 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Reveals What to Cache: Profiling-Based Feature Reuse for Video Diffusion Models
Apr 04, 2025



Recent advances in diffusion models have demonstrated remarkable capabilities in video generation. However, the computational intensity remains a significant challenge for practical applications. While feature caching has been proposed to reduce the computational burden of diffusion models, existing methods typically overlook the heterogeneous significance of individual blocks, resulting in suboptimal reuse and degraded output quality. To this end, we address this gap by introducing ProfilingDiT, a novel adaptive caching strategy that explicitly disentangles foreground and background-focused blocks. Through a systematic analysis of attention distributions in diffusion models, we reveal a key observation: 1) Most layers exhibit a consistent preference for either foreground or background regions. 2) Predicted noise shows low inter-step similarity initially, which stabilizes as denoising progresses. This finding inspires us to formulate a selective caching strategy that preserves full computation for dynamic foreground elements while efficiently caching static background features. Our approach substantially reduces computational overhead while preserving visual fidelity. Extensive experiments demonstrate that our framework achieves significant acceleration (e.g., 2.01 times speedup for Wan2.1) while maintaining visual fidelity across comprehensive quality metrics, establishing a viable method for efficient video generation.
Temporal Regularization Makes Your Video Generator Stronger
Mar 19, 2025Temporal quality is a critical aspect of video generation, as it ensures consistent motion and realistic dynamics across frames. However, achieving high temporal coherence and diversity remains challenging. In this work, we explore temporal augmentation in video generation for the first time, and introduce FluxFlow for initial investigation, a strategy designed to enhance temporal quality. Operating at the data level, FluxFlow applies controlled temporal perturbations without requiring architectural modifications. Extensive experiments on UCF-101 and VBench benchmarks demonstrate that FluxFlow significantly improves temporal coherence and diversity across various video generation models, including U-Net, DiT, and AR-based architectures, while preserving spatial fidelity. These findings highlight the potential of temporal augmentation as a simple yet effective approach to advancing video generation quality.
LightGen: Efficient Image Generation through Knowledge Distillation and Direct Preference Optimization
Mar 11, 2025



Recent advances in text-to-image generation have primarily relied on extensive datasets and parameter-heavy architectures. These requirements severely limit accessibility for researchers and practitioners who lack substantial computational resources. In this paper, we introduce \model, an efficient training paradigm for image generation models that uses knowledge distillation (KD) and Direct Preference Optimization (DPO). Drawing inspiration from the success of data KD techniques widely adopted in Multi-Modal Large Language Models (MLLMs), LightGen distills knowledge from state-of-the-art (SOTA) text-to-image models into a compact Masked Autoregressive (MAR) architecture with only $0.7B$ parameters. Using a compact synthetic dataset of just $2M$ high-quality images generated from varied captions, we demonstrate that data diversity significantly outweighs data volume in determining model performance. This strategy dramatically reduces computational demands and reduces pre-training time from potentially thousands of GPU-days to merely 88 GPU-days. Furthermore, to address the inherent shortcomings of synthetic data, particularly poor high-frequency details and spatial inaccuracies, we integrate the DPO technique that refines image fidelity and positional accuracy. Comprehensive experiments confirm that LightGen achieves image generation quality comparable to SOTA models while significantly reducing computational resources and expanding accessibility for resource-constrained environments. Code is available at https://github.com/XianfengWu01/LightGen
FSC: Few-point Shape Completion
Mar 13, 2024
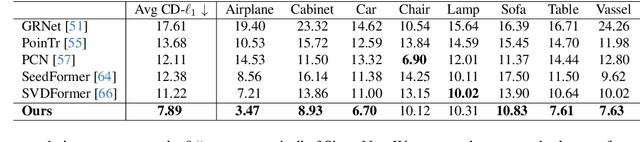

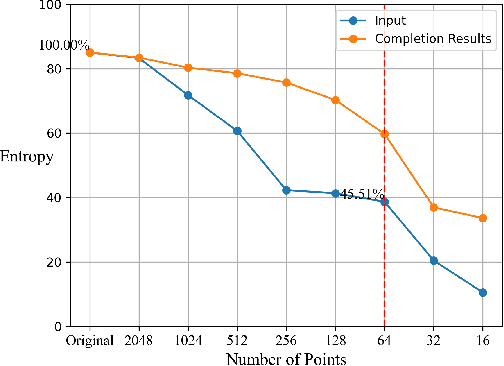
While previous studies have demonstrated successful 3D object shape completion with a sufficient number of points, they often fail in scenarios when a few points, e.g. tens of points, are observed. Surprisingly, via entropy analysis, we find that even a few points, e.g. 64 points, could retain substantial information to help recover the 3D shape of the object. To address the challenge of shape completion with very sparse point clouds, we then propose Few-point Shape Completion (FSC) model, which contains a novel dual-branch feature extractor for handling extremely sparse inputs, coupled with an extensive branch for maximal point utilization with a saliency branch for dynamic importance assignment. This model is further bolstered by a two-stage revision network that refines both the extracted features and the decoder output, enhancing the detail and authenticity of the completed point cloud. Our experiments demonstrate the feasibility of recovering 3D shapes from a few points. The proposed Few-point Shape Completion (FSC) model outperforms previous methods on both few-point inputs and many-point inputs, and shows good generalizability to different object categories.
Completing point cloud from few points by Wasserstein GAN and Transformers
Nov 23, 2022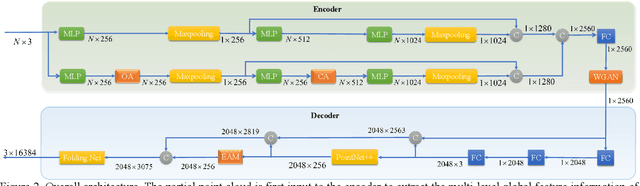
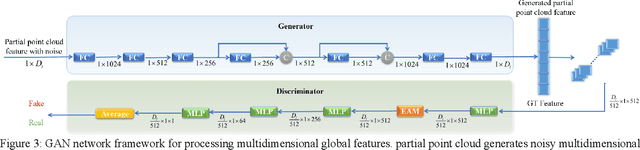
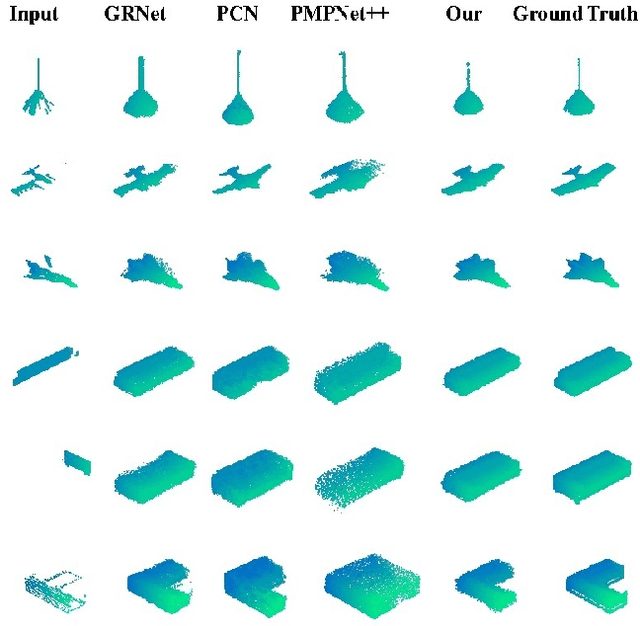
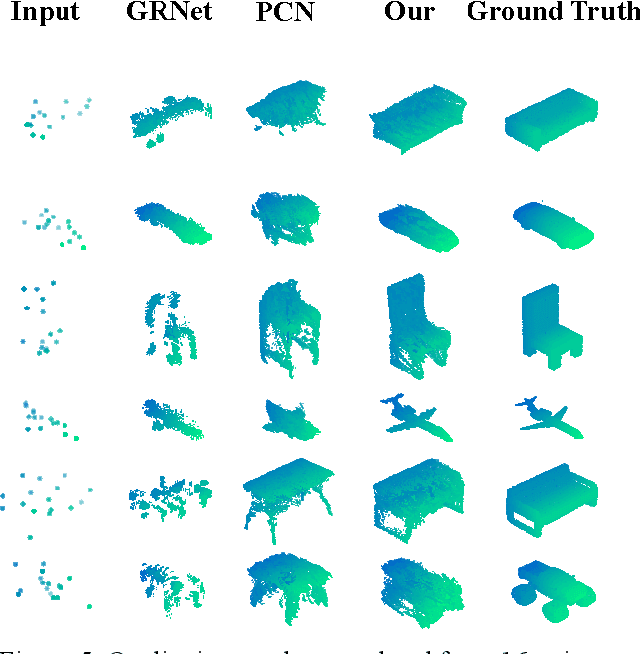
In many vision and robotics applications, it is common that the captured objects are represented by very few points. Most of the existing completion methods are designed for partial point clouds with many points, and they perform poorly or even fail completely in the case of few points. However, due to the lack of detail information, completing objects from few points faces a huge challenge. Inspired by the successful applications of GAN and Transformers in the image-based vision task, we introduce GAN and Transformer techniques to address the above problem. Firstly, the end-to-end encoder-decoder network with Transformers and the Wasserstein GAN with Transformer are pre-trained, and then the overall network is fine-tuned. Experimental results on the ShapeNet dataset show that our method can not only improve the completion performance for many input points, but also keep stable for few input points. Our source code is available at https://github.com/WxfQjh/Stability-point-recovery.git.