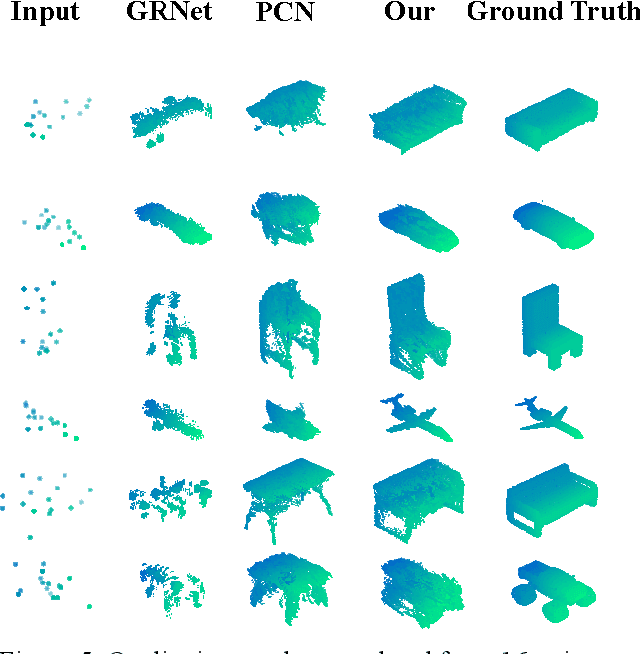
In many vision and robotics applications, it is common that the captured objects are represented by very few points. Most of the existing completion methods are designed for partial point clouds with many points, and they perform poorly or even fail completely in the case of few points. However, due to the lack of detail information, completing objects from few points faces a huge challenge. Inspired by the successful applications of GAN and Transformers in the image-based vision task, we introduce GAN and Transformer techniques to address the above problem. Firstly, the end-to-end encoder-decoder network with Transformers and the Wasserstein GAN with Transformer are pre-trained, and then the overall network is fine-tuned. Experimental results on the ShapeNet dataset show that our method can not only improve the completion performance for many input points, but also keep stable for few input points. Our source code is available at https://github.com/WxfQjh/Stability-point-recovery.git.
Protecting Facial Privacy: Generating Adversarial Identity Masks via Style-robust Makeup Transfer
Mar 28, 2022
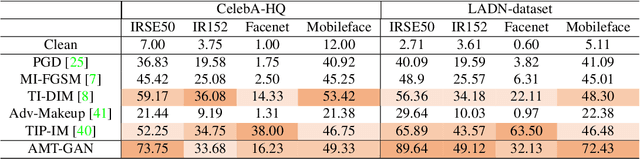
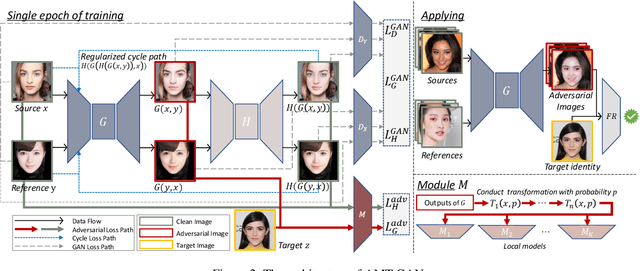
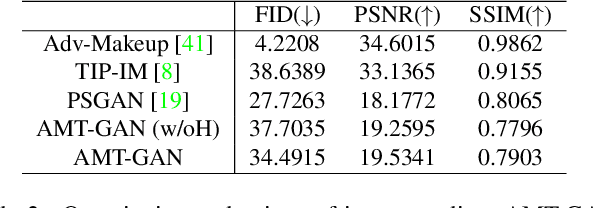
While deep face recognition (FR) systems have shown amazing performance in identification and verification, they also arouse privacy concerns for their excessive surveillance on users, especially for public face images widely spread on social networks. Recently, some studies adopt adversarial examples to protect photos from being identified by unauthorized face recognition systems. However, existing methods of generating adversarial face images suffer from many limitations, such as awkward visual, white-box setting, weak transferability, making them difficult to be applied to protect face privacy in reality. In this paper, we propose adversarial makeup transfer GAN (AMT-GAN), a novel face protection method aiming at constructing adversarial face images that preserve stronger black-box transferability and better visual quality simultaneously. AMT-GAN leverages generative adversarial networks (GAN) to synthesize adversarial face images with makeup transferred from reference images. In particular, we introduce a new regularization module along with a joint training strategy to reconcile the conflicts between the adversarial noises and the cycle consistence loss in makeup transfer, achieving a desirable balance between the attack strength and visual changes. Extensive experiments verify that compared with state of the arts, AMT-GAN can not only preserve a comfortable visual quality, but also achieve a higher attack success rate over commercial FR APIs, including Face++, Aliyun, and Microsoft.
DynSTGAT: Dynamic Spatial-Temporal Graph Attention Network for Traffic Signal Control
Sep 12, 2021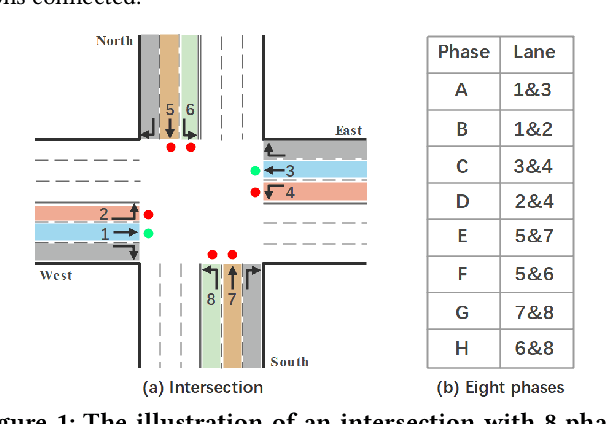
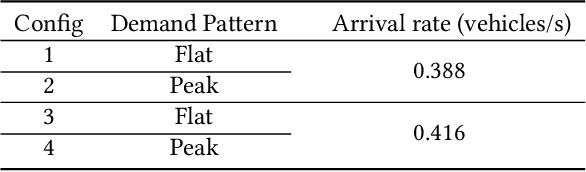
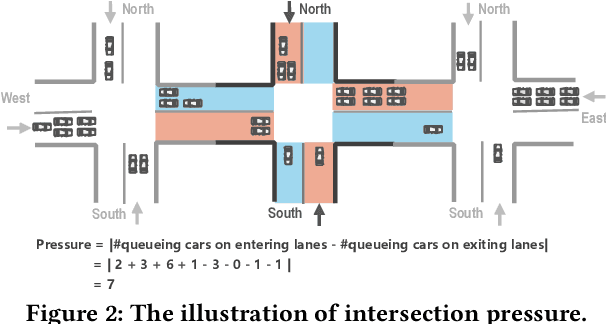

Adaptive traffic signal control plays a significant role in the construction of smart cities. This task is challenging because of many essential factors, such as cooperation among neighboring intersections and dynamic traffic scenarios. First, to facilitate cooperation of traffic signals, existing work adopts graph neural networks to incorporate the temporal and spatial influences of the surrounding intersections into the target intersection, where spatial-temporal information is used separately. However, one drawback of these methods is that the spatial-temporal correlations are not adequately exploited to obtain a better control scheme. Second, in a dynamic traffic environment, the historical state of the intersection is also critical for predicting future signal switching. Previous work mainly solves this problem using the current intersection's state, neglecting the fact that traffic flow is continuously changing both spatially and temporally and does not handle the historical state. In this paper, we propose a novel neural network framework named DynSTGAT, which integrates dynamic historical state into a new spatial-temporal graph attention network to address the above two problems. More specifically, our DynSTGAT model employs a novel multi-head graph attention mechanism, which aims to adequately exploit the joint relations of spatial-temporal information. Then, to efficiently utilize the historical state information of the intersection, we design a sequence model with the temporal convolutional network (TCN) to capture the historical information and further merge it with the spatial information to improve its performance. Extensive experiments conducted in the multi-intersection scenario on synthetic data and real-world data confirm that our method can achieve superior performance in travel time and throughput against the state-of-the-art methods.