 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopViT: Scaling Visual ARC with Looped Transformers
Feb 02, 2026Recent advances in visual reasoning have leveraged vision transformers to tackle the ARC-AGI benchmark. However, we argue that the feed-forward architecture, where computational depth is strictly bound to parameter size, falls short of capturing the iterative, algorithmic nature of human induction. In this work, we propose a recursive architecture called Loop-ViT, which decouples reasoning depth from model capacity through weight-tied recurrence. Loop-ViT iterates a weight-tied Hybrid Block, combining local convolutions and global attention, to form a latent chain of thought. Crucially, we introduce a parameter-free Dynamic Exit mechanism based on predictive entropy: the model halts inference when its internal state ``crystallizes" into a low-uncertainty attractor. Empirical results on the ARC-AGI-1 benchmark validate this perspective: our 18M model achieves 65.8% accuracy, outperforming massive 73M-parameter ensembles. These findings demonstrate that adaptive iterative computation offers a far more efficient scaling axis for visual reasoning than simply increasing network width. The code is available at https://github.com/WenjieShu/LoopViT.
Show, Don't Tell: Morphing Latent Reasoning into Image Generation
Feb 02, 2026Text-to-image (T2I) generation has achieved remarkable progress, yet existing methods often lack the ability to dynamically reason and refine during generation--a hallmark of human creativity. Current reasoning-augmented paradigms most rely on explicit thought processes, where intermediate reasoning is decoded into discrete text at fixed steps with frequent image decoding and re-encoding, leading to inefficiencies, information loss, and cognitive mismatches. To bridge this gap, we introduce LatentMorph, a novel framework that seamlessly integrates implicit latent reasoning into the T2I generation process. At its core, LatentMorph introduces four lightweight components: (i) a condenser for summarizing intermediate generation states into compact visual memory, (ii) a translator for converting latent thoughts into actionable guidance, (iii) a shaper for dynamically steering next image token predictions, and (iv) an RL-trained invoker for adaptively determining when to invoke reasoning. By performing reasoning entirely in continuous latent spaces, LatentMorph avoids the bottlenecks of explicit reasoning and enables more adaptive self-refinement. Extensive experiments demonstrate that LatentMorph (I) enhances the base model Janus-Pro by $16\%$ on GenEval and $25\%$ on T2I-CompBench; (II) outperforms explicit paradigms (e.g., TwiG) by $15\%$ and $11\%$ on abstract reasoning tasks like WISE and IPV-Txt, (III) while reducing inference time by $44\%$ and token consumption by $51\%$; and (IV) exhibits $71\%$ cognitive alignment with human intuition on reasoning invocation.
A4-Agent: An Agentic Framework for Zero-Shot Affordance Reasoning
Dec 16, 2025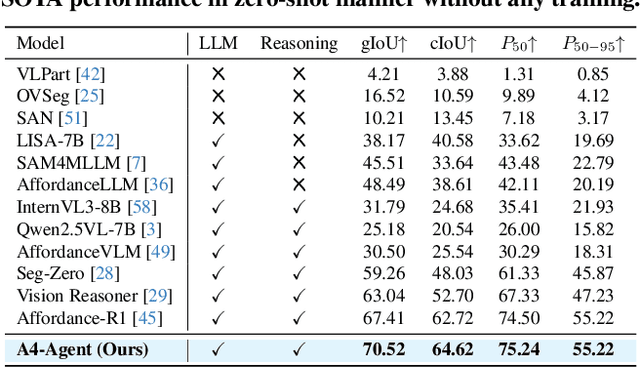
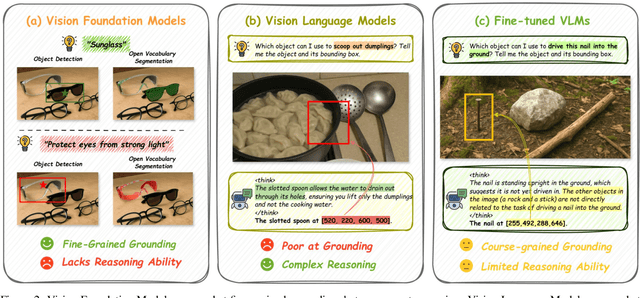
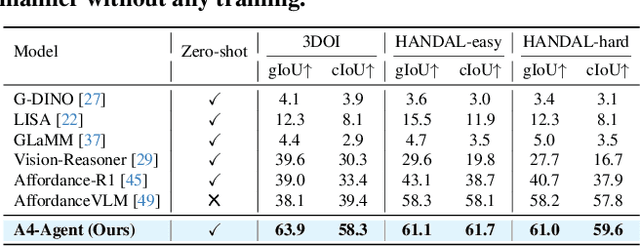
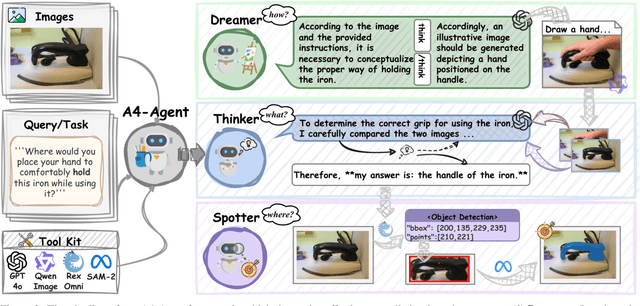
Affordance prediction, which identifies interaction regions on objects based on language instructions, is critical for embodied AI. Prevailing end-to-end models couple high-level reasoning and low-level grounding into a single monolithic pipeline and rely on training over annotated datasets, which leads to poor generalization on novel objects and unseen environments. In this paper, we move beyond this paradigm by proposing A4-Agent, a training-free agentic framework that decouples affordance prediction into a three-stage pipeline. Our framework coordinates specialized foundation models at test time: (1) a $\textbf{Dreamer}$ that employs generative models to visualize $\textit{how}$ an interaction would look; (2) a $\textbf{Thinker}$ that utilizes large vision-language models to decide $\textit{what}$ object part to interact with; and (3) a $\textbf{Spotter}$ that orchestrates vision foundation models to precisely locate $\textit{where}$ the interaction area is. By leveraging the complementary strengths of pre-trained models without any task-specific fine-tuning, our zero-shot framework significantly outperforms state-of-the-art supervised methods across multiple benchmarks and demonstrates robust generalization to real-world settings.
TiViBench: Benchmarking Think-in-Video Reasoning for Video Generative Models
Nov 17, 2025The rapid evolution of video generative models has shifted their focus from producing visually plausible outputs to tackling tasks requiring physical plausibility and logical consistency. However, despite recent breakthroughs such as Veo 3's chain-of-frames reasoning, it remains unclear whether these models can exhibit reasoning capabilities similar to large language models (LLMs). Existing benchmarks predominantly evaluate visual fidelity and temporal coherence, failing to capture higher-order reasoning abilities. To bridge this gap, we propose TiViBench, a hierarchical benchmark specifically designed to evaluate the reasoning capabilities of image-to-video (I2V) generation models. TiViBench systematically assesses reasoning across four dimensions: i) Structural Reasoning & Search, ii) Spatial & Visual Pattern Reasoning, iii) Symbolic & Logical Reasoning, and iv) Action Planning & Task Execution, spanning 24 diverse task scenarios across 3 difficulty levels. Through extensive evaluations, we show that commercial models (e.g., Sora 2, Veo 3.1) demonstrate stronger reasoning potential, while open-source models reveal untapped potential that remains hindered by limited training scale and data diversity. To further unlock this potential, we introduce VideoTPO, a simple yet effective test-time strategy inspired by preference optimization. By performing LLM self-analysis on generated candidates to identify strengths and weaknesses, VideoTPO significantly enhances reasoning performance without requiring additional training, data, or reward models. Together, TiViBench and VideoTPO pave the way for evaluating and advancing reasoning in video generation models, setting a foundation for future research in this emerging field.
Temporal Regularization Makes Your Video Generator Stronger
Mar 19, 2025Temporal quality is a critical aspect of video generation, as it ensures consistent motion and realistic dynamics across frames. However, achieving high temporal coherence and diversity remains challenging. In this work, we explore temporal augmentation in video generation for the first time, and introduce FluxFlow for initial investigation, a strategy designed to enhance temporal quality. Operating at the data level, FluxFlow applies controlled temporal perturbations without requiring architectural modifications. Extensive experiments on UCF-101 and VBench benchmarks demonstrate that FluxFlow significantly improves temporal coherence and diversity across various video generation models, including U-Net, DiT, and AR-based architectures, while preserving spatial fidelity. These findings highlight the potential of temporal augmentation as a simple yet effective approach to advancing video generation quality.
LightGen: Efficient Image Generation through Knowledge Distillation and Direct Preference Optimization
Mar 11, 2025



Recent advances in text-to-image generation have primarily relied on extensive datasets and parameter-heavy architectures. These requirements severely limit accessibility for researchers and practitioners who lack substantial computational resources. In this paper, we introduce \model, an efficient training paradigm for image generation models that uses knowledge distillation (KD) and Direct Preference Optimization (DPO). Drawing inspiration from the success of data KD techniques widely adopted in Multi-Modal Large Language Models (MLLMs), LightGen distills knowledge from state-of-the-art (SOTA) text-to-image models into a compact Masked Autoregressive (MAR) architecture with only $0.7B$ parameters. Using a compact synthetic dataset of just $2M$ high-quality images generated from varied captions, we demonstrate that data diversity significantly outweighs data volume in determining model performance. This strategy dramatically reduces computational demands and reduces pre-training time from potentially thousands of GPU-days to merely 88 GPU-days. Furthermore, to address the inherent shortcomings of synthetic data, particularly poor high-frequency details and spatial inaccuracies, we integrate the DPO technique that refines image fidelity and positional accuracy. Comprehensive experiments confirm that LightGen achieves image generation quality comparable to SOTA models while significantly reducing computational resources and expanding accessibility for resource-constrained environments. Code is available at https://github.com/XianfengWu01/LightGen