 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompleting point cloud from few points by Wasserstein GAN and Transformers
Nov 23, 2022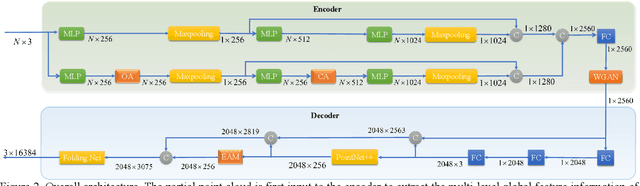
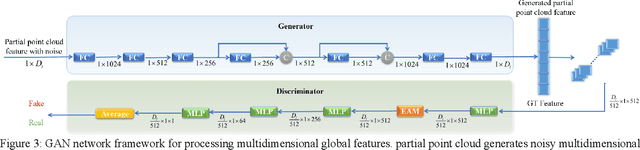
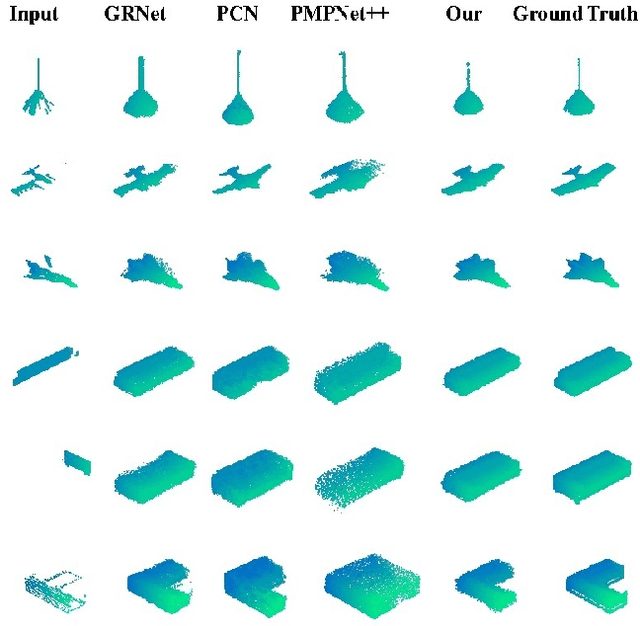
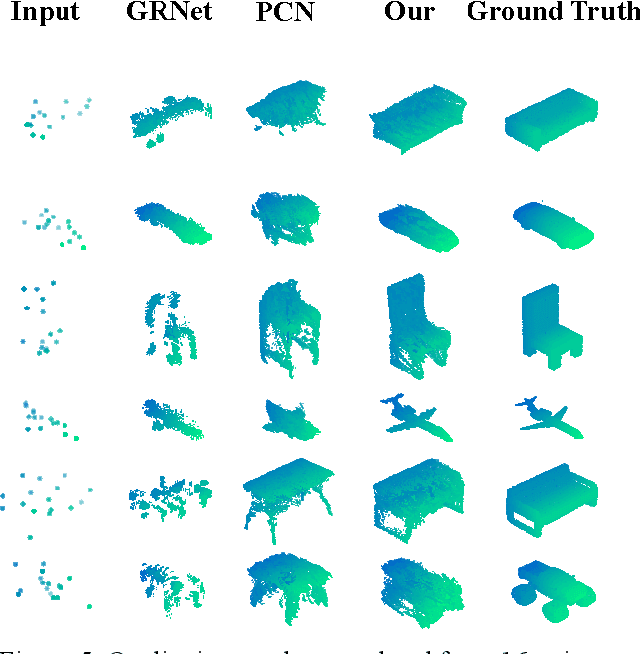
In many vision and robotics applications, it is common that the captured objects are represented by very few points. Most of the existing completion methods are designed for partial point clouds with many points, and they perform poorly or even fail completely in the case of few points. However, due to the lack of detail information, completing objects from few points faces a huge challenge. Inspired by the successful applications of GAN and Transformers in the image-based vision task, we introduce GAN and Transformer techniques to address the above problem. Firstly, the end-to-end encoder-decoder network with Transformers and the Wasserstein GAN with Transformer are pre-trained, and then the overall network is fine-tuned. Experimental results on the ShapeNet dataset show that our method can not only improve the completion performance for many input points, but also keep stable for few input points. Our source code is available at https://github.com/WxfQjh/Stability-point-recovery.git.
Learning fast and agile quadrupedal locomotion over complex terrain
Jul 02, 2022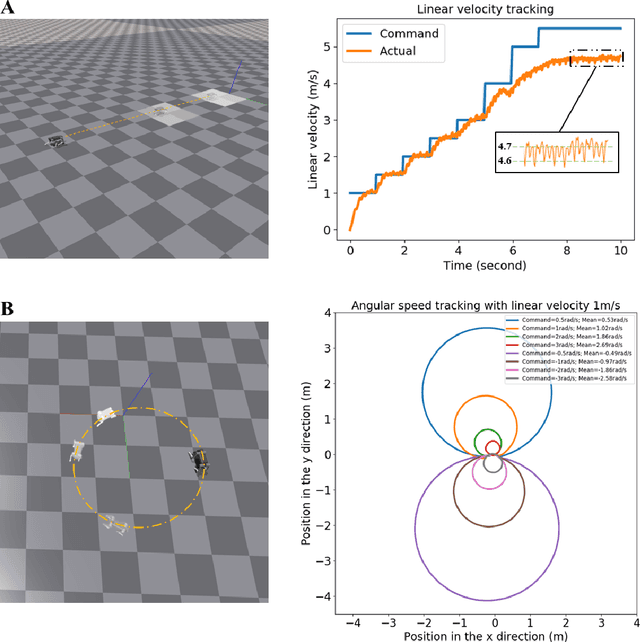



In this paper, we propose a robust controller that achieves natural and stably fast locomotion on a real blind quadruped robot. With only proprioceptive information, the quadruped robot can move at a maximum speed of 10 times its body length, and has the ability to pass through various complex terrains. The controller is trained in the simulation environment by model-free reinforcement learning. In this paper, the proposed loose neighborhood control architecture not only guarantees the learning rate, but also obtains an action network that is easy to transfer to a real quadruped robot. Our research finds that there is a problem of data symmetry loss during training, which leads to unbalanced performance of the learned controller on the left-right symmetric quadruped robot structure, and proposes a mirror-world neural network to solve the performance problem. The learned controller composed of the mirror-world network can make the robot achieve excellent anti-disturbance ability. No specific human knowledge such as a foot trajectory generator are used in the training architecture. The learned controller can coordinate the robot's gait frequency and locomotion speed, and the locomotion pattern is more natural and reasonable than the artificially designed controller. Our controller has excellent anti-disturbance performance, and has good generalization ability to reach locomotion speeds it has never learned and traverse terrains it has never seen before.
Double-Barreled Question Detection at Momentive
Feb 12, 2022
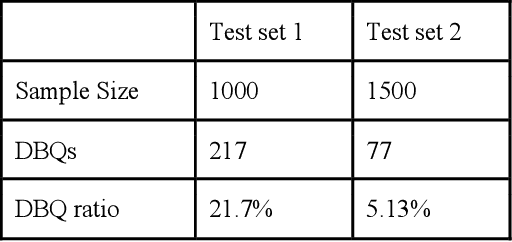
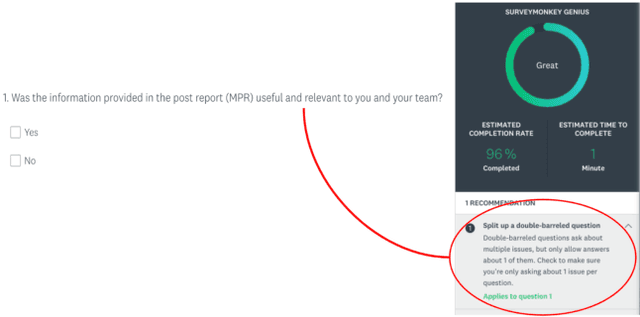
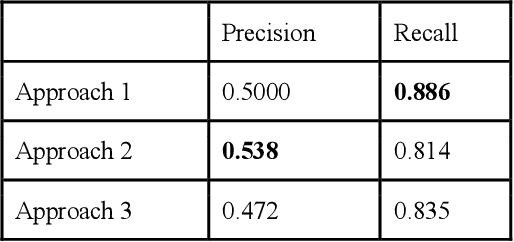
Momentive offers solutions in market research, customer experience, and enterprise feedback. The technology is gleaned from the billions of real responses to questions asked on the platform. However, people may create biased questions. A double-barreled question (DBQ) is a common type of biased question that asks two aspects in one question. For example, "Do you agree with the statement: The food is yummy, and the service is great.". This DBQ confuses survey respondents because there are two parts in a question. DBQs impact both the survey respondents and the survey owners. Momentive aims to detect DBQs and recommend survey creators to make a change towards gathering high quality unbiased survey data. Previous research work has suggested detecting DBQs by checking the existence of grammatical conjunction. While this is a simple rule-based approach, this method is error-prone because conjunctions can also exist in properly constructed questions. We present an end-to-end machine learning approach for DBQ classification in this work. We handled this imbalanced data using active learning, and compared state-of-the-art embedding algorithms to transform text data into vectors. Furthermore, we proposed a model interpretation technique propagating the vector-level SHAP values to a SHAP value for each word in the questions. We concluded that the word2vec subword embedding with maximum pooling is the optimal word embedding representation in terms of precision and running time in the offline experiments using the survey data at Momentive. The A/B test and production metrics indicate that this model brings a positive change to the business. To the best of our knowledge, this is the first machine learning framework for DBQ detection, and it successfully differentiates Momentive from the competitors. We hope our work sheds light on machine learning approaches for bias question detection.
Deep Reinforcement Learning with Quantum-inspired Experience Replay
Jan 06, 2021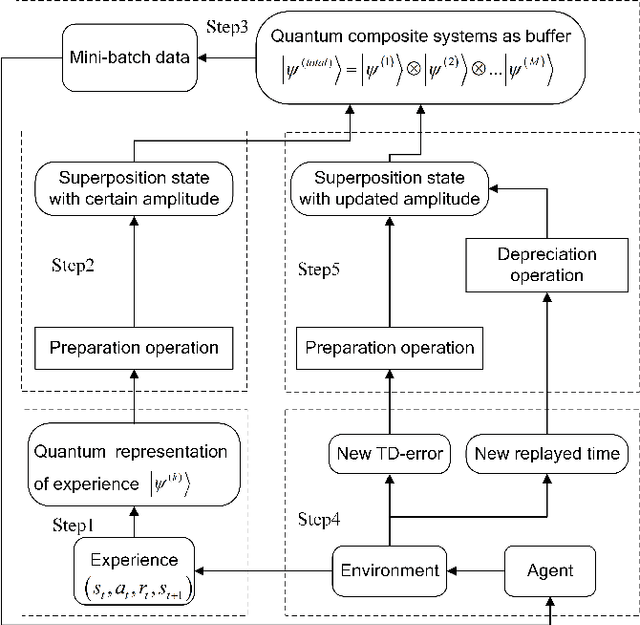
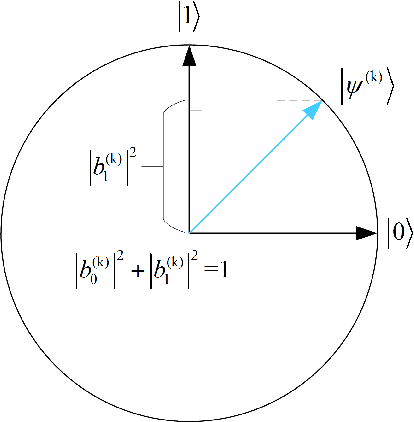
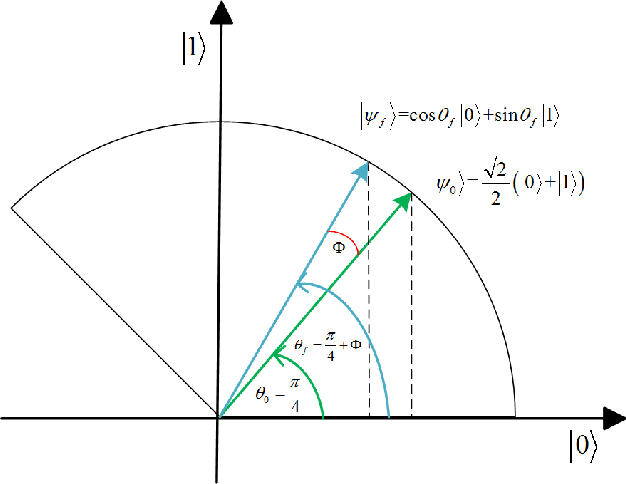
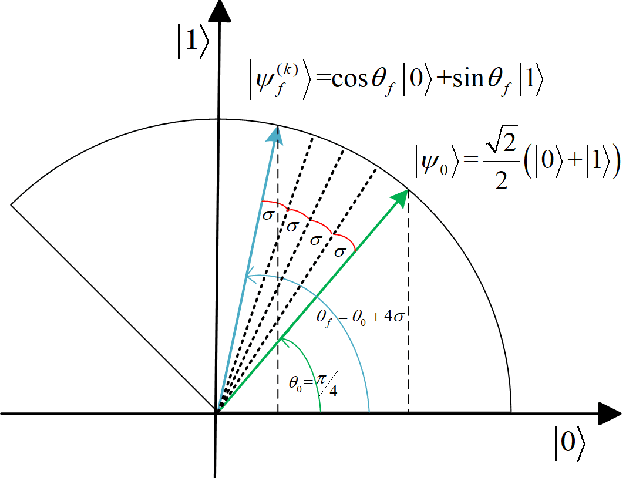
In this paper, a novel training paradigm inspired by quantum computation is proposed for deep reinforcement learning (DRL) with experience replay. In contrast to traditional experience replay mechanism in DRL, the proposed deep reinforcement learning with quantum-inspired experience replay (DRL-QER) adaptively chooses experiences from the replay buffer according to the complexity and the replayed times of each experience (also called transition), to achieve a balance between exploration and exploitation. In DRL-QER, transitions are first formulated in quantum representations, and then the preparation operation and the depreciation operation are performed on the transitions. In this progress, the preparation operation reflects the relationship between the temporal difference errors (TD-errors) and the importance of the experiences, while the depreciation operation is taken into account to ensure the diversity of the transitions. The experimental results on Atari 2600 games show that DRL-QER outperforms state-of-the-art algorithms such as DRL-PER and DCRL on most of these games with improved training efficiency, and is also applicable to such memory-based DRL approaches as double network and dueling network.